




前文
本期童心未泯季征文主题将围绕“开发者和 OceanBase 的第一次”的故事主线,邀请使用过、在测试、在学习以及刚了解 OceanBase 的开发者们,分享与 OceanBase 一起共同经历过的众多第一次,包括不限于以下参考:第一行代码
第一次考试
第一次深度体验
第一次部署安装
第一次想对 OceanBase 说些什么
……
第一次听到OceanBase
第一次听到OceanBase,我依稀记得是2011至2012年之间,听说OceanBase已经开源了,我第一反应OceanBase是什么东西,一打听才知道OceanBase就是阿里去O的神器。当时业界非常好奇,IOE指IBM的小型机、Oracle的数据库、EMC的存储,大家都认为O数据库是最复杂和最困难的,根本不可能做到。那么OceanBase是怎么做到的?
我一直认为OceanBase底层用的是MySQL的框架和源代码,当时我圈内的工程师也是这么认为,因为当时阿里分库分表的技术已经非常成熟,而且阿里已经掌握 MySQL的内核控制能力。基于MySQL内核代码修改编辑,使其具备分布式路由和负载均衡特性,现在看来 这里说的阿里的另外一个产品PolarDB早型。
后面在论坛看到大神说,阿里有众多产品线,OceanBase是独特的一个产品线,不借鉴开源完全100%代码独立研发,当时就震惊了,国产数据库还有这样的实力!当时非常的怀疑,笔者当过2年DBA,跟着一位10年工作经验的OCP,测过达梦、测过MySQL替换Oracle的方案可行性,对Oralce的认识是刻骨铭心了。它是坚如磐石的一块东西,目前中国没有相关数据库产品将其替代。
就在我对OceanBase充满好奇,准备探点的时候 ,神秘的OceanBase闭源了!网上再搜无影无踪
一直怀着想知道OceanBase是什么的心理,后来我买了一本书叫做《大规模分布式存储系统》,终于清楚了OceanBase的轮廓。
早期的OceanBase的更像lambda架构的数据,不同于大数据的lambda架构分开批处理、实时处理,OceanBase是读和写完全物理隔离分开,下图。
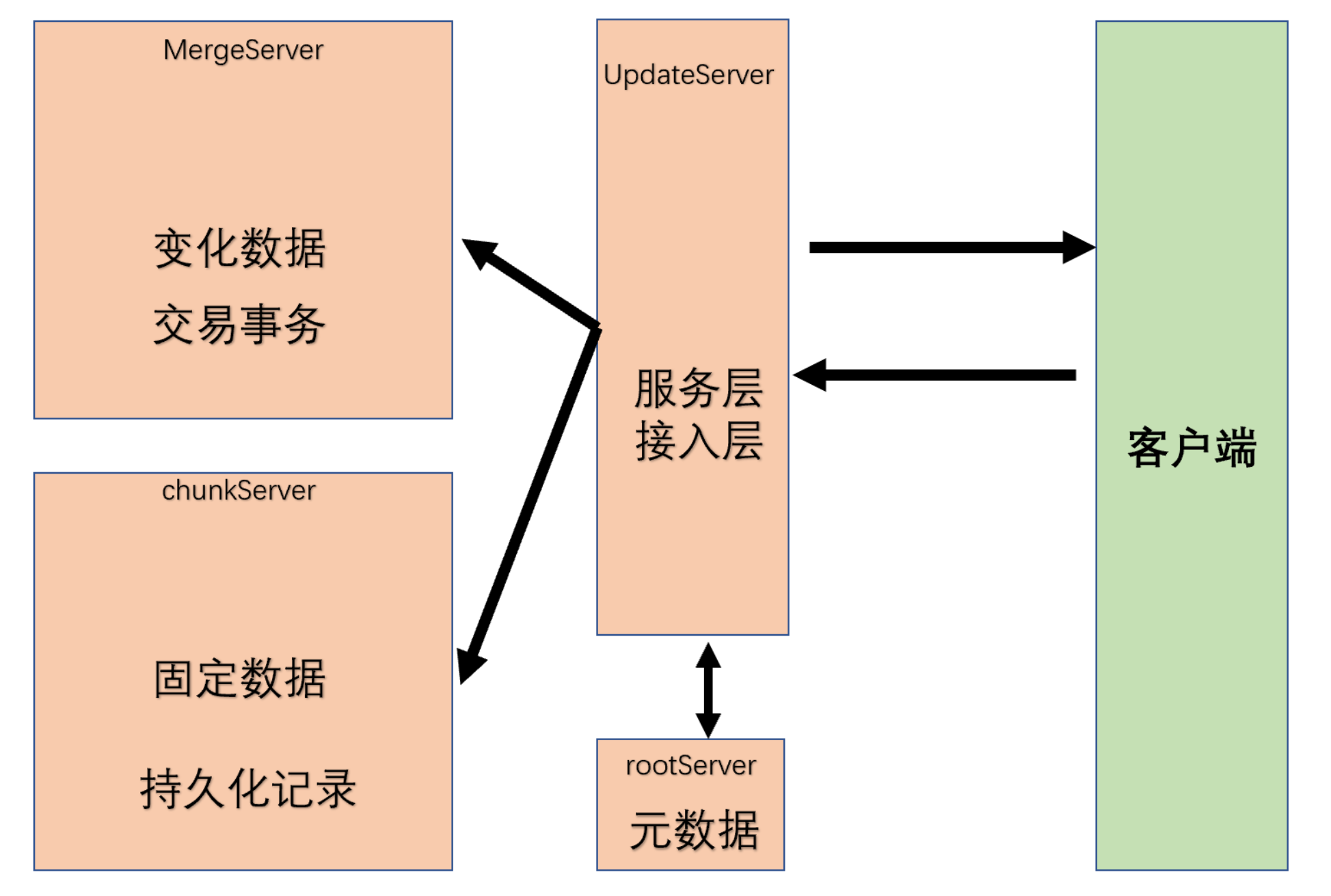
OLTP相关的转帐、支付、清算、核算、计费等交易事务都由updateServer处理,updateServer在工程上主要负责变化中的数据,例如事务中增加、修改、删除等行为,为了支持海量并发,updateServer相当于一个巨大的内存池,对硬件提出更高的要求。
我把那时的OceanBase定义为一个 集中化、完全使用内存lambda式结构的关系型数据库,普通的平民完全用不起,交易处理能力决定于updateServer的性能。
现在的OceanBase3X,节点之间人人平等,服务层接入层解耦,接入层变成obproxy,服务层隐匿在其中一个节点上, 我把它定义为去中心化、分布式和集中式特征并存、行列混合、实现多租户、充分使用内存的数据库。
第一次安装使用OceanBase
第一次安装OceanBase是在2021年的5月份,赶在OceanBase的2021年6月1日正式开源前,当时是为了应付OBCP考试,当时OceanBase的版本是2X,只有界面安装方式。按着文档一步步操作,卡在其中一个画面上,不知道里面发生了什么,也不知道去哪里看。我心想,什么时候OB支持静默安装,可以让我调整几个IP后,直接一键部署。
终于等到OceanBase的obd一键布署工具,通过yum就可以安装obd, 安装三个节点的OB在几分钟内 就可以完成。
