




全表扫描可能会影响性能。当然,如果扫描的表很大。最坏的情况是连接中涉及全表扫描,特别是当扫描的表不是第一个时(这在 MySQL 8.0 之前是戏剧性的,因为使用了块嵌套循环)!

全表扫描意味着 MySQL 无法使用索引(没有索引或没有使用它的过滤器)。
效果
当全表扫描发生时(当然取决于大小),大量数据被拉入缓冲池,并且可能从工作集中提取其他重要数据。大多数情况下,应用程序甚至可能不需要缓冲池中的新数据,这真是浪费资源!
然后你就会明白全表扫描的另一个副作用是 I/O 操作的增加。
全表扫描最明显的症状是:
- CPU使用率增加
- 磁盘 I/O 的增加(取决于表的大小和缓冲池的大小)
- 访问行的增加
趋势
查看我们是否增加了全表扫描的最佳方法是什么?
MySQL 没有提供准确的表扫描量的指标,此外,如果对只有 1 条记录的表执行全表扫描,是否有问题?
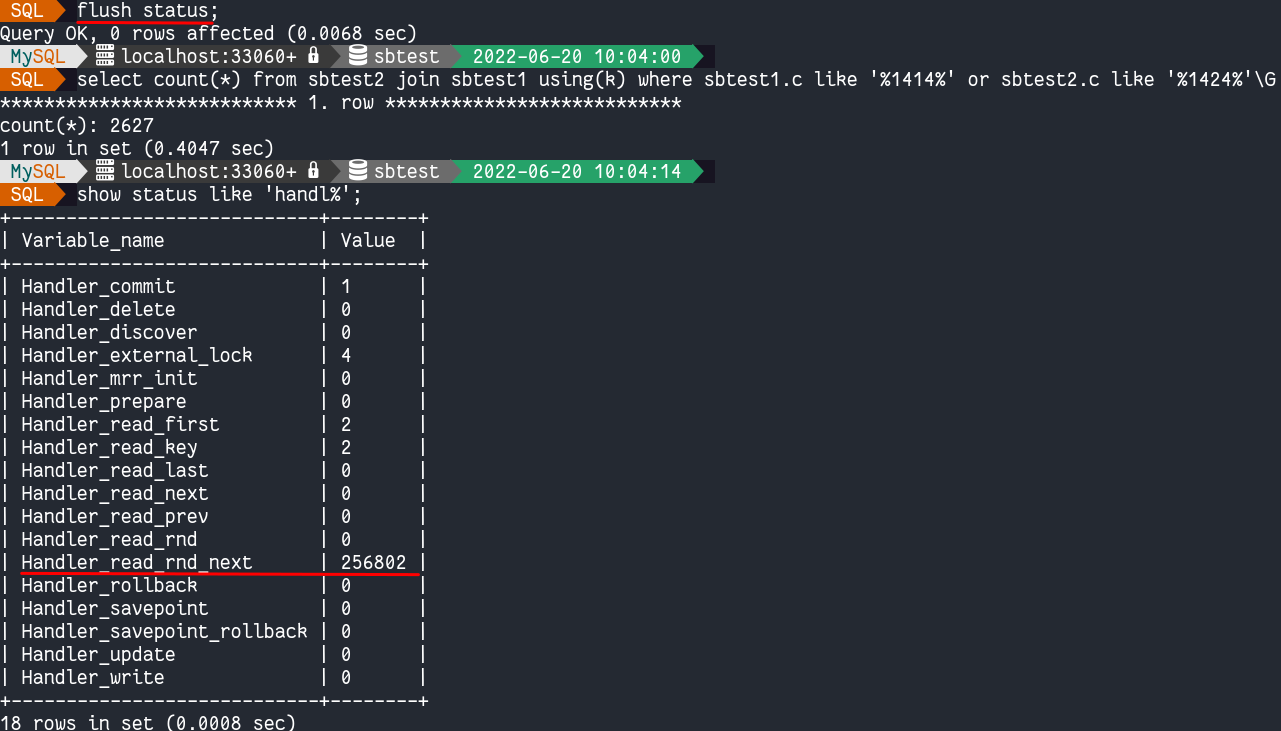
为了确定我们是否增加了全表扫描,我们将使用处理程序 API 指标handler_read_rnd_next:
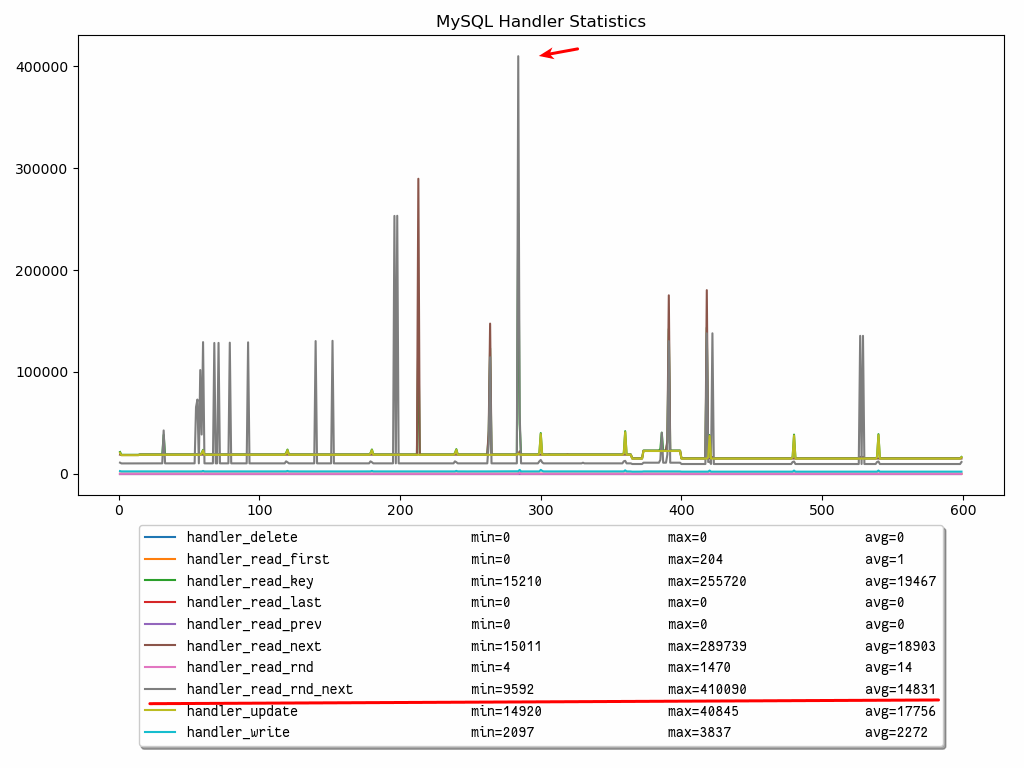
handler_read_rnd_next 表示读取数据文件中下一行的请求数。换句话说,它表示非索引读取的数量。
处理程序 API
每个存储引擎都是一个类,该类的每个实例都通过一个特殊的handler 接口与 MySQL 服务器通信。
处理程序 API 是 MySQL 和存储引擎之间的接口。MySQL 服务器通过该 API 与存储引擎通信,存储引擎负责管理数据存储和索引管理。
