




作者简介
by Laurenz Albe cybertec公司工程师
译者简介
王志斌,从事数据库产品相关工作,主要致力于postgresql数据库高可用解决方案及云端产品化工作。
校对者简介
崔鹏,PostgreSQL爱好者。海能达PostgreSQL高级DBA。
众所周知,高网络延迟不利于数据库性能。PostgreSQL v14 为 libpq C API 引入了“管道模式”,这对于在高延迟网络连接上获得良好的性能特别有用。如果您在“云”中使用托管数据库,那么这篇文章可能会让您感兴趣。
PostgreSQL扩展查询协议
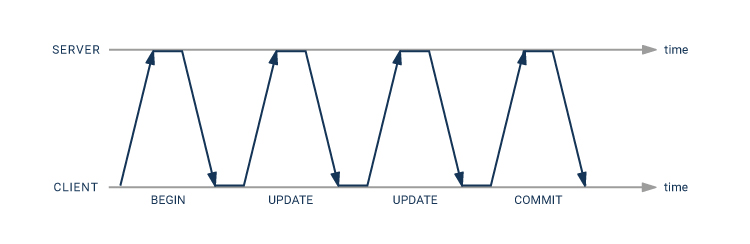
要理解管道模式,我们必须理解[客户端和服务器之间的消息流]。使用扩展查询协议,语句处理如下:
- 向服务器发送带有“Parse”消息的语句
- 将带有参数值的“Bind”消息发送到服务器
- 将向服务器发送一条“执行”消息,请求查询结果
数据库事务通过发送“同步”消息完成。这些消息通常在单个TCP数据包中发送。以上所有消息都是通过调用libpq的“PQexec”或“PQexecParams”函数生成的。对于预编译语句,“Parse”步骤与“Bind”和“Execute”步骤分离。
发送“同步”后,客户端等待服务器的响应。服务器处理该语句并应答:
- “ParseComplete”消息
- “BindComplete”消息
- “Data”或“NoData”消息,具体取决于语句的类型
- “CommandComplete”消息,指示语句已完成处理
最后,服务器发送一条“ReadyForQuery”消息,指示事务已完成,可以进行更多操作。同样,这些消息通常在单个TCP数据包中发送。
管道模式如何工作
管道模式在前端/后端协议级别上并不新鲜。它只取决于这样一个事实,即在发送“Sync”之前,您可以发送多条语句。这允许您在一个事务中发送多条语句,而无需等待服务器的响应。libpq API支持了这个新特性,PostgreSQL v14引入了以下新功能:
- PQenterPipelineMode: 输入管道模式
- PQsendFlushRequest: 发送“Flush”消息,告诉服务器立即开始发回对以前请求的响应(否则,服务器会尝试将所有响应捆绑到单个TCP数据包中)
- PQpipelineSync: 发送“Sync”消息–必须显式调用此消息
- PQexitPipelineMode: 离开管道模式
- PQpipelineStatus: 显示libpq是否处于管道模式
语句本身使用异步查询执行功能发送,如 PQsendQuery, PQsendQueryParams 和PQsendQueryPrepared, 在“Sync”消息被发送之后, PQgetResult被用来接收响应。
由于所有这些都不依赖于前端/后端协议中的新功能,因此您可以对较旧版本的PostgreSQL server使用管道模式。
管道模型的性能优势
让我们假设使用如下表进行简单的资金转账
CREATE TABLE account (
id bigint PRIMARY KEY,
holder text NOT NULL,
amount numeric(15,2) NOT NULL
);
要将资金从一个账户转移到另一个账户,我们必须执行如下交易
BEGIN;
UPDATE account SET amount = amount + 100 WHERE id = 42;
UPDATE account SET amount = amount - 100 WHERE id = 314;
COMMIT;
在正常处理中,从客户端到服务器进行四次往返,因此整个事务将产生8次的网络延迟。
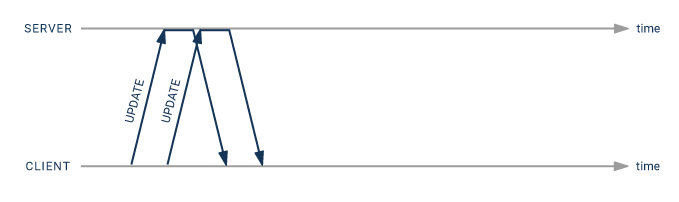
使用管道模式,您只需两次的网络延迟:
- 第二条“UPDATE”语句可以在第一条语句之后立即发送
- 不需要显式事务,因为管道自动是单个事务
使用管道模型的代码示例
这是可用于处理上述事务的C代码。它将准备好的语句“stmt”用于此“UPDATE”语句:
UPDATE account
SET amount = amount + $2
WHERE id = $1
RETURNING amount;
为了关注手头的事情,我省略了建立数据库连接和预编译语句的代码。
#include <libpq-fe.h>#include <stdio.h>/** Receive and check a statement result.* If "res" is NULL, we expect a NULL result and* print the message if we get anything else.* If "res" is not NULL, the result is stored there.* In that case, if the result status is different* from "expected_status", print the message.*/static int checkResult(PGconn *conn,PGresult **res,ExecStatusType expected_status,char * const message){PGresult *r;if (res == NULL){if ((r = PQgetResult(conn)) == NULL)return 0;PQclear(r);fprintf(stderr, "%s: unexpected result\n",message);return 1;}if ((*res = PQgetResult(conn)) == NULL){fprintf(stderr, "%s: missing result\n",message);return 1;}if (PQresultStatus(*res) == expected_status)return 0;fprintf(stderr, "%s: %s\n",message,PQresultErrorMessage(*res));PQclear(*res);return 1;}/* transfer "amount" from "from_acct" to "to_acct" */static int transfer(PGconn *conn,int from_acct,int to_acct,double amount){PGresult *res;int rc;char acct[100], amt[100]; * will fit a number */char * const values[] = { acct, amt }; * parameters */* enter pipeline mode */if (!PQenterPipelineMode(conn)){fprintf(stderr, "Cannot enter pipeline mode: %s\n",PQerrorMessage(conn));return 1;}* send query to subtract amount from the first account */snprintf(values[0], 100, "%d", from_acct);snprintf(values[1], 100, "%.2f", -amount);if (!PQsendQueryPrepared(conn,"stmt", * statement name */2, * parameter count */(const char * const *) values,NULL, * parameter lengths */NULL, * text parameters */0)) * text result */{fprintf(stderr, "Error queuing first update: %s\n",PQerrorMessage(conn));rc = 1;}** Tell the server that it should start returning results* right now rather than wait and gather the results for* the whole pipeline in a single packet.