




向量数据库中的数据插入和数据持久性。
在Deep Dive系列的前一篇文章中,我们介绍了如何在世界上最先进的向量数据库Milvus中处理数据。本文将研究数据插入的组件,详细说明数据模型,并解释如何在Milvus中实现数据持久性。
Milvus架构概述
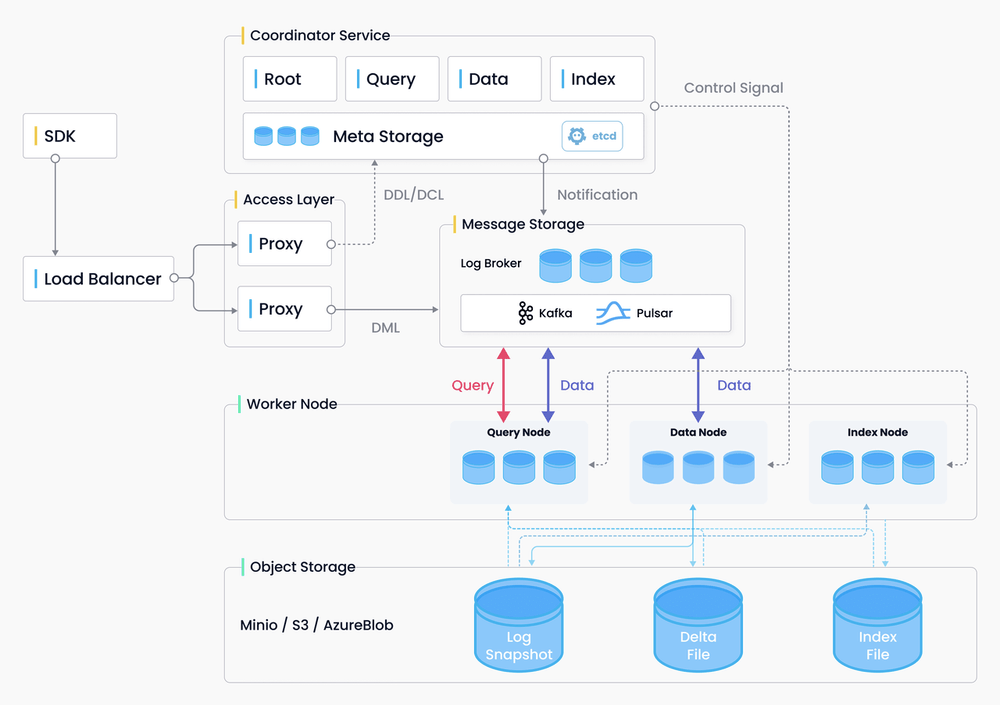
SDK通过负载平衡器向代理(门户)发送数据请求。然后,代理与协调器服务交互,将DDL(数据定义语言)和DML(数据操作语言)请求写入消息存储。
工作节点(包括查询节点、数据节点和索引节点)使用来自消息存储的请求。更具体地说,查询节点负责数据查询;索引节点负责数据插入和数据持久性,索引节点主要处理索引构建和查询加速。
