




一、背景

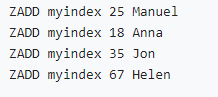
数值类型索引(zset按分数排序):
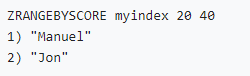
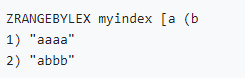
字符类型索引(分数相同时zset按字典序排序):

二、场景一:词典补全
将用户搜索banana添加进索引: ZADD myindex 0 banana:1
假设用户在搜索表单中输入“bit”,并且我们想提供可能以“bit”开头的搜索关键字。 ZRANGEBYLEX myindex "[bit" "[bit\xff"
将用户搜索banana添加进索引 判断banana是否存在 ZRANGEBYLEX myindex "[banana:" + LIMIT 0 1 假设banana不存在,添加banana:1,其中1是频率 ZADD myindex 0 banana:1
假设banana存在,需要递增频率 若ZRANGEBYLEX myindex "[banana:" + LIMIT 0 1 中返回的频率为1
1)删除旧条目:ZREM myindex 0 banana:1
2)频率加一重新加入:ZADD myindex 0 banana:2
假设用户在搜索表单中输入“banana”,并且我们想提供相似的搜索关键字。通过ZRANGEBYLEX获得结果后按频率排序。
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 101) "banana:123"2) "banaooo:1"3) "banned user:49"4) "banning:89"复制
使用流算法清除不常用输入。从返回的条目中随机选择一个条目,将其分数减1,然后将其与新分数重新添加。但是,如果新分数为0,我们需从列表中删除该条目。 若随机挑选的条目频率是1,如banaooo:1
ZREM myindex 0 banaooo:1假设banana不存在,添加banana:1,其中1是频率 ZADD myindex 0 banana:1 若随机挑选的条目频率大于1,如banana:123
ZREM myindex 0 banana:123
ZADD myindex 0 banana:122
三、场景二:多维索引
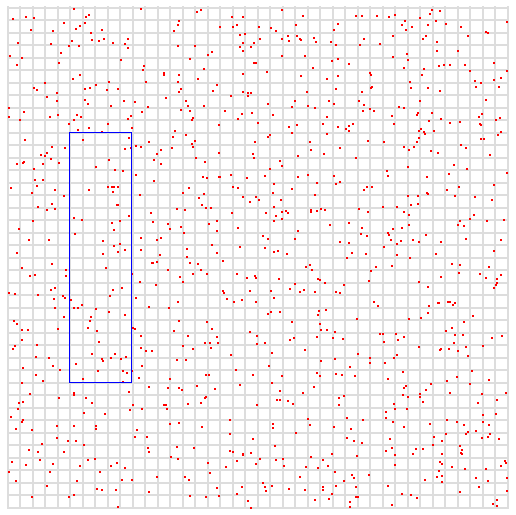
x = 075
y = 200
027050
若使用00和99替换最后两位,即027000 to 027099,map回x和y,即:
x = 70-79
y = 200-209
x = 75 -> 001001011
y = 200 -> 011001000
交织后,000111000011001010

若插入数据点为x = 75和y = 200
x = 75和y = 200二进制交织编码后为000111000011001010,
ZADD myindex 0 000111000011001010
def spacequery(x0,y0,x1,y1,exp)bits=exp*2x_start = x0/(2**exp)x_end = x1/(2**exp)y_start = y0/(2**exp)y_end = y1/(2**exp)(x_start..x_end).each{|x|(y_start..y_end).each{|y|x_range_start = x*(2**exp)x_range_end = x_range_start | ((2**exp)-1)y_range_start = y*(2**exp)y_range_end = y_range_start | ((2**exp)-1)puts "#{x},#{y} x from #{x_range_start} to #{x_range_end}, y from #{y_range_start} to #{y_range_end}"# Turn it into interleaved form for ZRANGEBYLEX query.# We assume we need 9 bits for each integer, so the final# interleaved representation will be 18 bits.xbin = x_range_start.to_s(2).rjust(9,'0')ybin = y_range_start.to_s(2).rjust(9,'0')s = xbin.split("").zip(ybin.split("")).flatten.compact.join("")# Now that we have the start of the range, calculate the end# by replacing the specified number of bits from 0 to 1.e = s[0..-(bits+1)]+("1"*bits)puts "ZRANGEBYLEX myindex [#{s} [#{e}"}}endspacequery(50,100,100,300,6)复制
四、总结
五、附录
本文作者: 华为云数据库GaussDB(for Redis)团队 杭州/西安/深圳简历投递: yuwenlong4@huawei.com 更多产品信息,欢迎访问官方博客:
bbs.huaweicloud.com/blogs/248875

 戳“阅读原文”,了解更多
戳“阅读原文”,了解更多文章转载自GaussDB数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
2025年4月中国数据库流行度排行榜:OB高分复登顶,崖山稳驭撼十强
墨天轮编辑部
1852次阅读
2025-04-09 15:33:27
2025年3月国产数据库中标情况一览:TDSQL大单622万、GaussDB大单581万……
通讯员
599次阅读
2025-04-10 15:35:48
北京市公安局数据库大单:华为云GaussDB 1427万、金仓数据库 510万!
通讯员
277次阅读
2025-04-11 12:33:24
云和恩墨钟浪峰:安全生产系列之SQL优化安全操作
墨天轮编辑部
241次阅读
2025-03-31 11:08:20
新疆维吾尔自治区行政事业单位数据库2025年框架协议采购(二次)入围结果公布
通讯员
138次阅读
2025-04-14 12:21:01
2687万!上海浦东发展银行采购GaussDB软件许可和服务
通讯员
137次阅读
2025-04-23 11:36:39
国产非关系型数据库 Eloqkv 初体验
JiekeXu
130次阅读
2025-04-10 23:51:35
案例-索引对于并发Insert性能优化测试
布衣
94次阅读
2025-04-09 22:47:23
融合Redis缓存的PostgreSQL高可用架构
梧桐
85次阅读
2025-04-08 06:35:40
Oracle数据库常用脚本(八)
hongg
58次阅读
2025-04-02 09:09:23