变量计算 Handler_% 处理程序操作,例如 MySQL 要求
存储引擎从索引中读取下一行的次数。
这正是 handler_% 上图中绘制的那些变量的值。
让我们快速浏览一些有趣的:
- handler_read_first:读取索引中第一个条目的次数。如果此值较高,则表明服务器正在执行大量全索引扫描
- handler_read_next:按键顺序读取下一行的请求数。如果您正在查询具有范围约束的索引列或正在执行索引扫描,则此值会增加。
- handler_read_rnd_next: 读取数据文件下一行的请求数。如果您正在执行大量表扫描,则此值很高。通常,这表明您的表没有正确建立索引,或者您的查询不是为了利用您拥有的索引而编写的。被调用Handler_read_rnd_next时递增。handler::rnd_next()此操作将光标位置前进到下一行。
有关其他处理程序状态变量的更多信息,请查看手册。
我重写了来自High Performance MySQL, 3rd edition, O’Reilly的查询以与 MySQL 8.0 兼容,以说明处理程序计数器的检测:
SELECT * FROM ( SELECT STRAIGHT_JOIN LOWER(gs0.VARIABLE_NAME) AS variable_name, gs0.VARIABLE_VALUE AS value_0, gs1.VARIABLE_VALUE AS value_1, ROUND((gs1.VARIABLE_VALUE - gs0.VARIABLE_VALUE) / 60, 2) AS per_sec, (gs1.VARIABLE_VALUE - gs0.VARIABLE_VALUE) AS per_min FROM ( SELECT VARIABLE_NAME, VARIABLE_VALUE FROM performance_schema.global_status UNION ALL SELECT '', SLEEP(60) FROM DUAL ) AS gs0 JOIN performance_schema.global_status gs1 USING (VARIABLE_NAME) WHERE gs1.VARIABLE_VALUE <> gs0.VARIABLE_VALUE ) a WHERE variable_name LIKE 'handler%';复制
这是此查询的输出示例
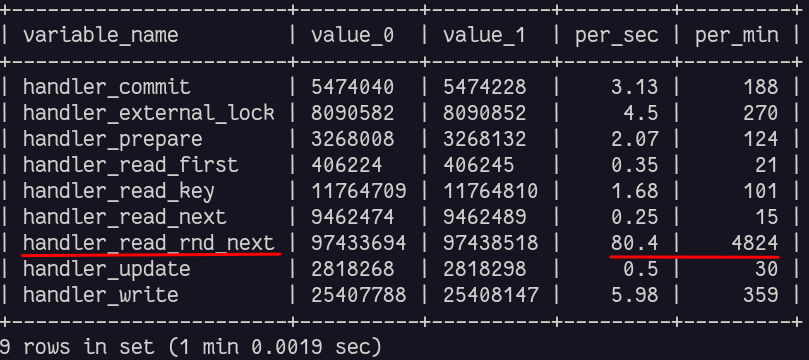
请注意 SHOW VARIABLES 命令是全表扫描,并且在handler_read_rnd_next执行该命令时计数器将递增。
加入
如上所述,当连接中涉及全表扫描时,通常会使事情变得更糟。该信息也可以绘制
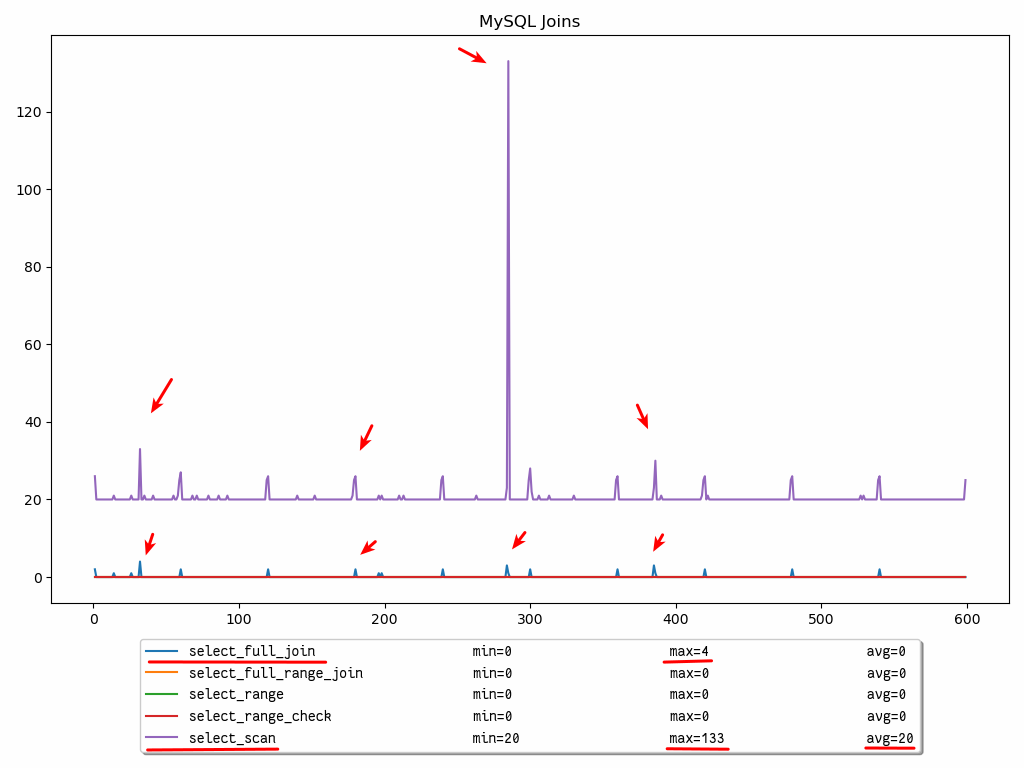
SELECT MySQL 提供状态变量允许控制在语句期间如何进行连接:
- select_range:在第一个表上使用范围的连接数。即使值非常大,这通常也不是关键问题。
- select_scan:对第一个表进行完整扫描的连接数。
- select_full_range_join:在引用表上使用范围搜索的连接数。换句话说,这是使用表 n 中的值从表 n + 1 中的引用索引范围内检索行的连接数。根据查询,这可能比Select_scan.