底层是对象存储,它主要利用MinIO、S3和AzureBlob来存储日志、增量binlog和索引文件。
数据插入请求门户
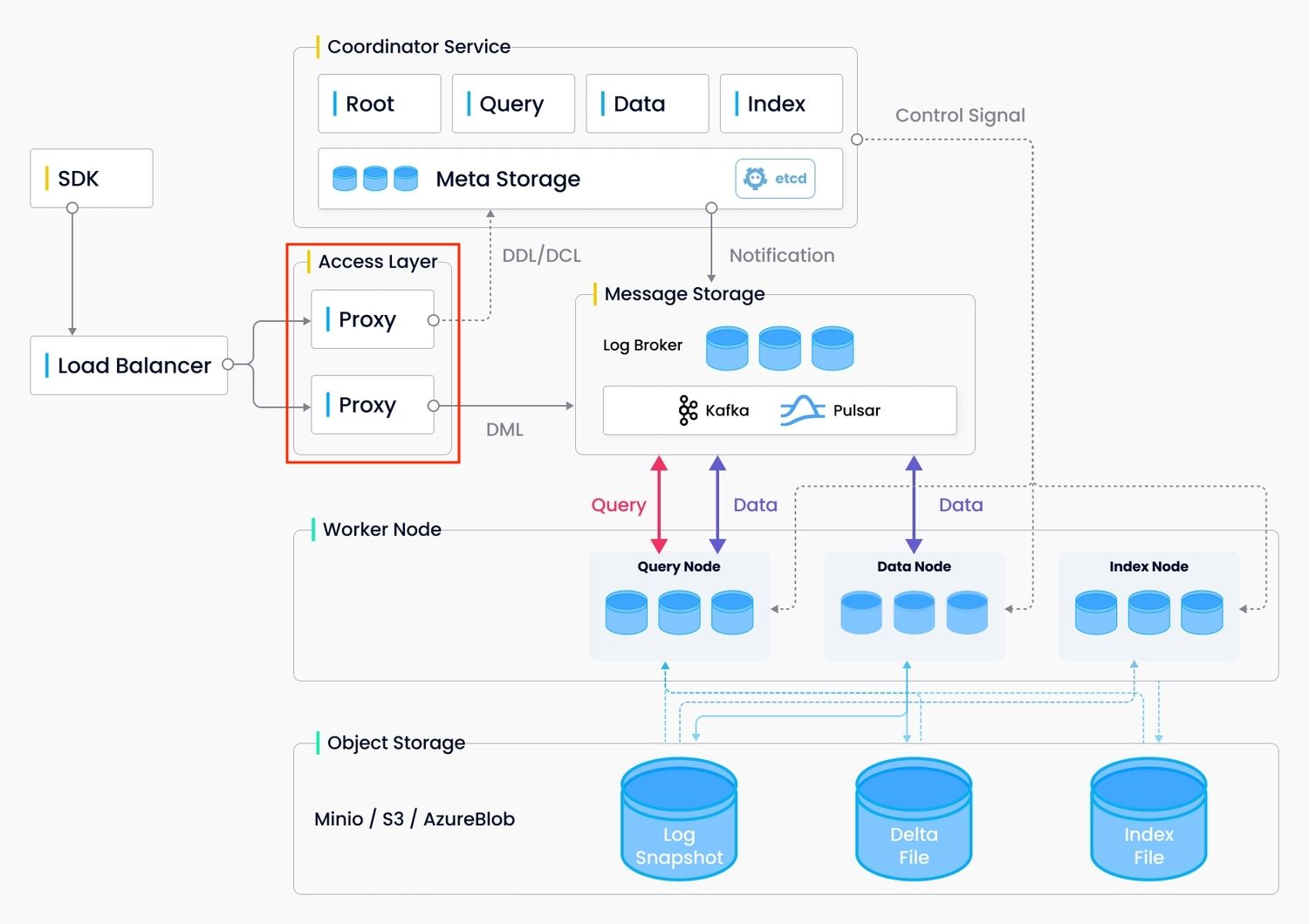
代理充当数据插入请求的门户。
1.最初,代理接受来自SDK的数据插入请求,并使用哈希算法将这些请求分配到多个存储桶中。
2.然后,代理请求数据坐标分配段(Milvus中的最小单元)用于数据存储。
3.之后,代理将请求的段的信息插入消息存储中,这样这些信息就不会丢失。
数据协调和数据节点
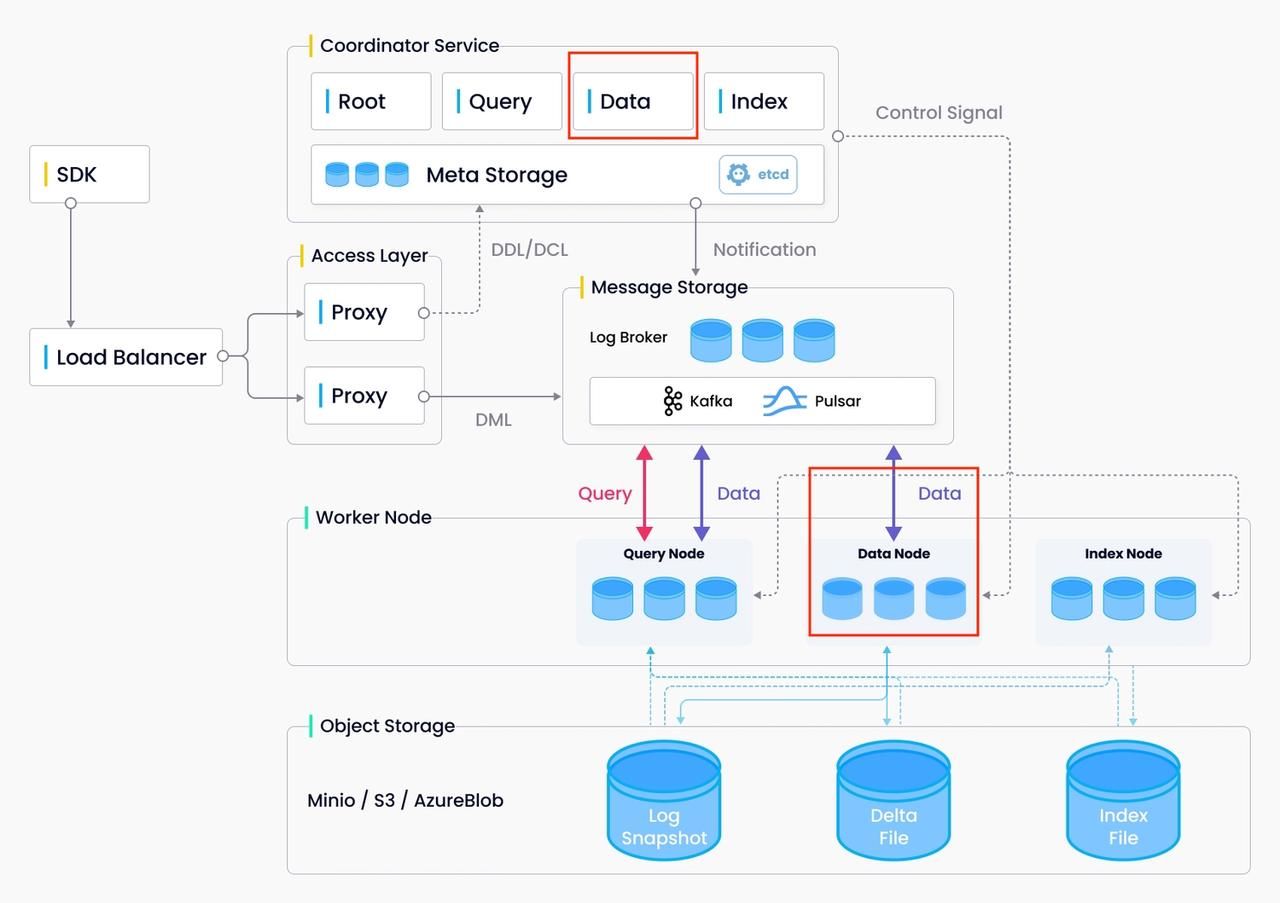
