点击 卡片,关注 InsideMySQL100W和10亿的表,单条查询性能差别不大,若非性能容量问题,无需做分库分表的架构设计接着,就有大聪明们说了:100W表 DDL 时间短,10亿的表 DDL 时间长,还是有很大区别,所以做分库分表的设计很有益处。
卡片,关注 InsideMySQL100W和10亿的表,单条查询性能差别不大,若非性能容量问题,无需做分库分表的架构设计接着,就有大聪明们说了:100W表 DDL 时间短,10亿的表 DDL 时间长,还是有很大区别,所以做分库分表的设计很有益处。
分库分表后,原来一张表,现在变成1024张表,请问如何让1024张表都DDL完成,是一个原子操作?要么都完成 DDL 操作,要么都完成不了?不但每个分片的数据要求是一致的,每个分片间的数据也要一致,否则备份的数据就失去了意义。对于当前的分布式数据库来说,上述这些问题基本是无解的。
上周 IMG 官方微信高端群中有同学在讨论使用分布式数据库中遇到的问题,其实很多问题基本都是把控力不够,对分布式的理解不足,所以觉得不好用。
再次提醒各位小可爱们,分布式数据库架构是九阴真经,用好了,无敌天下。用得不好,就变九阴白骨爪这种不入流的武功。

是的,对于全球绝大多数的公司,保持单实例数据库架构,就是最好的数据库设计。那问题来了,如果是 10亿条记录的大表呢?如何优雅地进行 DDL 操作?假设每条记录 500 字节,那么 10 亿条记录占用约:500 * 1G = 500 G若大表有3个二级索引,每个二级索引 100字节,则10亿条记录对应的二级索引占用空间约为:3 * 100 * 1G = 300G
另外,假设10亿条记录,表对应的 B+树的高度为4。当前服务器磁盘随机 IOPS 为 10000(已经算慢的),顺序读取性能为 200M s。在有了上述数据后,作为 DBA ,就可以得到下面结论:
通过 B+ 树索引查询单条数据的速度为 4 10000 = 0.0004 秒,需要二级索引回表则需要 0.0008 秒。进行一次全表扫描需要:500G 200M ≈ 42 分钟进行一次二级索引扫描需要:100G 200M ≈ 8.5 分钟好了,到这基本就能知道对10亿量级的表进行一次 DDL 操作所需的大概时间。这里再补充一个假设,对于类似排序、计算的操作,CPU 的开销是 I/O 操作开销的20%。那么进行一次索引重建或添加列的 DDL 操作就需要差不多 :DDL_Cost = I/O + CPU