对于ob体验是不错的,它还有改进的空间,本人体验过Tiup【TiDB的生命周期管理工具】,obd目前只支持单一集群功能的安装,还不能做到集群管理配置、销毁、增加节点、删除节点的功能。
由于公司不是做纯交易应用开发的,我们只关心数据分析能力,而OB的主业是OLTP,副业才是OLAP。OB自称在OLAP也测试了不俗的成绩,所以我们在服务器搭建了OB 3X集群环境做TPC-H测试。OB也没有用像clickhouse用纯列式引擎,也没有像Presto完全使用内存,也没有像Vertica那样牺牲了大量的空间换取了性能。
OB在OLAP的调整主要使用了并行计算技术,优化器处理后,在调度执行时可以充分利用CPU内核进行并行加速,提高执行的吞吐率。并行处理计算将原本一个线程的工作平均分配到多个线程来完成,通过CPU提高处理能力,其次OB通过table group让分析的数据物理分布上更集中,提高算力。
每一个数据库产品都有自己的权衡架构设计,Presto为了性通牺性了内存,只能处理总内存范围的事。Vertica通过数据映射,每次迭代都生成物理视图和索引,固然提升了性能,但是加大硬盘空间的浪费。TiDB的架构简单清晰,存储、计算、协调独立分离,但是免不了跨网分布式事务。OB的架构强调OLTP为主,保留本地事务,也实现了分布式事务,它的牺性主要依赖更强劲的CPU。
第一次探索OceanBase
一个关系型数据库产品的关键核心组件设计至少包括 并发控制、事务管理器、索引设计、备份恢复 、容灾设计、存储引擎、SQL设计、优化器设计。不知诸君最好奇哪一个的技术实现? 笔者最好奇存储引擎的技术实现,它是最难的也是最重要的。一辆汽车至少由一万多个不可独力拆卸的零件组成,主要由发动机协调各种零部件一起做功,存储引擎就相于汽车的发动机。研究存储引擎的设计和实现完全是工程技术的事情,存储引擎怎么与磁盘硬件互动发生最佳的性能,其它零部件如何集成到存储引擎,惊讶于OB是100%的独立研发,强烈的好奇心驱动我对OceaBase存储引擎做了剖析追溯和调研分析。
OceaBase与TiDB一样,最终数据持久化后都会形成一个sstable文件,但是TiDB的存储引擎TiKV是基于rocksdb抽象封装 ,增加了Raft、MVCC、Transaction、RPC功能等等。
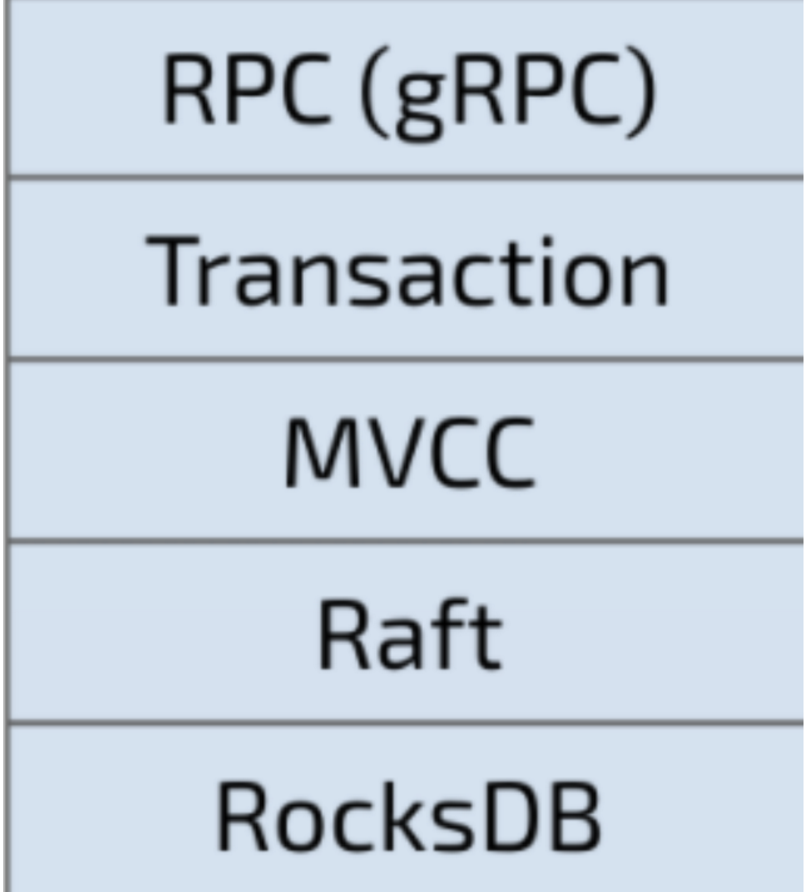
rocksdb则是基于leveldb的基础上开发,兼容LevelDB原有的API,进行了一系列的优化与完善,包 括如下。
- 针对SSD硬盘进行优化,支持更多的IOPS(I/O Operation per Second),并改进数据压缩,减少数据写入,尽可能延长SSD的使用寿命。
- 针对多CPU、多核环境进行优化,从而提升整体性能。一般而言,商用的服务器均采用多核的CPU,RocksDB不仅支持多线程合并、多线程内存表的插入,同时采用MVCC,并将数据库的只读与读写操作分开,减少了锁的使用,从而更适合、进行高并发操作。
- 增加了一系列LevelDB不具备的功能,如数据合并、多种压缩算法、按范围查询,以及一些管理统计维护工具。
RocksDB适用于对数据存取速度要求高的应用场景,例如:垃圾邮件检测应用需要快速获取实时传递的每一封邮件。一个消息队列,需要支持海量的消息插入与删除。作为一个高速缓存,以实现海量数据的实时访问。
原来的LevelDB有什么?LevelDB作为一个嵌入式的数据库,实现的数据库基本功能
- key与value采用字符串形式,且长度没有限制;
- 数据能持久化存储,同时也能将数据缓存到内存,实现快速读取;
- 基于key按序存放数据,并且key的排序比较函数可以根据用户需求进行定制;