数据协调的主要功能是管理通道和段分配,而数据节点的主要功能是消费和保存插入的数据。
作用
Data coord服务于以下方面:
-
分配段空间数据坐标将增长段中的空间分配给代理,以便代理可以使用段中的可用空间来插入数据。
-
记录段分配和段中分配空间的到期时间。数据坐标分配的每个段内的空间不是永久的。因此,数据坐标还需要记录每个段分配的到期时间。
-
自动刷新段数据如果段已满,数据坐标会自动触发数据刷新。
-
为数据节点分配通道。一个集合可以有多个视频通道。数据坐标确定哪些数据节点使用哪些vchannel。
数据节点服务于以下方面:
-
使用数据数据节点使用数据坐标分配的通道中的数据,并为数据创建序列。
-
数据持久性将插入的数据缓存在内存中,并在数据量达到一定阈值时自动将插入的数据刷新到磁盘。
工作流程
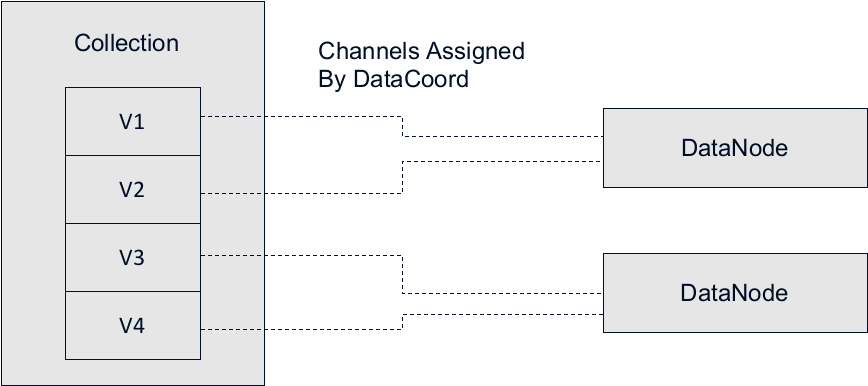
如上图所示,该集合有四个V通道(V1、V2、V3和V4),有两个数据节点。数据坐标可能会分配一个数据节点来使用来自V1和V2的数据,另一个数据节点来自V3和V4。一个vchannel不能分配给多个数据节点,这会防止重复数据消耗,否则会导致同一批数据重复插入同一段。
根坐标和时间刻度
Root coord管理TSO(时间戳Oracle)并在全球发布时间刻度消息。每个数据插入请求都有一个由根坐标分配的时间戳。时间刻度是Milvus的基石,它在Milvus中充当时钟,并表示Milvus系统处于哪个时间点。