= 42 + 42 * 20%
≈ 50 分钟
复制
很多小伙伴知道,从 MySQL 5.6 版本开始,大部分的 DDL 操作都已经是 Online,不会阻塞业务的读写操作。
这意味着对10亿量级的表进行原生的 DDL 操作,同学们要做好差不多50分钟的 DDL 变更时间。到这,很多同学会问,这不就直接执行 DDL 语句么?谁不会呀。嗯,的确,10亿的表就是这么简单,粗暴的加索引,也就50分钟的时间,这是一个预期。接着姜老师要谈的是优雅地进行 DDL 变更操作,哪怕是对10亿量级的表,在 DDL 变更期间,对业务的影响也很小,QPS基本无变化。
首先先定义问题,DBA 操作的 DDL 主要有哪些?因为业务发展需要,需要新增额外的列(ADD COLUMN);
因为需要优化线上的 SQL 语句,需要添加索引(ADD INDEX);
因为需要碎片回收,释放空间,需要对表进行重整(REORGANIZE);
因此,若解决了上述 DDL 的三大问题,那就解决了 99% 的 DDL 操作。剩下 1% 的操作,那就需要约 50 分钟的变更窗口。
相信很多同学已经知道,MySQL 8.0 新增了瞬间加列功能,即通过下面的语法可以快速加列:ALTER TABLE tbl_name
ADD COLUMN col_name column_definition
ALGORITHM = INSTANT
INSTANT means instantaneous ,意味着瞬间。即该 DDL 操作仅更改表的元数据信息,不用改变表中的实际记录,因此是可以瞬间完成的操作。瞬间加列功能虽好,但是对于 DDL 操作的仅限于加列,对于索引添加、表的重整没有帮助。同时,还要求 MySQL 版本必须升级到 8.0.12 以上。
这些是不入流的招式,上不了台面,且对业务的影响也相当大,真心不如直接 Online DDL。
学会这招,大部分 DDL 都可以做到是 instantaneous 的。
乾坤大挪移不仅仅针对 DDL 操作,几乎所有的 MySQL 变更都可以使用。在线业务的 MySQL 数据库大概率都是一个主从架构。
若是业务数据库,有10亿量级,且还需要时不时进行 DDL 变更的,大概率至少是一个一主两从的复制拓扑架构,如:

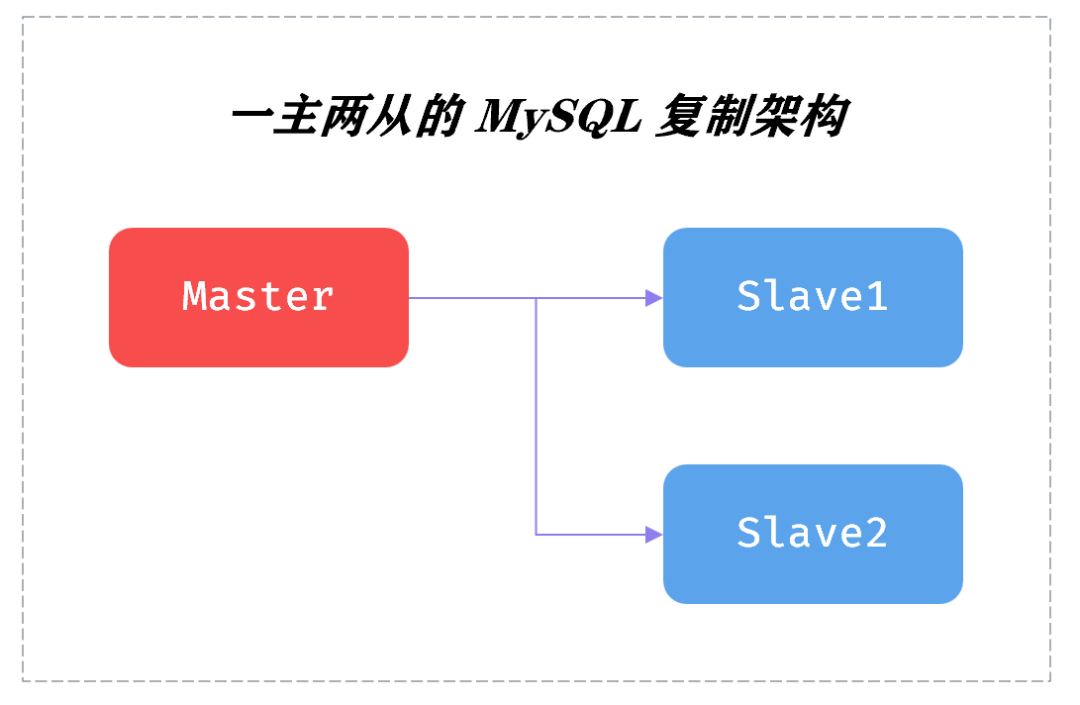
