





大家好!我是栗子鑫,今天主要分享一下在面试的时候遇到的一个问题:“了解哪些分类损失函数?”,博主答了CE,Focal Loss以及PolyLoss。对于各个损失函数笔者进行了简单的介绍,正文如下,希望对你们有所帮助。文末附源码。
01
—
简介
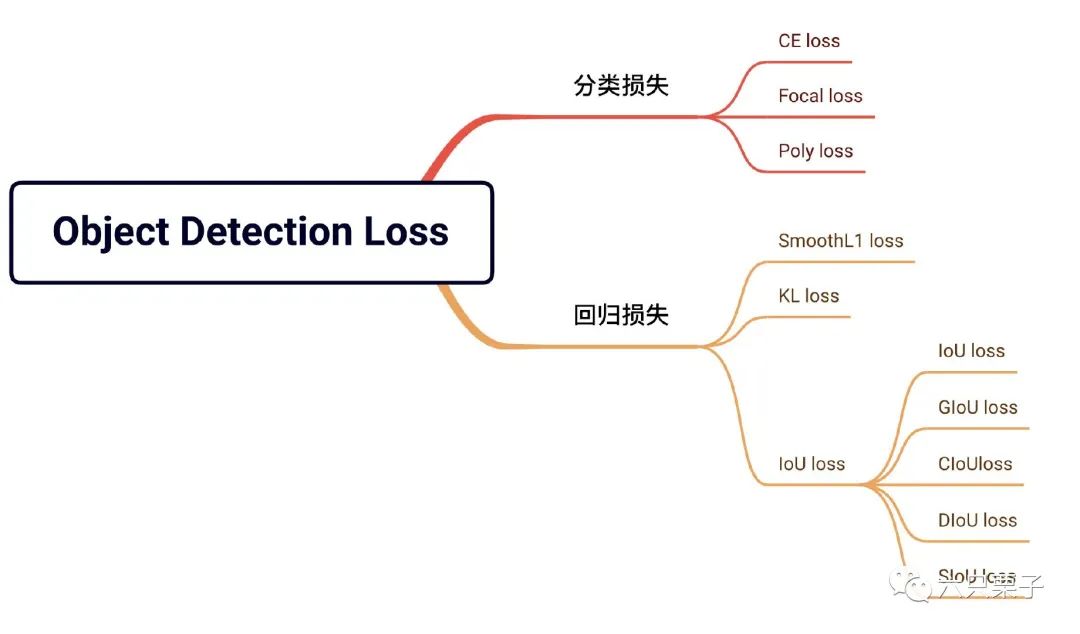
在目标检测中损失函数主要分为两大类,一类是求目标类别的分类损失函数另一类是求目标位置的信息的回归损失函数。本篇博客主要先介绍有关于目标检测的分类损失函数。
02
—
CrossEntropy Loss
CrossEntropy loss又称为交叉熵损失简称CE,交叉熵主要是用来判定实际的输出与期望的输出的接近程度。分类问题的目标变量是离散的,尽管交叉熵刻画的是两个概率分布之间的距离,但是神经⽹络的输出却不⼀定是⼀个概率分布。为此我们常常⽤Softmax回归将神经⽹络前向传播得到的结果变成概率分布。softmax常⽤于多分类过程中,它将多个神经元的输出,归⼀化到( 0, 1) 区间内,因此Softmax的输出可以看成概率,从⽽来进⾏多分类。
分类问题可以简化为二分类问题(多分类问题也可以理解为多个二分类问题),这里借用西瓜书中的🌰来介绍二分类和多分类任务:
二分类任务 (如判断一个西瓜是好瓜还是坏瓜)
在二分类情况中, 对于每一类别的预测只能是两个值, 假设预测为好瓜 (1) 的概率为 , 坏瓜 (0) 的概率为
则, 二分类交叉熵损失的一般形式为, 其中 为标签:
损失 为:
对于这个损失的理解:
预测为好瓜(1)的概率为 ,
预测为好瓜(0)的概率为 ,
则 , 当 为 1 时, , 当 为 0 时, 。
对于概率问题,通过相对熵(KL散度)转化为上述的交叉熵损失Loss。至于如何转化的博主这里就不详细介绍了,《Pytorch常用的交叉熵损失函数CrossEntropyLoss()详解[1]》这篇博客介绍的很详细,感兴趣的可以去翻阅。
多分类任务(如判断一个西瓜的品种,如黑美人,特小凤,安农二号等)
多分类和二分类类似,二分类标签为1和0,而多分类可以用one-hot编码来表示,即现在要预测西瓜品种,品种有黑美人,特小凤,安农二号,如果真实标签为特小凤即(0,1,0),预测标签为安龙二号即(0,0,1),将预测标签的各个概率带入即可,多分类的情况实际上就是对二分类的扩展:
表示第 个样本的真实标签为 , 共有 个标签值 个样本, 表示第 个样本预测为第 个标签值的概率。通过对该损失函数 , 的拟合, 也在一定程度上增大了类间距离。
03
—
Focal Loss
Focal Loss损失函数是在标准交叉熵损失基础上修改得到的,主要解决正负样本带来的类别不均衡问题以及简单易分样本和困难分样本的不均衡问题。在目标检测的训练过程中,一张图片在送入网络结构中,会产生成千上万的“候选区域”(candidate locations),但这些候选区其中只有很少一部分包含待检测目标,大概比率1:1000,这带来的影响就是负样本数量太多了,而且大多数属于背景样本,容易进行分类,虽然容易分类,带来的损失值小,但因为其数量多,会占据整个loss的大部分,从而导致模型的优化方向并不是我们所希望的方向。这样会导致网络过分的关注背景信息,学习不到有用的东西,无法对目标进行准确的分类。因此针对上述类别不均衡问题提出了Focal loss损失函数,具体公式如下:
其中它相对于交叉熵损失函数多引入了两个超参数 和 。Y为样本标签值为0或1。 为模型预测,其值的取值范围为(0-1)。
