





大家好!我是栗子鑫,今天主要分享一下在面试的时候遇到的一个问题:“了解哪些分类损失函数?”,博主答了CE,Focal Loss以及PolyLoss。面试官可能对PolyLoss感兴趣些,详细问了一下,今天就来讲一下PolyLoss,正文如下,希望对你们有所帮助。文末附源码。
01
—
理论基础
提出背景
在某些意义上,损失函数可以是将预测和标签映射到任何可微的函数。但是,由于损失函数具有庞大的设计空间,导致设计一个良好的损失函数通常是具有挑战性的,而在不同的工作任务和数据集上设计一个通用的损失函数更是具有挑战性。
例如,L1/L2 Loss
通常用于回归的任务,但很少用于分类任务;对于不平衡的目标检测数据集,Focal loss
通常用于缓解Cross-entropy loss
的过拟合问题,但它并不能始终应用到其他任务。
基本概念
PolyLoss的目的是将常用的分类损失函数(原论文主要是ce和focal loss)通过泰勒展开,分解为一系列加权多项式基,分解的形式为:
其中,表示多项式损失的权重,表示预测目标标签的概率。原论文中研究表明有必要针对不同的任务和数据集调整多项式系数,同时也发现简单地调整多项式前面的的单个多项式系数(小自由策率)足以实现对常用的ce和focal loss的显著改进。
02
—
PolyLoss
PolyLoss为理解和改进常用的ce和focal loss提供了一个框架,灵感来自于下面这两个分类损失函数的泰勒展开式:
PolyLoss For Cross-entropy loss
使用梯度下降法来优化CE需要对进行梯度求解。在PolyLoss的论文中,多项式的系数正好抵消了多项式基的第次幂,则CE的梯度就是多项式的和:
这样可以观察到梯度展开中的多项式项捕获了对的不同灵敏度。第一个梯度项是1,它提供了一个恒定的梯 度,这样不会受值影响,同时当j 远大于1时以及接近1时,第项被强烈抑制。
PolyLoss For FocalLoss
在
PolyLoss
框架中,Focal loss
通过调制因子γ简单地将移动。这相当于水平移动所有的多项式系数的γ。为了从梯度的角度理解Focal loss
,取关于的Focal loss
梯度:对于正的γ,
Focal loss
的梯度降低了CE
中恒定的梯度项1。正如上文所表述的,这个恒定梯度项导致模 型强调多数类,因为它的梯度只是每个类的示例总数。通过将所有多项式项的幂移动γ,第1项就变成,被γ抑制,以避免过拟合到(即接近1)多数类。
PolyLoss多项式系数的影响
上文描述可知展开多项式存在着高阶多项式,对于多项式系数原论文也进行了深入研究,探索分配多项式系数的三种不同策略:
删除高阶项 调整多个靠前前多项式系数 仅调整第一个多项式系数
具体调整策略见下图:

发现调整第一个多项式系数(Poly-1 公式)有最大增益的同时,也只需要最少的代码变动和超参数调整。最后优化PolyLoss为:
作者还研究了不同第1项缩放对精度的影响,并观察到增加第1个多项式系数可以提高ResNet-50的精度,结果如下:
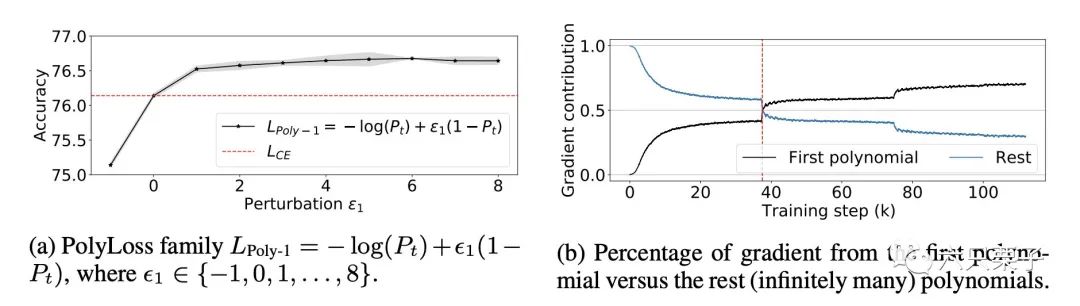
增加第一个多项式项 的系数始终可以提高ResNet50 预测精度。红色虚线表示使用交叉熵损失时的准确度(绘制了三次运行的平均值和标准差)。 第一个多项式 贡献了一半以上在最后65%的训练步骤的交叉熵梯度,这突出了重要性调整第一个多项式。红色虚线表示交叉。
PolyLoss的优势
针对于PolyLoss在目标分类,目标检测等方面表现出的结果可以在原论文中查看,这里就不再赘述。论文链接地址
PolyLoss的优点:
损失的通用性:将ce和focal loss可以表示为poly loss的一个特殊形式 损失的创新性: 提供一个简单有效的 Poly-1损失,通过简单的策略和一行代码调整多项式损失权重,减少超参调整难度。
03
—
总结
上文讲述了PolyLoss的由来、内容和优点。相信读者对PolyLoss有了浅显的认识。最后祝大家能早日拿到心仪的offer。
关注六只栗子,面试不迷路!
04
—
源码
import tensorflow as tf
def poly1_cross_entropy(epsilon=1.0):
def _poly1_cross_entropy(y_true, y_pred):
# pt, CE, and Poly1 have shape [batch].
pt = tf.reduce_sum(y_true * tf.nn.softmax(y_pred), axis=-1) # 原论文中的P_t
CE = tf.nn.softmax_cross_entropy_with_logits(y_true, y_pred)
poly1 = CE + epsilon * (1 - pt)
loss = tf.reduce_mean(poly1)
return loss
return _poly1_cross_entropy
def poly1_focal_loss(gamma=2.0, epsilon=1.0, alpha=0.25):
def _poly1_focal_loss(y_true, y_pred):
p = tf.math.sigmoid(y_pred)
ce_loss = tf.nn.sigmoid_cross_entropy_with_logits(y_true, y_pred)
pt = y_true * p + (1 - y_true) * (1 - p)
FL = ce_loss * ((1 - pt) ** gamma)
if alpha >= 0:
alpha_t = alpha * y_true + (1 - alpha) * (1 - y_true)
FL = alpha_t * FL
poly1 = FL + epsilon * tf.math.pow(1 - pt, gamma + 1)
loss = tf.reduce_mean(poly1)
return loss
return _poly1_focal_loss复制
参考文献
链接地址: https://openreview.net/pdf?id=gSdSJoenupI
评论

 0 点赞
0 点赞