- 支持简易的操作接口API,如Put、Get、Delete,并支持批量写入;
- 可以针对数据创建数据内存快照;
- 支持前向、后向的迭代器;
- 采用Google的Snappy压缩算法对数据进行压缩,以减少存储空间;
- 基本不依赖其他第三方模块,可非常容易地移植到Windows、Linux、UNIX、Android、iOS。
LevelDB欠缺的数据库功能:
- 不是传统的关系数据库,不支持SQL查询与索引;
- 只支持单进程,不支持多进程;
- 不支持多种数据类型;
- 不支持客户端-服务器的访问模式。用户在应用时,需要自己进行网络服务的封装。
设计LevelDB需要考虑什么?LevelDB总体模块架构主要包括接口API(DB API与POSIX API)、Utility公用基础类、LSM树(Log、MemTable、SSTable)3个部分。
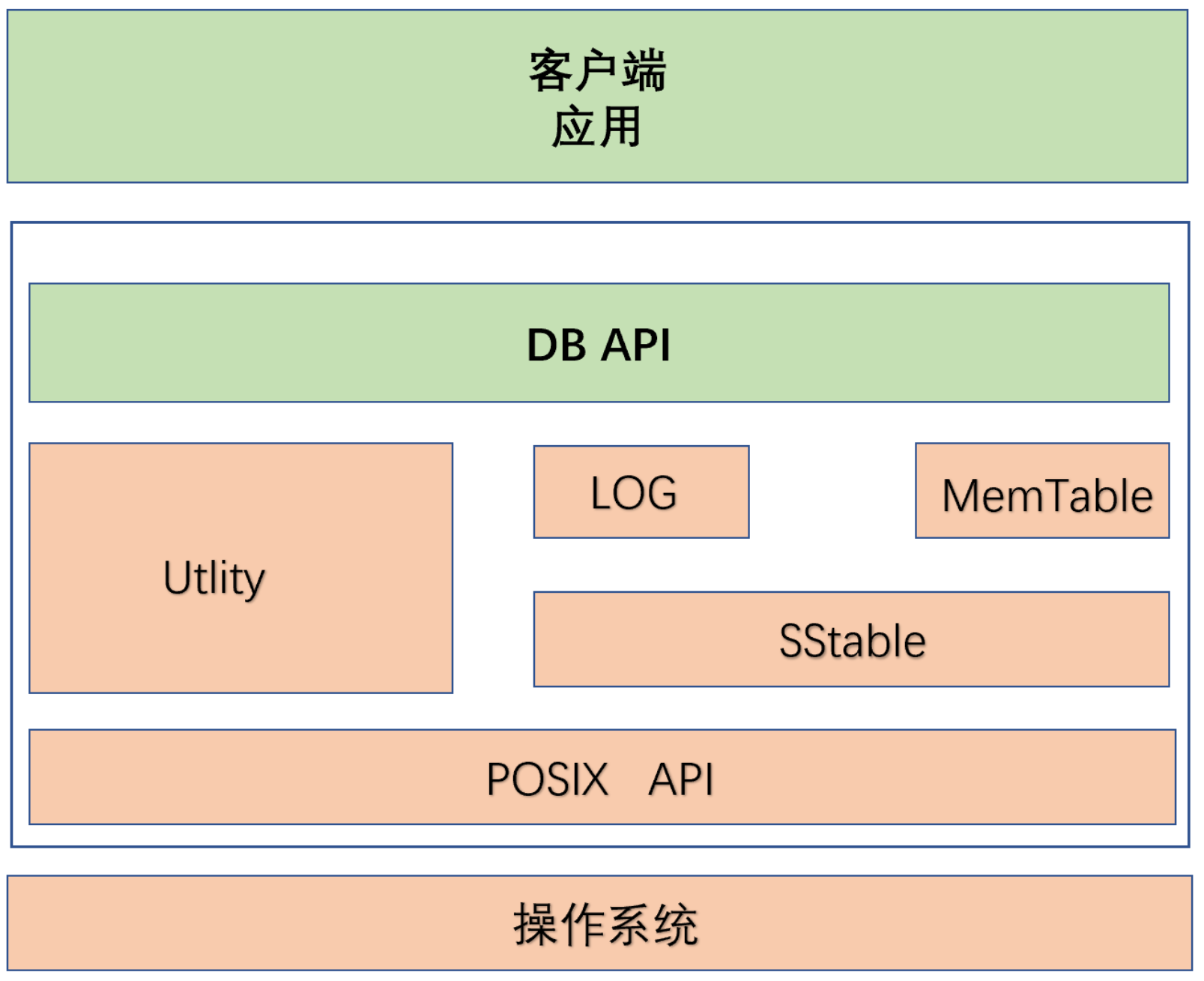
接口API:主要包括客户端调用的DB API以及针对操作系统底层的统一接口POSIX API。
DB API:主要用于封装一些供客户端应用进行调用的接口,即头文件中的相关API函数接口,客户端应用可以通过这些接口实现数据引擎的各种操作。
POSIX API:实现了对操作系统底层相关操作的接口封装,主要用于保证LevelDB的可移植性,从而实现LevelDB在各POSIX操作系统的跨平台特性。
Utility公用基础类:主要用于实现主体功能所依赖的各种对象功能,例如内存管理Arena、布隆过滤器、缓存、CRC校验、哈希表、测试框架等。
LSM树:LSM树(Log、MemTable、SSTable)是LevelDB,主要是数据写入到MemTable【内存】,MemTable如何持久化形成SStable【硬盘】,假设发生宕机,MemTable如何从LOG里面加载文件恢复数据,保障不丢失数据。
[root@hdp3 leveldb-main]# tree -L 3 ./ ./ ├── AUTHORS ├── benchmarks │ ├── db_bench.cc │ ├── db_bench_log.cc │ ├── db_bench_sqlite3.cc │ └── db_bench_tree_db.cc ├── cmake │ └── leveldbConfig.cmake.in ├── CMakeLists.txt ├── CONTRIBUTING.md ├── db │ ├── autocompact_test.cc │ ├── builder.cc │ ├── builder.h │ ├── c.cc │ ├── corruption_test.cc │ ├── c_test.c │ ├── dbformat.cc │ ├── dbformat.h │ ├── dbformat_test.cc │ ├── db_impl.cc │ ├── db_impl.h │ ├── db_iter.cc │ ├── db_iter.h │ ├── db_test.cc │ ├── dumpfile.cc │ ├── fault_injection_test.cc │ ├── filename.cc │ ├── filename.h │ ├── filename_test.cc │ ├── leveldbutil.cc │ ├── log_format.h │ ├── log_reader.cc │ ├── log_reader.h │ ├── log_test.cc │ ├── log_writer.cc │ ├── log_writer.h │ ├── memtable.cc │ ├── memtable.h │ ├── recovery_test.cc │ ├── repair.cc │ ├── skiplist.h │ ├── skiplist_test.cc │ ├── snapshot.h │ ├── table_cache.cc │ ├── table_cache.h │ ├── version_edit.cc │ ├── version_edit.h │ ├── version_edit_test.cc │ ├── version_set.cc │ ├── version_set.h │ ├── version_set_test.cc │ ├── write_batch.cc │ ├── write_batch_internal.h │ └── write_batch_test.cc ├── doc │ ├── benchmark.html │ ├── impl.md │ ├── index.md │ ├── log_format.md │ └── table_format.md ├── helpers │ └── memenv │ ├── memenv.cc │ ├── memenv.h │ └── memenv_test.cc ├── include │ └── leveldb │ ├── cache.h │ ├── c.h │ ├── comparator.h │ ├── db.h │ ├── dumpfile.h │ ├── env.h │ ├── export.h │ ├── filter_policy.h │ ├── iterator.h │ ├── options.h │ ├── slice.h │ ├── status.h │ ├── table_builder.h │ ├── table.h │ └── write_batch.h ├── issues │ ├── issue178_test.cc │ ├── issue200_test.cc │ └── issue320_test.cc ├── LICENSE ├── NEWS ├── port │ ├── port_config.h.in │ ├── port_example.h │ ├── port.h │ ├── port_stdcxx.h │ ├── README.md │ └── thread_annotations.h ├── README.md ├── table │ ├── block_builder.cc │ ├── block_builder.h │ ├── block.cc │ ├── block.h │ ├── filter_block.cc │ ├── filter_block.h │ ├── filter_block_test.cc │ ├── format.cc │ ├── format.h │ ├── iterator.cc │ ├── iterator_wrapper.h │ ├── merger.cc │ ├── merger.h │ ├── table_builder.cc │ ├── table.cc │ ├── table_test.cc │ ├── two_level_iterator.cc │ └── two_level_iterator.h ├── third_party │ ├── benchmark │ └── googletest ├── TODO └── util ├── arena.cc ├── arena.h ├── arena_test.cc ├── bloom.cc ├── bloom_test.cc ├── cache.cc ├── cache_test.cc ├── coding.cc ├── coding.h ├── coding_test.cc ├── comparator.cc ├── crc32c.cc ├── crc32c.h ├── crc32c_test.cc ├── env.cc ├── env_posix.cc ├── env_posix_test.cc ├── env_posix_test_helper.h ├── env_test.cc ├── env_windows.cc ├── env_windows_test.cc ├── env_windows_test_helper.h ├── filter_policy.cc ├── hash.cc ├── hash.h ├── hash_test.cc ├── histogram.cc ├── histogram.h ├── logging.cc ├── logging.h ├── logging_test.cc ├── mutexlock.h ├── no_destructor.h ├── no_destructor_test.cc ├── options.cc ├── posix_logger.h ├── random.h ├── status.cc ├── status_test.cc ├── testutil.cc ├── testutil.h └── windows_logger.h 15 directories, 148 files
LevelDB的源代码十分精简,主要是db目录和table目录的内容,再加上基准性能测试以及第三方插件,总供加起来也没有超过2M。
[root@hdp3 leveldb-main]# du -sk /root/leveldb-main/ 1280 /root/leveldb-main/
RockesDB是从LevelDB1.5上fork出来的,根据笔者的翻阅资料,某个程度上来说,RockesDB是LevelDB的加强版,RockesDB完全可以替代LevelDB。知名NOSQL数据库SSDB是一套基于LevelDB存储引擎的非关系型数据库,可用于取代Redis,更适合海量数据的存储。默认SSDB背端存储用的是LevelDB,也可以选择RockesDB代替。
从github上来看,LevelDB最近没有很大的更新,都是按月为单位去更新,做为一个嵌入式的数据库,成熟度已经走到尽头。
而RockesDB的活动非常频繁,是按天为单位去更新,它正在由一个嵌入式数据库嵌入到各种业务场景中 ,flink通过RocksDB实现状态数据回放,由于强劲的性能,RocksDB支持JNI,从代码目录上感觉上它会用来作为数据库的后端引擎,并且会衍生更多的功能特性。
与LevelDB、RocksDB相比,OceanBase的存储引擎【下面称obkv】远远复杂,主要obkv考虑了事务处理器和租户,光是这是两个元素就使obkv无法变得像LevelDB和RocksDB那么简单纯粹,再加上MVCC、分布式事务、单机事务等诸多方面的考虑,就更加复杂
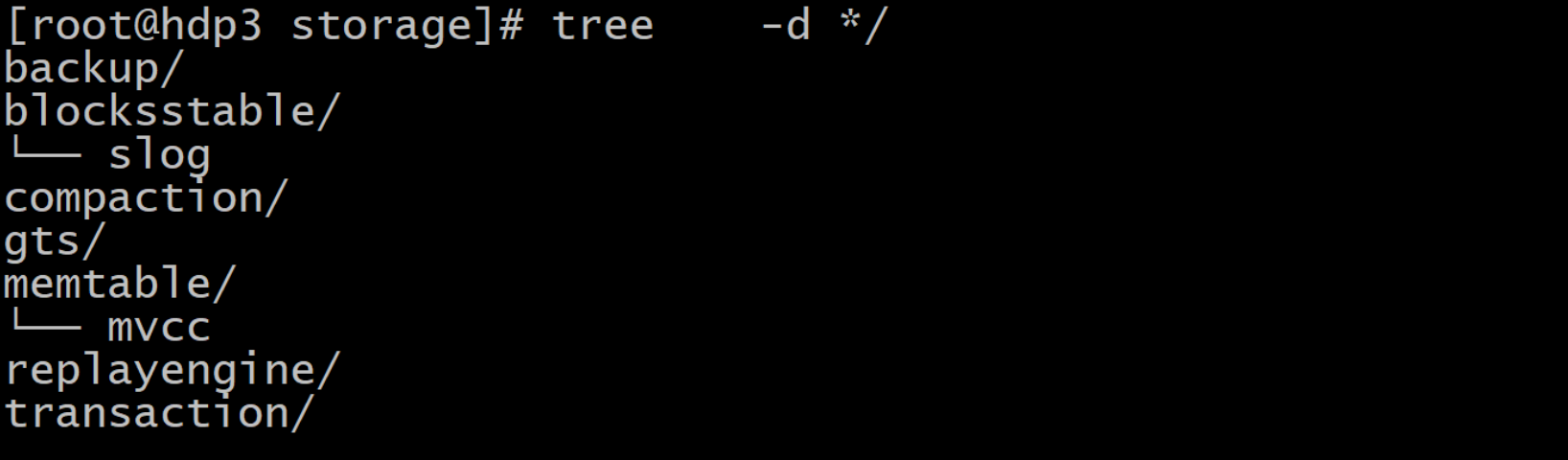
看看storage下面的blocksstable,猜猜里面是什么内容。
我猜是行列混合存储基础单元,物理文件用的是sstable,leveldb、RocksDB的共同点原材料用的都是sstable。
那么sstable与行列混合的之间映射关系,首要先弄清行式是什么?列式是什么?
