




本文对复旦大学和星环科技联合编写的2024 ICDE入选论文《PURPLE: Making a Large Language Model a Better SQL Writer》进行解读,文共5089字,预计阅读需要20至30分钟。
在数据驱动的時代,自然语言到SQL的转换技术意义重大。PURPLE创新性地利用检索增强大型语言模型(LLM)的SQL生成能力,通过检索包含必要逻辑操作符组合的示例,显著提升了LLM在NL2SQL任务上的性能,为数据查询与分析领域带来了新的突破。
1.数据管理与分析的重要性
在当今数字化时代,数据管理与分析对于企业和社会的发展至关重要。随着数据量的不断增长,如何高效地从海量数据中提取有价值的信息成为了一个关键问题。传统的数据库管理系统(DBMS)虽然功能强大,但需要用户具备专业的SQL知识,这限制了许多非技术背景用户的数据分析能力。
2.自然语言到SQL(NL2SQL)的转换技术
NL2SQL技术的出现为解决这一问题提供了可能。它允许用户通过自然语言的方式查询数据库,无需掌握复杂的SQL语法。这一技术的核心挑战在于如何准确地将自然语言查询转换为正确的SQL语句,涉及到自然语言处理(NLP)和数据库查询语言的结合。
3.大型语言模型(LLM)的应用
LLM在NLP领域展现出了巨大的潜力。经过广泛语料库训练的LLM具有强大的自然语言理解能力,能够初步解析用户意图并生成相应的SQL查询语句。然而,目前的LLM在生成SQL时存在一些问题,尤其是在处理复杂的逻辑操作符组合时容易出错。
1.架构概览
PURPLE是一种创新的NL2SQL方法,通过检索包含必要逻辑操作符组合的示例来增强大型语言模型(LLM)的SQL生成能力。其架构主要包括以下几个模块:
模式修剪模块:缩小数据库信息范围,去除与当前自然语言查询无关的表和列。
骨架预测模块:根据修剪后的模式和自然语言查询,预测所需的SQL骨架,即逻辑操作符组合知识。
示例选择模块:检索与预测骨架匹配的示例,形成提示。
数据库适配模块:检测并修复LLM生成的SQL中的幻觉错误,确保输出的SQL符合特定数据库模式和SQL方言。
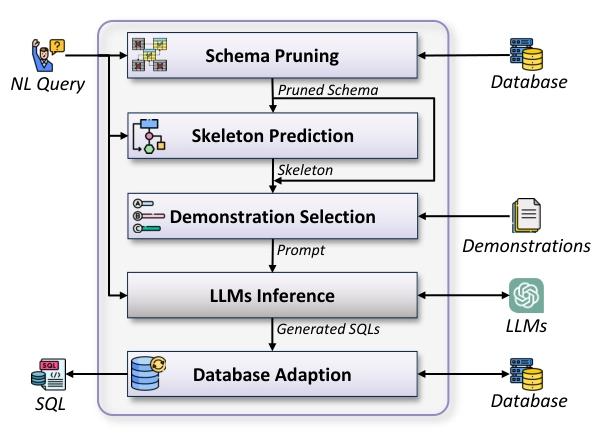
PURPLE概述
2.模式修剪
模式修剪模块根据自然语言查询和数据库模式,决定哪些表或列是目标SQL所需的。其主要步骤包括:
 模式修剪
模式修剪
2.1表和列的相关性预测
模式修剪模块采用基于训练有素的分类器的策略,旨在保留关键表或列,同时保持数据库信息简洁。具体来说,使用RESDSQL的模式排名模块作为基础,输入结构为自然语言查询、表及其列等信息。分类器预测每个表或列是否与问题相关,通过阈值τp筛选出相关表和列。
2.2模式修剪策略
进一步采用Steiner Tree Problem模型,将模式修剪任务建模为寻找包含所有相关表的最小连通子图,确保保留相关且连通的表,提高效率。这种策略不仅减少了LLM处理的信息量,还确保了数据库模式的完整性和连通性。
3.骨架预测
骨架预测模块检测NL2SQL任务所需的逻辑操作符组合知识。其工作原理如下:
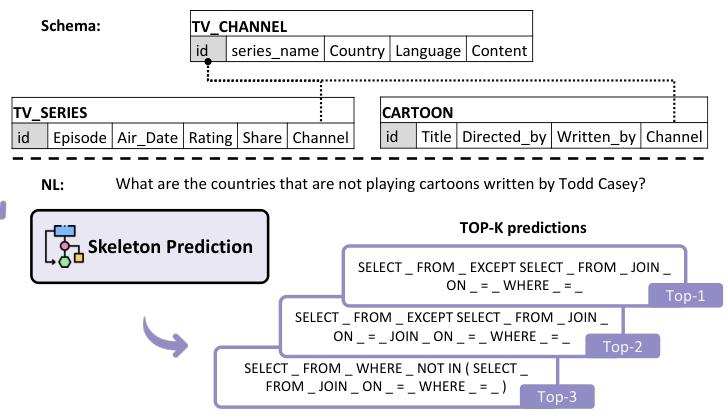
骨架预测
3.1模型选择与训练
骨架预测模块使用经过骨架生成任务微调的T5-3B模型进行预测。训练过程中,将目标SQL中的数据库特定实体替换为下划线,生成骨架。这种训练方式使得模型能够专注于逻辑操作符组合的预测,而忽略数据库特定的细节。
3.2预测方法
通过束搜索获取前k个预测骨架,确保高召回率。束搜索是一种常用的解码策略,能够在生成过程中保持多个候选结果,最终选择概率最高的结果。这种方法不仅提高了预测的准确性,还增加了结果的多样性。
4.示例选择
示例选择是PURPLE的核心,其目标是检索包含必要逻辑操作符组合的示例。主要步骤包括:
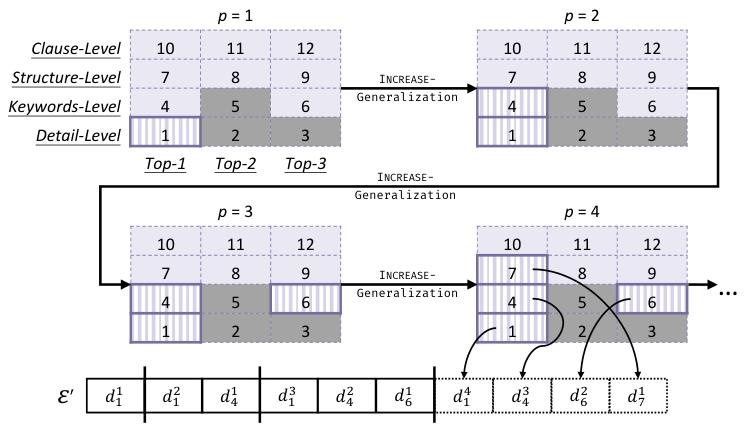
示例选择
四层抽象层次的自动机框架:采用四层抽象层次的自动机框架建模SQL组合知识,包括Detail-Level、Keywords-Level、Structure-Level和Clause-Level。每一层抽象屏蔽更多细节,聚焦更粗粒度的组合。例如,图6展示了骨架的自动机抽象示例。通过这种多层次的抽象,PURPLE能够更灵活地匹配和检索包含必要逻辑操作符组合的示例。
匹配与检索:通过匹配预测骨架与自动机状态序列,检索出包含相关组合知识的示例。算法1详细描述了示例选择过程,优先选择预测概率高且抽象层次低的匹配项,同时考虑更高抽象层次的匹配以增强泛化能力。
5.数据库适配
数据库适配模块通过分析LLM输出,识别并修复常见错误,确保生成的SQL语句符合特定数据库的要求。其主要功能包括:
5.1错误识别与修复
数据库适配模块通过分析LLM输出,识别并修复常见错误。针对每种错误类型,设计了启发式算法进行修复。例如,将列映射到正确表、为歧义列随机分配表、添加缺失表、屏蔽不支持函数、替换不存在的列或调整聚合函数等。
5.2执行一致性策略
引入执行一致性策略,通过多次调用LLM生成多个SQL翻译,执行并根据结果投票选择最终输出,进一步稳定翻译结果。这种方法不仅提高了生成SQL的准确性,还增强了模型的鲁棒性。
1.基准与评估指标
1.1基准数据集
在实验中,PURPLE被评估于四个主流的NL2SQL基准数据集:Spider、Spider-DK、Spider-SYN和Spider-Realistic。这些数据集各有特点,旨在全面评估模型在不同场景下的性能。
Spider:包含200个数据库和10,181个NL-to-SQL对,是评估复杂SQL翻译性能的主要基准。
Spider-DK:更具挑战性的版本,要求模型具备领域特定知识。
Spider-Realistic:强调文本与表格的对齐挑战,省略了列名的显式提及。
Spider-SYN:通过交换模式相关术语与同义词来修改NL查询,挑战依赖词汇匹配的方法。
1.2评估指标
为了全面评估PURPLE的性能,实验采用了三种评估指标:精确集匹配(EM)准确率、执行匹配(EX)准确率和测试套件(TS)准确率。
精确集匹配(EM)准确率:使用每个子句的集合比较来衡量SQL语义的精确匹配程度。尽管精确,但可能因新语法结构产生假阴性。