当数据写入Milvus时,每个数据插入请求都带有一个时间戳。每次,数据节点在数据消耗期间消耗时间戳在特定范围内的数据。
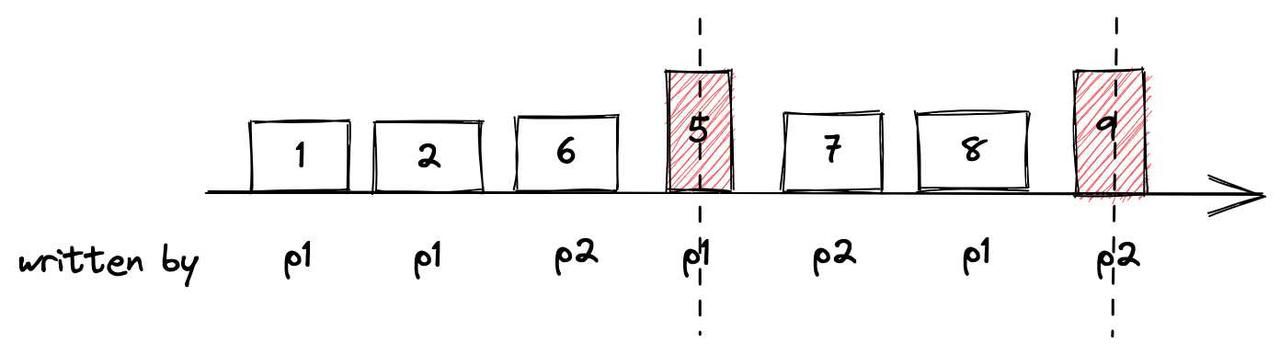
上图是数据插入过程。时间戳的值由数字1,2,6,5,7,8表示。数据由两个代理写入系统:p1和p2。例如,在数据消耗期间,如果时间刻度的当前时间为5,则数据节点只能读取数据1和2。然后,在第二次读取期间,如果时间刻度的当前时间变为9,则数据节点可以读取数据6,7,8。
数据组织:收集、分区、碎片(通道)、段
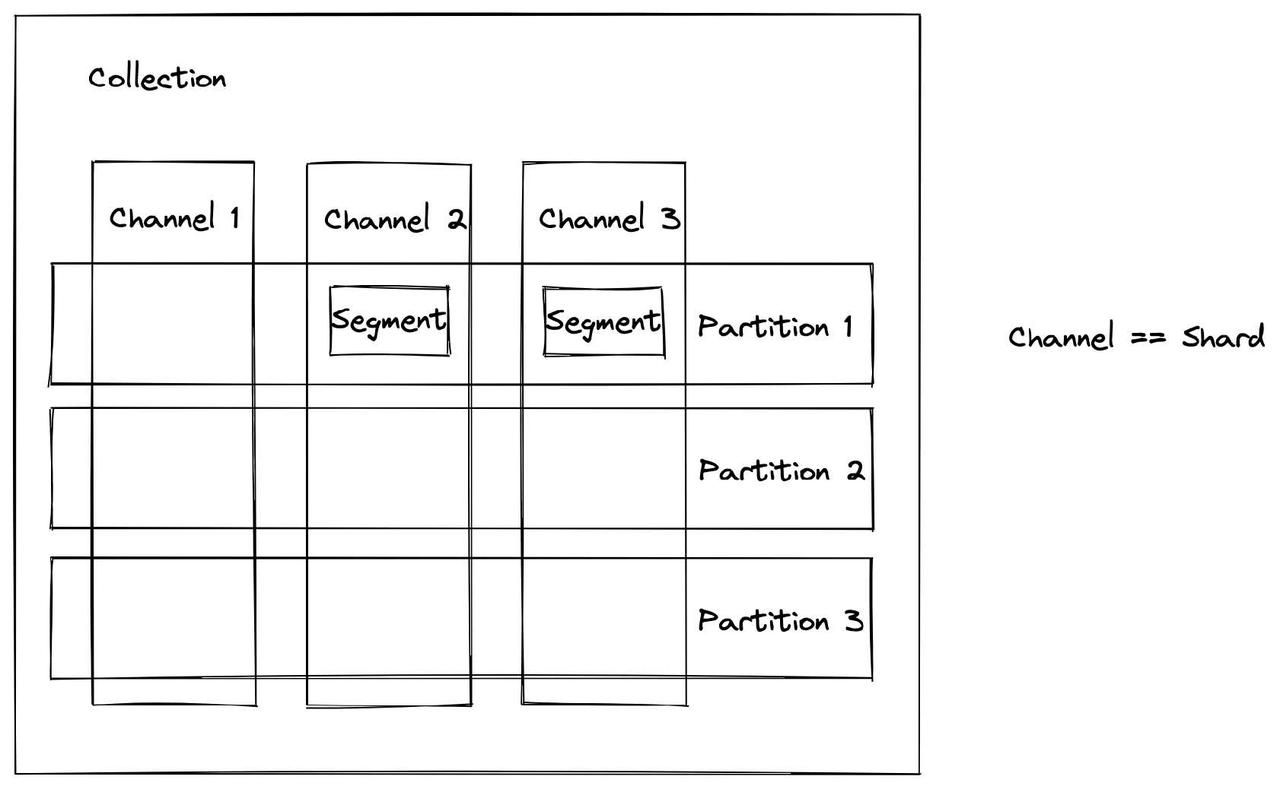