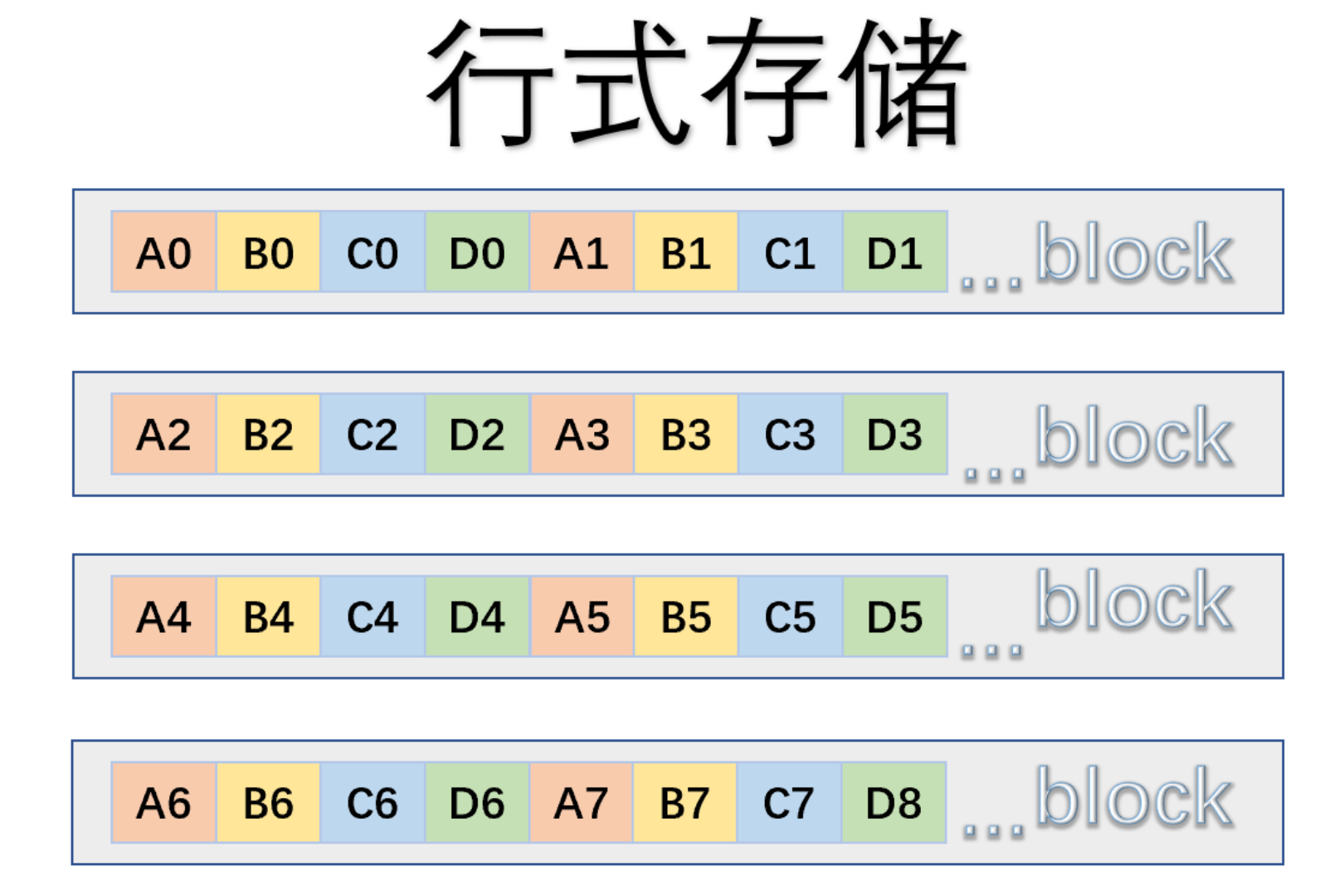
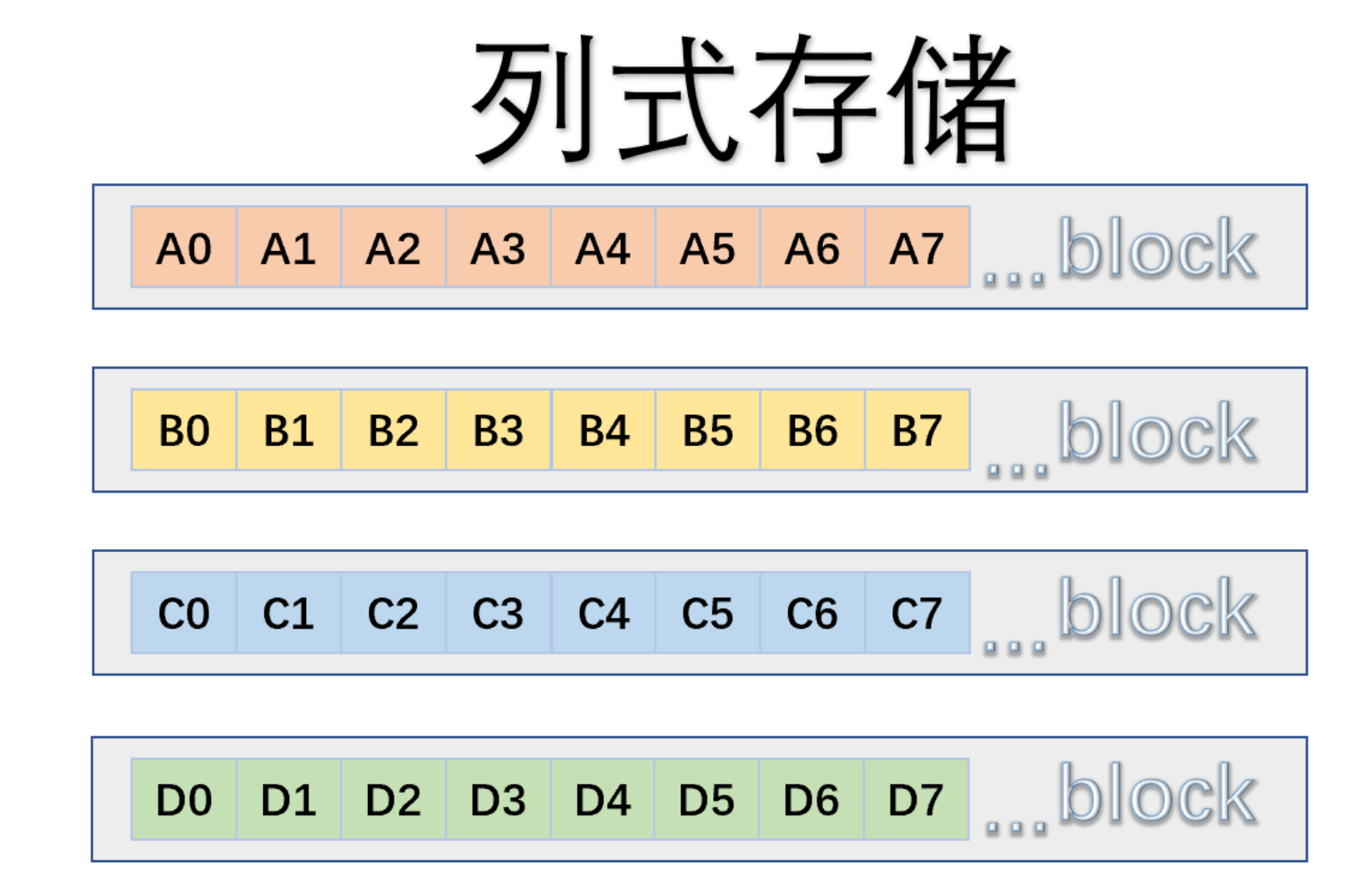
如下图所图,在物理组织上,一个block包含不同字段的信息,因此行式引擎擅长OLTP场景,因为一次IO,马上找到相关的姓名、ID、描述、数量等字段。
但是有一些业务场景,它需要对数据进行聚合计算,例如求和一个月内用户的所有数量,物理组织上我们希望它们排列更加紧凑,于是有了下面列式引擎。
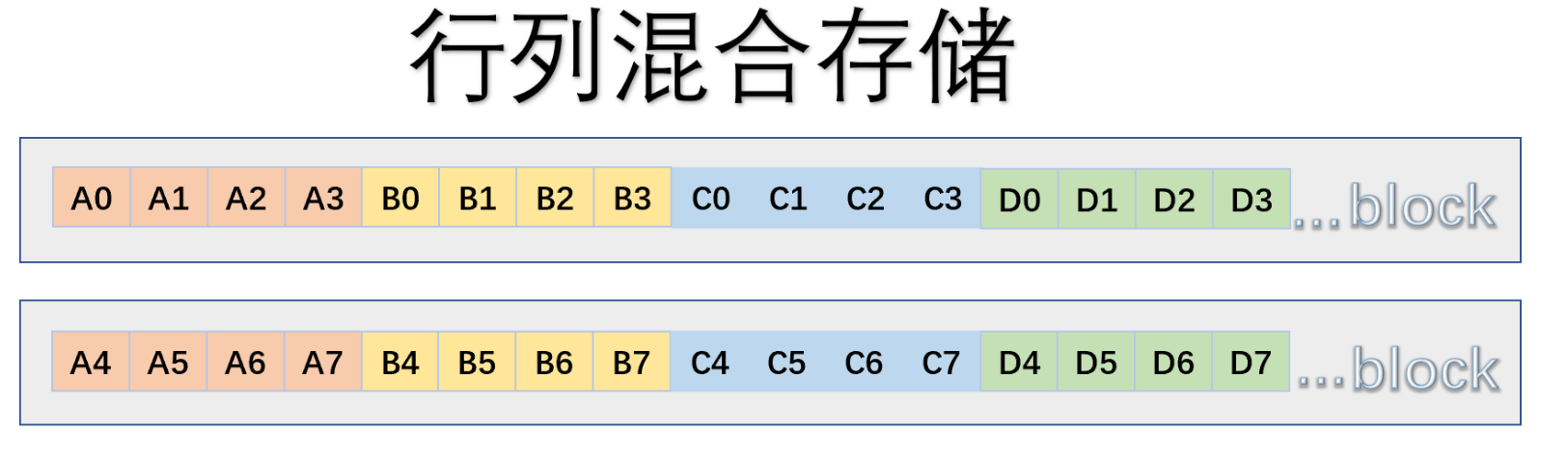
行列存储引擎则是集成了行式和列式的优点,首先通过行组划分,再通过列组划分,HAWQ就是通过ORC的行列混合实现了ACID的,OBKV也是一套行列混合引擎。行列混合最大保留OLTP的功能,但是毕竟不是纯列式,下图所示,纯列式对的A列的聚合计算只需要一个IO,而行列混存需要两个IO。