- select_range_check:在每行之后检查键使用情况的无键连接数。如果这不是 0,则应仔细检查表的索引,因为此查询计划的开销非常高。
- select_full_join:这是您不希望看到的高价值计数器。它表示执行表扫描的连接数,因为它们不使用索引、交叉连接数或没有任何条件来匹配表中的行的连接数。在为特定查询检查此值时,检查的行的值是每个表中行数的乘积。应该绝对避免!
如何找到那些查询?
Performance_Schema 和 Sys Schema 具有检索执行全表扫描的查询所需的所有资源。让我们看一下以下查询的输出:
SELECT format_pico_time(total_latency) total_time, db, exec_count, no_index_used_count, no_good_index_used_count, no_index_used_pct, rows_examined, rows_sent_avg, rows_examined_avg, t1.first_seen, t1.last_seen, query_sample_text FROM sys.x$statements_with_full_table_scans AS t1 JOIN performance_schema.events_statements_summary_by_digest AS t2 ON t2.digest=t1.digest ORDER BY total_latency DESC\G复制
这是一个返回行的示例:
total_time: 2.05 s db: sbtest exec_count: 3 no_index_used_count: 3 no_good_index_used_count: 0 no_index_used_pct: 100 rows_examined: 859740 rows_sent_avg: 1 rows_examined_avg: 286580 first_seen: 2022-06-16 12:21:14.450874 