执行匹配(EX)准确率:检查预测SQL执行结果是否与预期结果一致。然而,不同SQL查询可能产生相同结果,导致假阳性。
测试套件(TS)准确率:通过蒸馏测试套件数据库评估,确保高代码覆盖率,修正EX度量的不足。
2.总体性能
2.1 Spider基准上的表现
表4详细展示了PURPLE在Spider验证集上的翻译准确率,并与现有基于LLM和PLM的方法进行了对比。结果表明,PURPLE在EM、EX和TS指标上均表现出色。
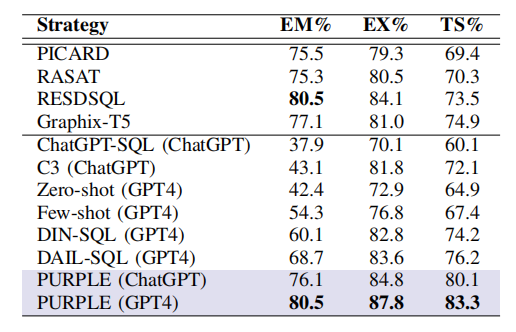
表4:Spider上的翻译准确性
与GPT4结合时:PURPLE在所有指标上均超越其他LLM方法,EM提高11.8%,EX提高4.2%,TS提高7.1%。这表明PURPLE能够显著提升GPT4在NL2SQL任务上的性能。
使用ChatGPT时:即使使用相对较弱的ChatGPT,PURPLE的EM仍比DAIL-SQL高出20.4%,显示出其在不同LLM上的适应性和可靠性。
超越PLM方法:PURPLE在EM得分上达到80.5%,超越所有基于PLM的方法,证明了基于LLM的NL2SQL方法在特定任务上的优越性。
2.2性能分析
PURPLE的卓越性能主要归功于其创新的架构设计和模块化方法。通过模式修剪、骨架预测、示例选择和数据库适配等模块的协同工作,PURPLE能够有效地组织复杂的逻辑操作符组合,生成准确的SQL语句。
3.泛化能力
3.1跨基准评估
为了评估PURPLE的泛化能力,实验在Spider-DK、Spider-SYN和Spider-Realistic三个基准上进行了测试。结果如图10所示,PURPLE在这些基准上均取得了最佳的EM得分。
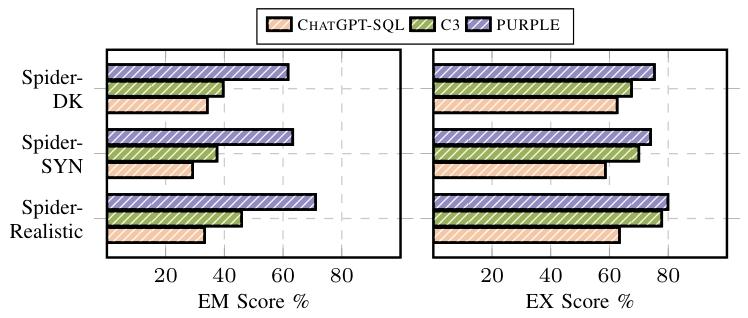
图10:Spider-DK、SpiderSYN和Spider-Realistic的EM/EX分数比较
Spider-DK:EM得分为61.7%,比C3高出22%以上,显示出PURPLE在领域特定知识要求较高的场景下的强大能力。
Spider-SYN:EM得分为63.3%,表明PURPLE能够有效应对词汇匹配挑战。
Spider-Realistic:EM得分为71.1%,进一步证明了PURPLE在现实场景中的适用性。
同时,PURPLE在EX得分上也保持稳定,分别为75.3%、74.0%和79.9%,体现了其相对于其他方法的鲁棒性。
4.成本与性能权衡
4.1预算设置的影响
PURPLE根据令牌数量形成提示,以控制每个SQL翻译的预算。图11展示了在不同预算设置下的性能和令牌消耗。
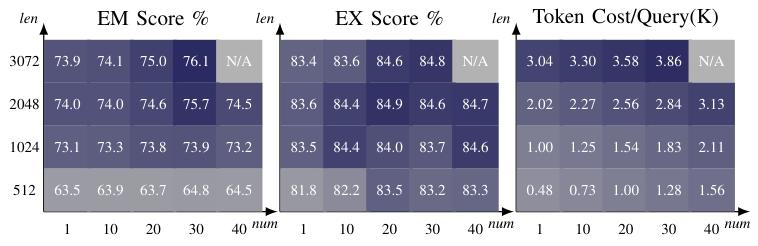
图11:不同预算设置下的 PURPLE(ChatGPT) 表现和代币消耗。len表示提示长度,num表示一致性数。
性能提升趋势:PURPLE的性能随着预算增加而提升,但在输入长度超过2048令牌后提升幅度减小。这表明在一定预算范围内,增加输入长度可以显著提高性能,但超过一定长度后收益递减。
默认配置效率:默认配置为输入长度3072和一致性数量30,在ChatGPT上仅消耗1250个令牌,比其他方法更高效。这使得PURPLE在实际应用中具有更好的成本效益。