再搞清sstable是什么,sstable是一个排序的、不可谈的、持久化的文件。读取sstable的流程
- 首先从sstable文件定位域 开始的,先把数据块的索引载入内存,数据块的大小和偏移及相关位置 。
- 结合辅助域的信息,进一步识别加强的数据块的功能,
- 定位数据块里面的内容,根据尾部的偏移及索引,快速定位到 相应的数据值
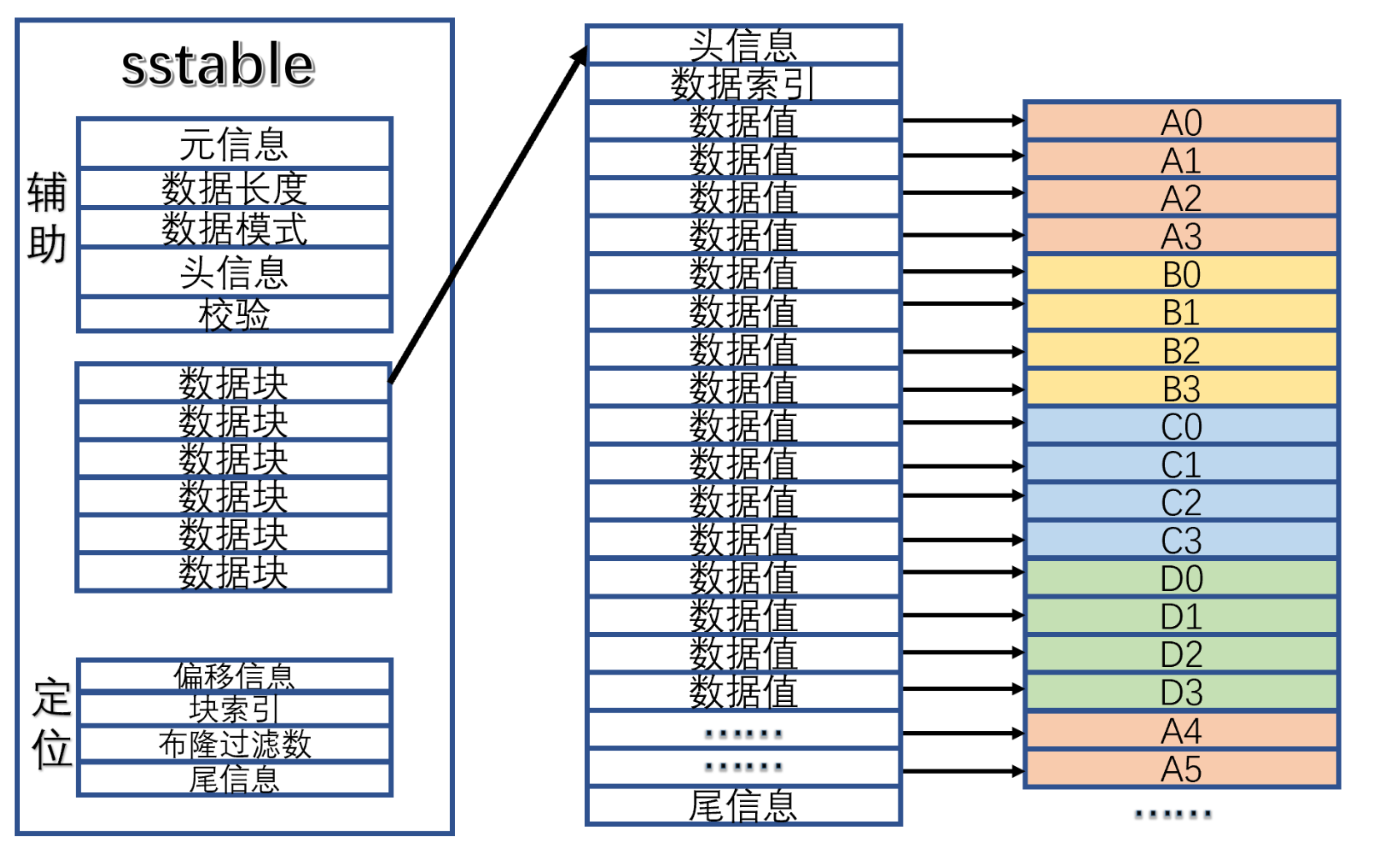
我想象了一下,obkv里面的sstable里面的每一个数据块映射着行列混合。
早期OB用的Direct I/O,但是我在实践中我认为,它用的是标准I/O【Buffered i/o和缓存I/O】,在标准I/O里面,LINUX会将I/O的数据缓存在Page Cache中,即数据会优先复制到内核的缓存区,再从内核的缓冲区复制到应用程序的用户地址空间。
由于我的机器硬件差,经常报error 4030 (Over tenant memory limits) ,官网上说由于内存太少,导致数据无法写到磁盘,经过反复查看,我发现租户中的内存在使用的过程中越来越少,从而导致了4030。而通过echo 3 /proc/sys/vm/drop_cache,把Page Cache释放出来,就不会发生4030的错误。所以我认为现在的OB用的是标准I/O。
写在最后
二战后,德国作为战败国,经济一落一千丈,日尔曼民族靠着勤劳能干创立举世瞩目的宝马、奥迪、奔驰汽车品牌。日本只有中国的云南省的面积,孕育着1.26亿人口,作为一个上千年传统守旧的国家通过引进技术、学习创新和公共决策提高国家竞争力,如今的日本,汽车产品世界第一、手表产品世界第一、相机产品世界第一。大和民族能做到的,我们中华民族也能做到!国产数据库虽然后起,但是未来可期,期待数据库产品像国产车一样冉冉升起。