一主两从就是借力打力的“力”,由此 DBA 们可以进行 rolling upgrade。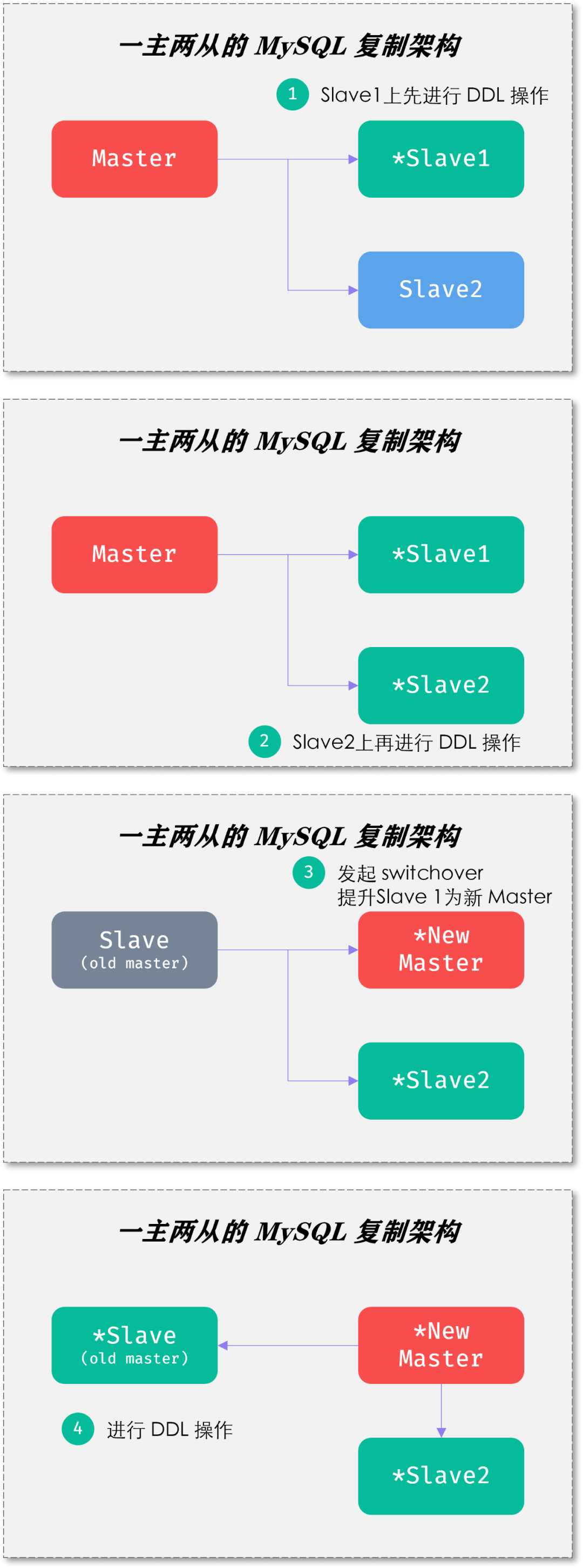
由于种种原因 MySQL 在设计之初摒弃了 Oracle 数据库的物理复制,因此允许 Master 和 Slave 之间有不同的表结构、不同的字段类型之间的数据复制。此外,MySQL 复制是 share nothing 的架构,因此先在 Slave 上进行 DDL 操作,对于 Master 节点毫无影响。唯一的影响在于 switchover 时,业务程序需要重连数据库。但若在业务低峰期进行,则业务几乎无感知。即便在业务高峰期,影响也是相当有限。物理复制 + share everything,Oracle 的落后是全方位的落后当然,姜老师也必须承认,乾坤大挪移的心法虽然简单,但是要习得第7层的最高境界,需要将 rolling upgrade 这套全部做到平台自动化,且对相当多的细节需要打磨。一套 MySQL 复制集群 rolling upgrade 是简单的,难的是10套、100套、1000套的操作。如果对于即便1主9从的 MySQL 复制拓扑架构,你的 rolling upgrade 都能做到收放自如,姜老师必须送你一张图:有了这套乾坤大挪移,哪怕10亿级别的表 DDL 操作都能如丝般顺滑,你还坚持要进行分库分表这样的分布式架构改造么?因为老板们都是宇宙无敌聪明和睿智的人,听他们的,总没错!
1. 上述10亿条记录的大表容量计算,800G容量的计算结果是存在缺陷的。请问还少了哪几块的存储空间计算?更为精确的容量预估是多少?2. rolling upgrade 虽好,但还是需要进行重量级的表操作。对于常见的加列业务需求,还有没有其他设计方法?
3. 如何进一步降低 switchover 过程中对于上层服务的影响?想要知道思考题的标准答案,欢迎加入 IMG 官方社区高端群 。入群请加姜老师个人微信 82946772,并备注:码农入群IMG 官方社区高端群是订阅制的,不过也就99元/年,权当请姜老师喝杯咖啡。突破微信群人数500的限制,以后所有高端群小伙伴可以在一起吹水;
提供 IMG 公众号每篇技术文章最后遗留问题的标准答案;
技术圈的江湖八卦,比如某数据库出局某行的原委,某大V被新领导GZ;
IMG社区技术嘉年华大会门票5折优惠;
姜老师夫妇的私密分享,包括技术、工作、投资、相亲、移民等热门话题;
会员每邀请新会员入群,可以享受59元的返利(把年费赚回来😄);