* There is no great benefit for short statements like these,* but it can reduce the time until we get the first result.*/if (rc == 0 && PQsendFlushRequest(conn) == 0){fprintf(stderr, "Error queuing flush request\n");rc = 1;}** Dispatch pipelined commands to the server.* There is no great benefit for short statements like these,* but it can reduce the time until we get the first result.*/if (rc == 0 && PQflush(conn) == -1){fprintf(stderr,"Error flushing data to the server: %s\n",PQerrorMessage(conn));rc = 1;}* send query to add amount to the second account */snprintf(values[0], 100, "%d", to_acct);snprintf(values[1], 100, "%.2f", amount);if (rc == 0&& !PQsendQueryPrepared(conn,"stmt", * statement name */2, * parameter count */(const char * const *) values,NULL, * parameter lengths */NULL, * text parameters */0)) * text result */{fprintf(stderr,"Error queuing second update: %s\n",PQerrorMessage(conn));rc = 1;}/*---* Send a "sync" request:* - flush the remaining statements* - end the transaction* - wait for results*/if (PQpipelineSync(conn) == 0){fprintf(stderr, "Error sending \"sync\" request: %s\n",PQerrorMessage(conn));rc = 1;}/* consume the first statement result */if (checkResult(conn, &res, PGRES_TUPLES_OK, "first update"))rc = 1;elseprintf("Account %d now has %s\n",from_acct,PQgetvalue(res, 0, 0));if (res != NULL)PQclear(res);/* the next call must return nothing */if (checkResult(conn, NULL, -1, "end of first result set"))rc = 1;/* consume the second statement result */if (checkResult(conn, &res, PGRES_TUPLES_OK, "second update"))rc = 1;elseprintf("Account %d now has %s\n",to_acct,PQgetvalue(res, 0, 0));if (res != NULL)PQclear(res);/* the next call must return nothing */if (checkResult(conn, NULL, -1, "end of second result set"))rc = 1;/* consume the "ReadyForQuery" response */if (checkResult(conn, &res, PGRES_PIPELINE_SYNC, "sync result"))rc = 1;else if (res != NULL)PQclear(res);/* exit pipeline mode */if (PQexitPipelineMode(conn) == 0){fprintf(stderr, "error ending pipeline mode: %s\n",PQresultErrorMessage(res));rc = 1;}return rc;}复制
测量管理模式的速度提升
为了验证速度的提高,我在Linux系统上使用了“tc”实用程序,人为地给回环接口增加了50毫秒的延迟:
sudo tc qdisc add dev lo root netem delay 50ms
这可以重置
sudo tc qdisc del dev lo root netem
我测量了在上述函数中花费的时间,以及不使用管道和显式事务的函数的时间:
| | 没有管道 (8次网络延迟) | 管道(2次网络延迟) || -------------- | ---------------------- | ----------------- || first attempt | 406 ms | 111 ms || second attempt | 414 ms | 104 ms || third attempt | 414 ms | 103 ms |复制
对于这样的短SQL语句,通过管道传输获得的速度几乎与节省的客户机-服务器往返成正比。
如果您不想使用libpq的C语言API或直接使用前端/后端协议,那么还有另一种方法可以获得类似的性能改进:您可以编写PL/pgSQL函数或存储过程。
CREATE PROCEDURE transfer(p_from_acct bigint,p_to_acct bigint,p_amount numeric) LANGUAGE plpgsql AS$$BEGINUPDATE accountSET amount = amount - p_amountWHERE id = p_from_acct;UPDATE accountSET amount = amount + p_amountWHERE id = p_to_acct;END;$$;复制
这也将在单个事务中运行,速度也一样快,因为
-“CALL”语句只有一个客户端-服务器往返
- 缓存PL/pgSQL中SQL语句的执行计划
在这种情况下,编写PL/pgSQL过程可能是更简单的解决方案。然而,管道模式允许您精确控制客户端和服务器之间的消息和数据流,这是使用函数无法获得的。
如果您在糟糕的环境中操作数据库功能,则可能无法使用此解决方案。
结论
管道模式是PostgreSQL v14中libpq的C语言API,它允许通过延迟的网络连接显著提高性能。由于它不使用前端/后端协议中的新功能,因此也可以与旧服务器版本一起使用。通常,使用PL/pgSQL函数可以获得类似的性能提升。
点击“阅读原文”,查看原文内容!
PostgreSQL中文社区欢迎广大技术人员投稿
投稿邮箱:press@postgres.cn