last_seen: 2022-06-16 12:23:48.577439 query_sample_text: select count(*) from sbtest2 join sbtest1 using(k) where sbtest1.c like '%1414%' or sbtest2.c like '%1424%'复制
我们可以看到,这个查询平均每次执行时扫描超过 280k 行。
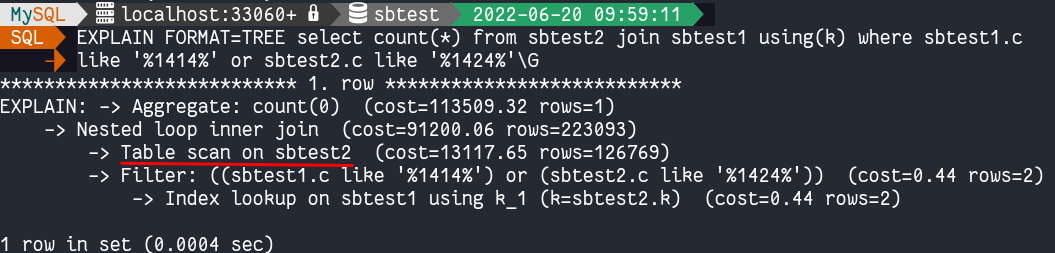
让我们看一下该特定查询的查询执行计划并确认它是否进行全表扫描:
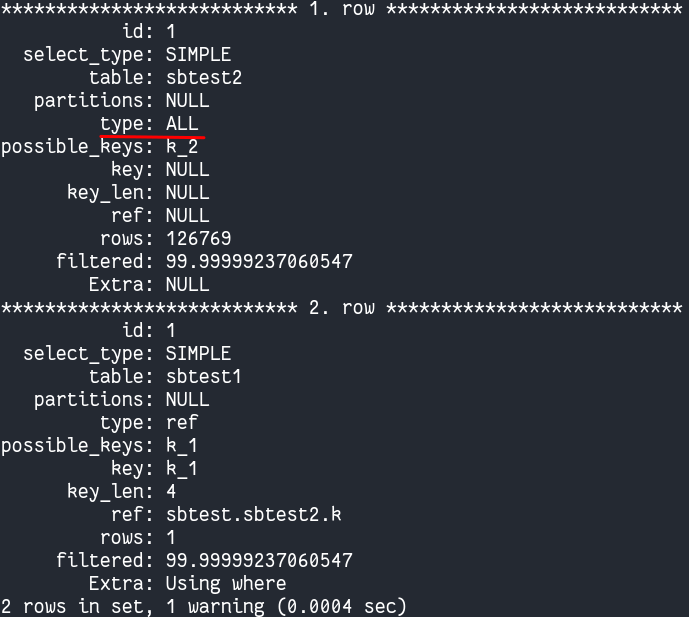
当我们使用 Tree 格式时,这一点更加明显:
为了说明另一个不良行为,我将删除这两个表的 k 列上的索引并使用相同的查询。
我们还将检查 handler_% 和 Select_% 状态变量:
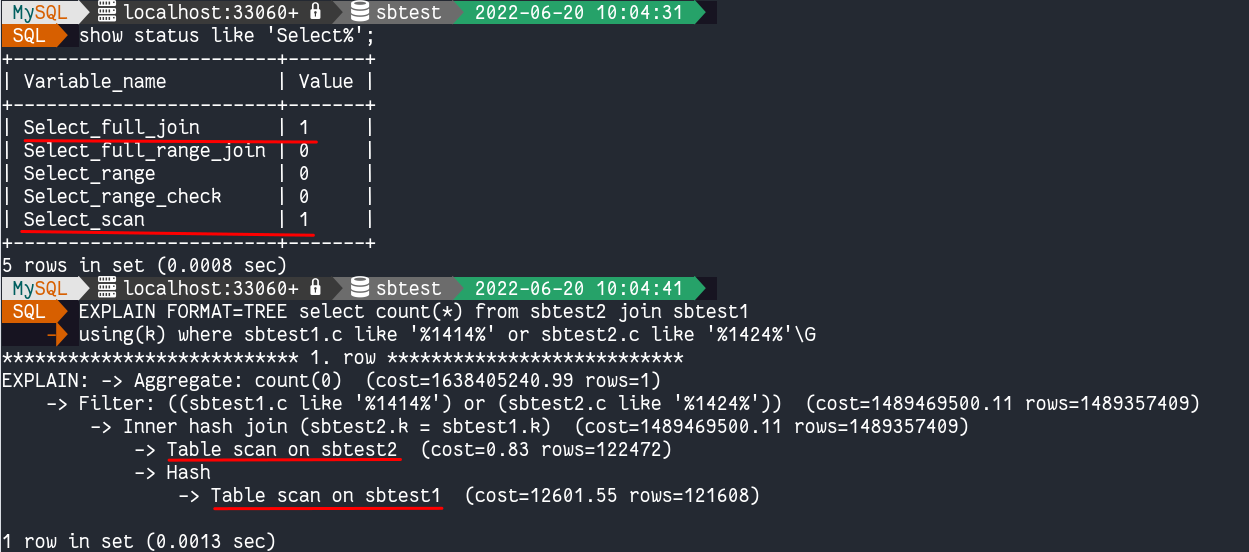
我们可以看到这正是我们应该避免的情况,尤其是如果您不使用 MySQL 8.0。如果没有哈希连接,情况会更糟!
结论
一般来说,应该避免全表扫描,但这当然也取决于所涉及的表的大小、存储的性能、使用的存储引擎(Performance_Schema 不是问题)以及缓冲池的使用方式。
查询优化是解决方案,这包括最终添加索引,必须重写查询,…但这并不总是那么容易。
如果您需要处理此类操作,我建议您阅读 MySQL 8 Query Performance Tuning的第 24 章,Jesper Wisborg Krog,Apress,2020。
享受 MySQL!
原文标题:A graph a day, keeps the doctor away ! – Full Table Scans
原文作者:Lefred
原文地址:https://lefred.be/content/a-graph-a-day-keeps-the-doctor-away-full-table-scans/