5.示例选择的鲁棒性
5.1参数变化的影响
通过变化初始参数p0和调整INCREASE-Generalization方法,实验评估了示例选择算法的鲁棒性。结果如图12左图所示,不同p0和泛化方法对性能影响较小,EM变化小于3%,EX变化小于1.5%,表明PURPLE性能稳定。
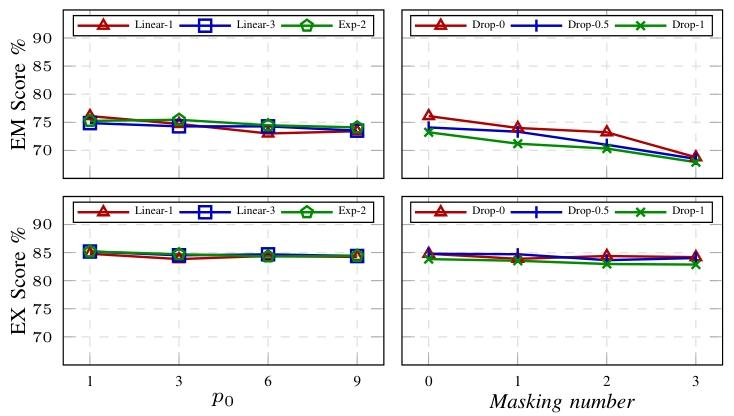
图12:用于演示选择的稳健性评估
5.2骨架预测不准确的影响
右图评估了不准确骨架对性能的影响,即使在仅使用Clause-Level信息的困难情况下,PURPLE仍能取得具有竞争力的EM得分,显示出其对预测不准确性的韧性。
6.不同LLM的性能
6.1性能比较
表5比较了DIN-SQL、C3、DAIL-SQL和PURPLE在使用ChatGPT和GPT4时的性能变化。结果表明,PURPLE无论使用哪种LLM都始终优于其他方法。
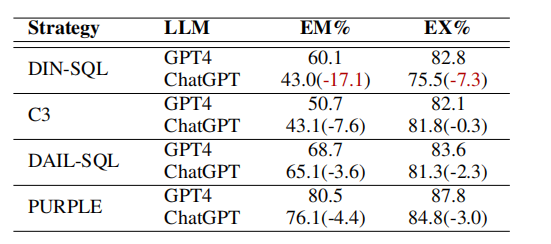
表5:ChatGPT和GPT4之间的EM/EX比较。
DIN-SQL的敏感性:DIN-SQL对LLM选择敏感,使用ChatGPT时性能显著下降,这可能与其依赖复杂的推理任务有关。
C3的稳定性:C3在两种LLM上表现稳定,但未充分利用GPT4的能力,限制了其性能提升。
DAIL-SQL的相似趋势:DAIL-SQL性能变化趋势与PURPLE相似,但缺乏足够的操作符组合知识,导致其在某些场景下表现不如PURPLE。
7.消融研究
7.1模块贡献分析
表6展示了PURPLE各模块的贡献,通过消融研究分析每个模块对整体性能的影响。
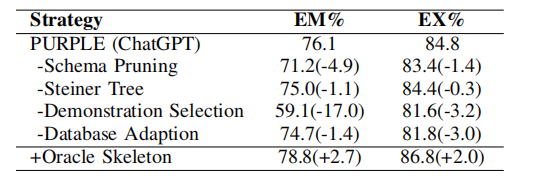
表6:消融研究
模式修剪模块:显著简化任务,帮助LLM专注于SQL生成的关键信息。采用Steiner Tree的修剪策略比RESDSQL的方法更高效。
骨架预测模块:提供必要的逻辑操作符组合知识,对SQL生成至关重要。消融研究表明,随机选择示例会大幅降低EM得分,凸显了骨架预测模块的重要性。
数据库适配模块:进一步稳定了模型输出,减轻了幻觉问题,确保生成的SQL符合特定数据库的要求。
Oracle骨架设置:在理想情况下,PURPLE的EM和EX得分显著提升,突出了准确预测逻辑组合知识对性能的重要性。
早期研究
早期的NL2SQL研究主要集中在规则映射上,这种方法具有有限的泛化能力。例如,Zelle和Mooney在1996年的研究中,提出了使用归纳逻辑编程来解析数据库查询的方法。Simitsis等人在2008年提出了Pr´ecis系统,旨在将非结构化的关键词查询转换为结构化的数据库查询。这些早期方法在特定领域内表现出一定的有效性,但由于依赖于手工设计的规则,难以适应复杂的自然语言查询和多样化的数据库结构。
2.现代方法
现代的NL2SQL方法主要分为两类:基于PLM(预训练语言模型)的方法和基于LLM(大型语言模型)的方法。
2.1基于PLM的方法
