




一、Spark简介
Spark 于 2009 年诞生于美国加州大学伯克利分校 AMP实验室,2013 年被捐赠给 Apache 软件基金会,2014 年2月成为 Apache 的顶级项目。
Apache Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎,相对于 MapReduce 的批处理计算,Spark 可以带来上百倍的性能提升,因此它成为继 MapReduce 之后,最为广泛使用的分布式计算框架。
Spark 是一站式解决方案,集批处理、实时流处理、交互式查询、图计算与机器学习于一体。
Spark特点
Spark特点概况起来就四个字:轻、快、灵、巧。
轻
Spark采用Scala语言编写,核心代码只有3万多行,Scala语言具备简洁性和丰富表达力。
快
Spark基于内存运算,与Hadoop的MR相比运算速度要快100倍。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。
灵
Spark支持Java、Python和Scala的API,还支持超过80种高级算法。使用户可以快速构建不同的应用。而且Spark支持交互式的python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
巧
巧妙借力现有大数据组件。Spark可以非常方便地与其他大数据开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。
二、Spark核心组件
Spark 基于 Spark Core 扩展了四个核心组件,分别用于满足不同领域的计算需求。

1. Spark Core
Spark Core 中提供了 Spark 最基础、最核心的功能。Spark其他的功能如:Spark SQL、Spark Streaming、MLlib、GraphX都是在 Spark Core 的基础上进行扩展的。
2. Spark SQL
Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 DataFrame API 等对结构化数据进行查询。
3. Spark Streaming
Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件。用于快速构建可扩展、高吞吐量、高容错的流处理程序。提供了丰富的处理数据流的 API,支持从 HDFS,Flume,Kafka,Twitter 和 ZeroMQ 等读取数据,并进行处理。
Spark Streaming 的本质是微批处理,它将数据流进行极小粒度的拆分,拆分为多个批处理,从而达到接近于流处理的效果。
4. Spark MLlib
Spark MLlib 是 Spark 提供的一个机器学习算法库。MLlib 提供了常见的机器学习算法、模型评估、特征提取转换等功能。
5. Spark GraphX
GraphX 是 Spark 面向图计算提供的框架与算法库。GraphX 提供了丰富的图形算法和构建器,以简化图形分析任务。
三、Spark运行模式
Spark 作为一个数据处理框架和计算引擎,被设计在所有常见的集群环境中运行, 目前实际工作中主流的环境为 Yarn,不过慢慢容器式环境也慢慢流行起来。接下来,我们就分别看看不同环境下 Spark 的运行模式。
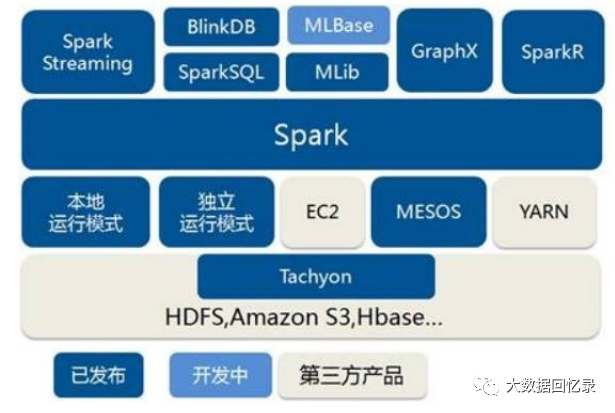
1. Local模式
Local本地模式,也叫单机模式,就是不需要其他任何节点资源就可以在本地执行Spark代码的环境,一般用于教学,调试,演示等。
2. Standalone模式
Standalone独立集群模式,即只使用Spark自身节点运行的集群模式。Spark的Standalone模式体现了经典的master-slave模式。
实际生产环境,还会采用Standalone-HA高可用模式,基于standalone模式基础上,使用zk搭建高可用,避免Master单点故障。
3. Yarn模式
Standalone模式由Spark自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但Spark主要能力是计算框架,资源调度并不是它的强项,所以应该与其他专业的资源调度框架(Yarn)集成会更加高效。
Yarn模式即任务运行在 yarn 集群之上,由 yarn 负责资源管理,Spark 负责任务调度和计算。这样部署的好处是计算资源按需伸缩,集群利用率高,共享底层存储,避免数据跨集群迁移。
4. K8S & Mesos 模式
容器化部署是目前业界很流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是 Kubernetes(k8s),而 Spark也在最近的版本中支持了 k8s 部署模式。
Mesos是Apache下的开源分布式资源管理框架,它被称为是分布式系统的内核,在Twitter得到广泛使用。但国内使用Mesos框架的并不多,其实原理都是类似的。
四、Spark vs Hadoop
Hadoop 的 MR 框架和 Spark 框架都是数据处理框架,二者之间有什么区别和联系呢?
从功能上,hadoop是分布式基础平台, 包含计算, 存储, 调度。spark是分布式计算工具。
应用场景上,Hadoop MapReduce 由于其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景中存在诸多计算效率等问题,MR主要应用场景是大规模数据集的离线批处理为主。而Spark 就是在传统的 MapReduce 计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的 RDD 计算模型。因此spark更适合于迭代计算,、交互式计算、 流计算。
数据存储结构上,MapReduce 中间计算结果存在 HDFS 磁盘上, 延迟大。而spark总体上是基于RDD 中间运算结果存在内存中 , 延迟小。这也是他们之间的根本差异。而且Spark 的缓存机制比 HDFS 的缓存机制高效。
运行方式上,Hadoop的任务以进程方式维护, 任务启动慢。Spark任务采用fork 线程的方式, 任务启动快。
综上,我们可以看出在绝大多数的数据计算场景中,Spark 确实会比 MapReduce更有优势。但是 Spark 是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致 Job 执行失败,此时,MapReduce 其实是一个更好的选择,所以 Spark并不能完全替代 MR。