从目标检测整个训练的角度来解析整个损失函数:
正负样本定义:
当某个候选区域设定为正样本时,其 ,如果其预测值 趋近于1,该样本表示易分正样本。
当某个候选区域设定为正样本时,其 ,如果其预测值 趋近于0,该样本表示难分正样本。
当某个候选区域设定为负样本时,其 ,如果其预测值 趋近于0,该样本表示易分负样本。
当某个候选区域设定为负样本时,其 ,如果其预测值 趋近于1,该样本表示难分负样本。
对于整个网络结构应该重点关注难分样本,减少易分样本的权重。
超参数 主要是用来控制正负样本对总的损失的贡献权重。由于在训练过程中负样本数量占据主导,通过将 值调小,来减少负样本的权重,来平衡正负样本对整个损失的贡献。超参数 主要用来针对在 只能平衡正负样本的权重的基础上,来减少易分类样本的权重,从而使得模型在训练时更专注于难分类的样本。当一个正样本或者负样本被分错时,1- 或者 的值会接近1,调制系数就趋于1,对整个损失影响不大。反之正样本或者负样本被分对时,1- 或者 的值会接近0,导致调制系数趋于0,也就是对于总的损失的贡献很小。超参数 主要用来控制调制系数的大小,平滑地调节了易分样本调低权值的比例。为了查看效果博主做了一个对比实验效果如下:
对比实验结果
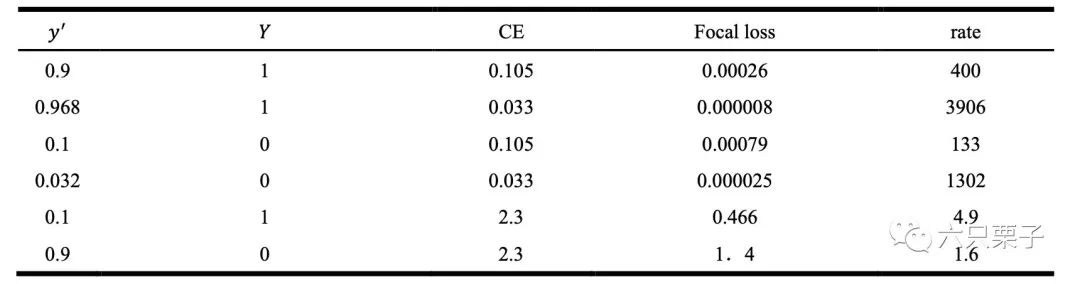
从最后列可以看出相比于易分样本困难样本的调节权重更加合理,弱化了易分样本的损失。
04
—
Poly Loss
读者想详细了解Poly loss 移步于笔者的上一篇博客一文细聊PolyLoss
PolyLoss为理解和改进常用的ce和focal loss提供了一个框架,灵感来自于下面这两个分类损失函数的泰勒展开式:
...
05
—
总结
上文讲述了目标检测中分类算法中的交叉熵损失函数和Focal loss损失函数以及Poly loss。相信读者对目标检测中的分类算法有了简单的认识。最后祝大家能早日拿到心仪的offer。
关注六只栗子,面试不迷路!
06
—
源码
import numpy as np
import torch
import torch.nn as nn
#CE
def CE(pred, label):
loss = label * np.log(pred) + (1 - label) * np.log(1 - pred)
return -loss
#Focal loss
class FocalLoss(nn.Module):
def __init__(self, weight=None, reduction='mean', gamma=0, eps=1e-7):
super(FocalLoss, self).__init__()
self.gamma = gamma
self.eps = eps
self.ce = torch.nn.CrossEntropyLoss(weight=weight, reduction=reduction)
def forward(self, input, target):
logp = self.ce(input, target)
p = torch.exp(-logp)
loss = (1 - p) ** self.gamma * logp
return loss.mean()复制
参考资料
Pytorch常用的交叉熵损失函数CrossEntropyLoss()详解: https://zhuanlan.zhihu.com/p/98785902
作者 栗子鑫
编辑 一口栗子