基于PLM的方法通常通过微调预训练模型来优化NL2SQL性能。例如,RAT-SQL方法引入了关系感知的模式编码和链接机制,以增强模型对数据库模式的理解。GNN方法则利用图神经网络来表示数据库模式的结构信息,从而提升模型的语义理解能力。其他方法如IRNet、SmBoP、NatSQL等则通过引入中间表示或改进解码器结构来降低解码复杂度。这些基于PLM的方法在特定任务上取得了较好的效果,但由于模型规模和预训练语料的限制,它们在理解和生成复杂SQL方面的能力有限。
2.2基于LLM的方法
基于LLM的方法利用大型语言模型的强大自然语言理解和生成能力来处理NL2SQL任务。这些方法可以进一步分为零样本和少量样本策略。零样本方法如C3,通过指令设计引导LLM生成SQL,无需额外的微调。少量样本方法如DIN-SQL和DAIL-SQL则通过提供少量示例来增强LLM对任务的理解。这些方法在执行匹配准确率上表现出色,但在精确集匹配准确率上仍有提升空间,尤其是在处理复杂的逻辑操作符组合时。
3.LLM在NL2SQL中的应用
LLM在NL2SQL任务中的应用主要集中在以下几个方面:
指令设计:通过精心设计的指令引导LLM生成正确的SQL语句。例如,C3方法通过手工设计的指令来约束LLM的输出格式。
少量样本学习:利用少量示例来帮助LLM理解任务要求。DIN-SQL和DAIL-SQL等方法通过提供相关的NL2SQL示例,让LLM学习如何生成正确的SQL。
链式思维(CoT):通过分解任务和逐步推理来提高LLM的生成准确性。这种方法有助于LLM更好地理解复杂的自然语言查询。
多轮交互:通过多次调用LLM并结合上下文信息,逐步优化生成的SQL语句。这种方法虽然可以提高准确性,但会增加API调用的成本。
综上所述,PURPLE通过检索包含必要逻辑操作符组合的示例,显著增强了LLM在NL2SQL任务上的性能。其创新的四层自动机构建和匹配策略,有效地建模了SQL组合知识。模式修剪和骨架预测模块简化了任务,数据库适配模块稳定了输出并减轻了幻觉问题。实验结果表明,PURPLE在多个基准上均表现出色,且对不同的LLM和预算约束具有良好的适应性和鲁棒性。
1.研究结论
PURPLE通过检索包含必要逻辑操作符组合的示例,显著增强了LLM在NL2SQL任务上的性能。其创新的四层自动机构建和匹配策略,有效地建模了SQL组合知识。模式修剪和骨架预测模块简化了任务,数据库适配模块稳定了输出并减轻了幻觉问题。实验结果表明,PURPLE在多个基准上均表现出色,且对不同的LLM和预算约束具有良好的适应性和鲁棒性。
2.未来展望
未来的研究方向可以进一步探索和优化以下几个方面:
生成式提示方法:目前的PURPLE方法依赖于现有的示例池,未来可以研究如何直接使用PLM生成提示,以提高方法的灵活性和泛化能力。
提示优化技术:通过强化学习等技术优化提示生成过程,提高提示的质量和有效性。
多模态数据融合:结合文本、表格、图表等多种模态的数据,进一步提升模型对复杂查询的理解和生成能力。
跨领域应用:将PURPLE方法应用于更广泛的领域,如生物医学、金融等,探索其在不同领域数据管理中的应用效果。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