首先阅读本文,了解Milvus中的数据模型以及收集、切分、分区和分段的概念。
总之,Milvus中最重要的数据单元是一个集合,可以将其比作关系数据库中的表。一个集合可以有多个碎片(每个碎片对应一个通道)和每个碎片内的多个分区。上图显示通道(碎片)是垂直条,而分区是水平的。每个交叉点都有段的概念,段是数据分配的最小单位。在Milvus中,索引建立在段上。在查询过程中,Milvus系统还平衡了不同查询节点中的查询负载,该过程是基于段单位进行的。段包含多个binlog,当消耗段数据时,将生成binlog文件。
段
Milvus中有三个不同状态的段:生长段、密封段和冲洗段。
成长中的细分市场
增长段是新创建的段,可以分配给代理以进行数据插入。段的内部空间可以使用、分配或释放。
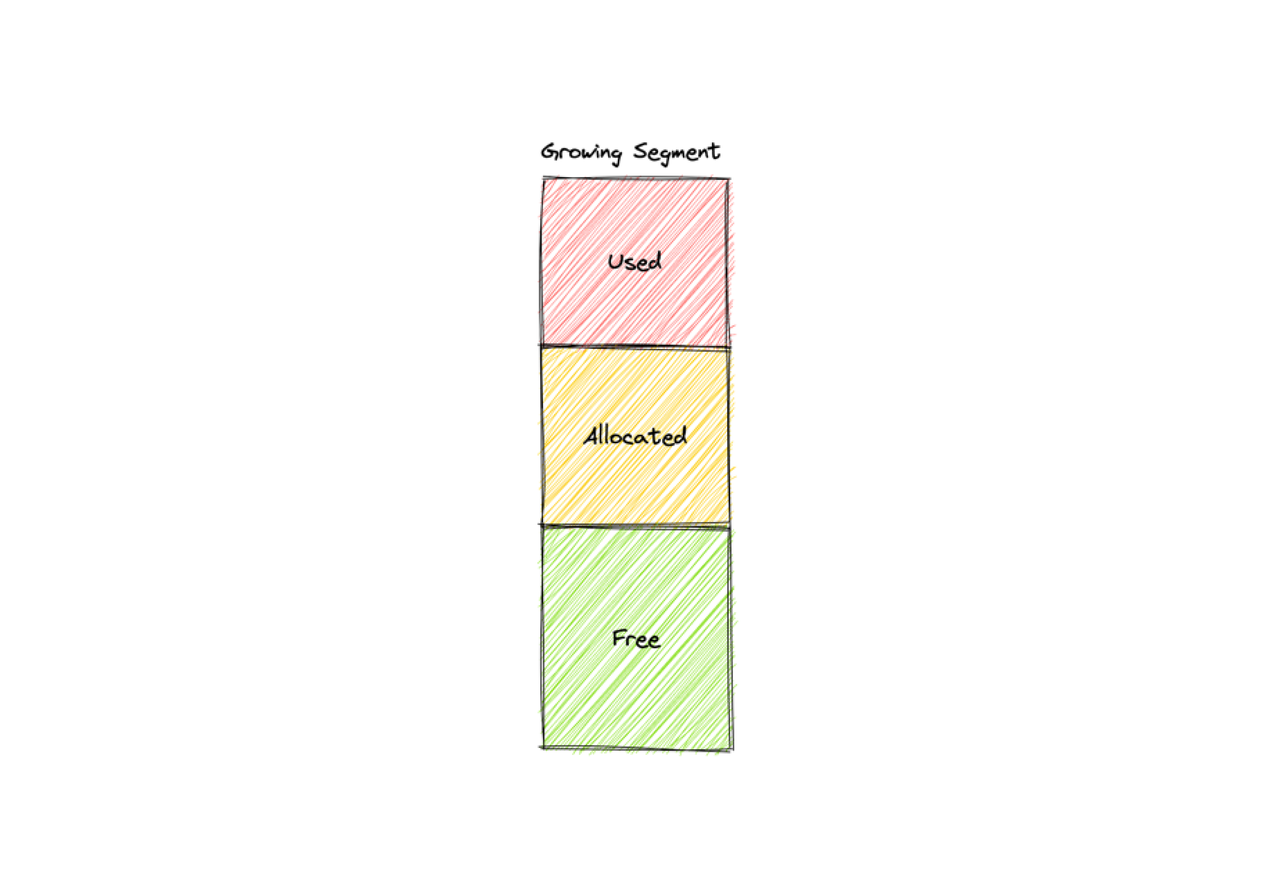
-
已使用:增长段的这部分空间已被数据节点占用。
-
已分配:增长段的这部分空间已由代理请求,并由数据协调员分配。分配的空间将在一段时间后过期。
-
免费:未使用增长段的这部分空间。可用空间的值等于段的总空间减去已使用和已分配空间的值。因此,段的可用空间随着分配的空间过期而增加。
密封段
密封段是一个闭合段,不能再分配给代理进行数据插入。
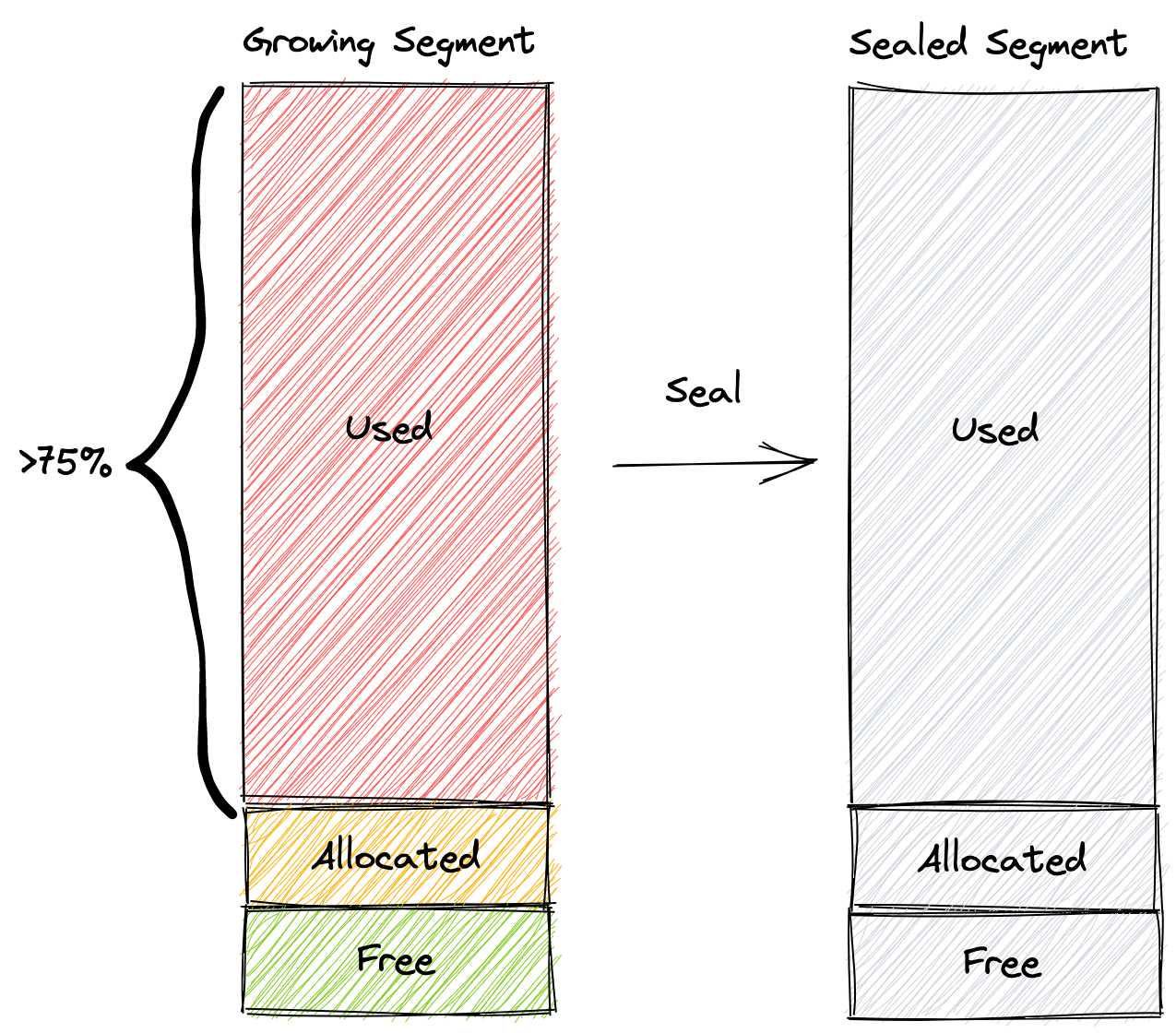
在以下情况下,成长中的细分市场是封闭的:
如果增长段中使用的空间达到总空间的75%,则该段将被密封。
Flush()由Milvus用户手动调用,以持久化集合中的所有数据。
长时间后未密封的增长段将被密封,因为增长段过多会导致数据节点过度消耗内存。
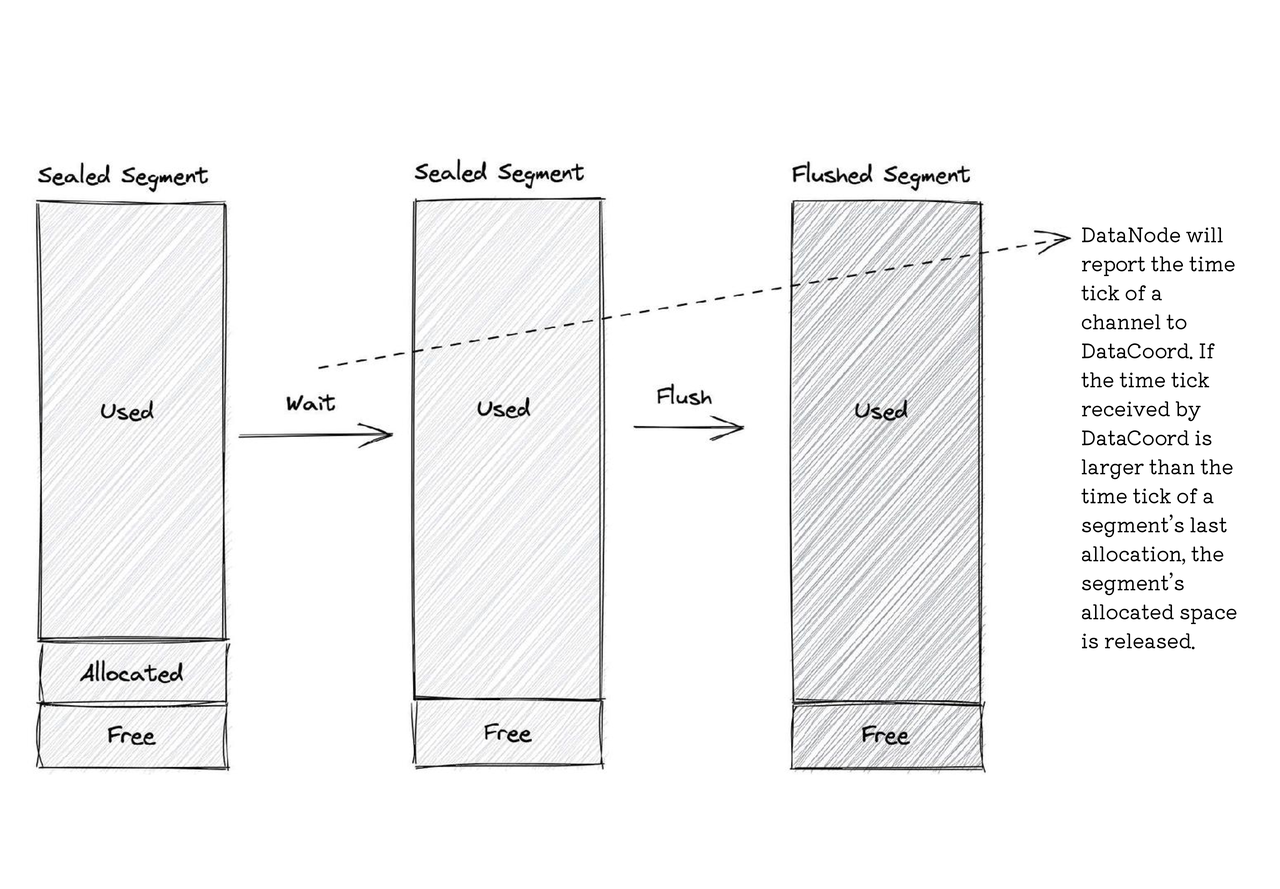
冲洗段
刷新的段是已经写入磁盘的段。Flush是指将段数据存储到对象存储以实现数据持久性。只有当密封段中分配的空间过期时,才能刷新段。冲洗时,密封段变为冲洗段。
频道
分配通道:
-
数据节点启动或关闭时;或
-
当代理请求分配的段空间时。
然后有几种信道分配策略。Milvus支持其中2种策略:
1、一致哈希
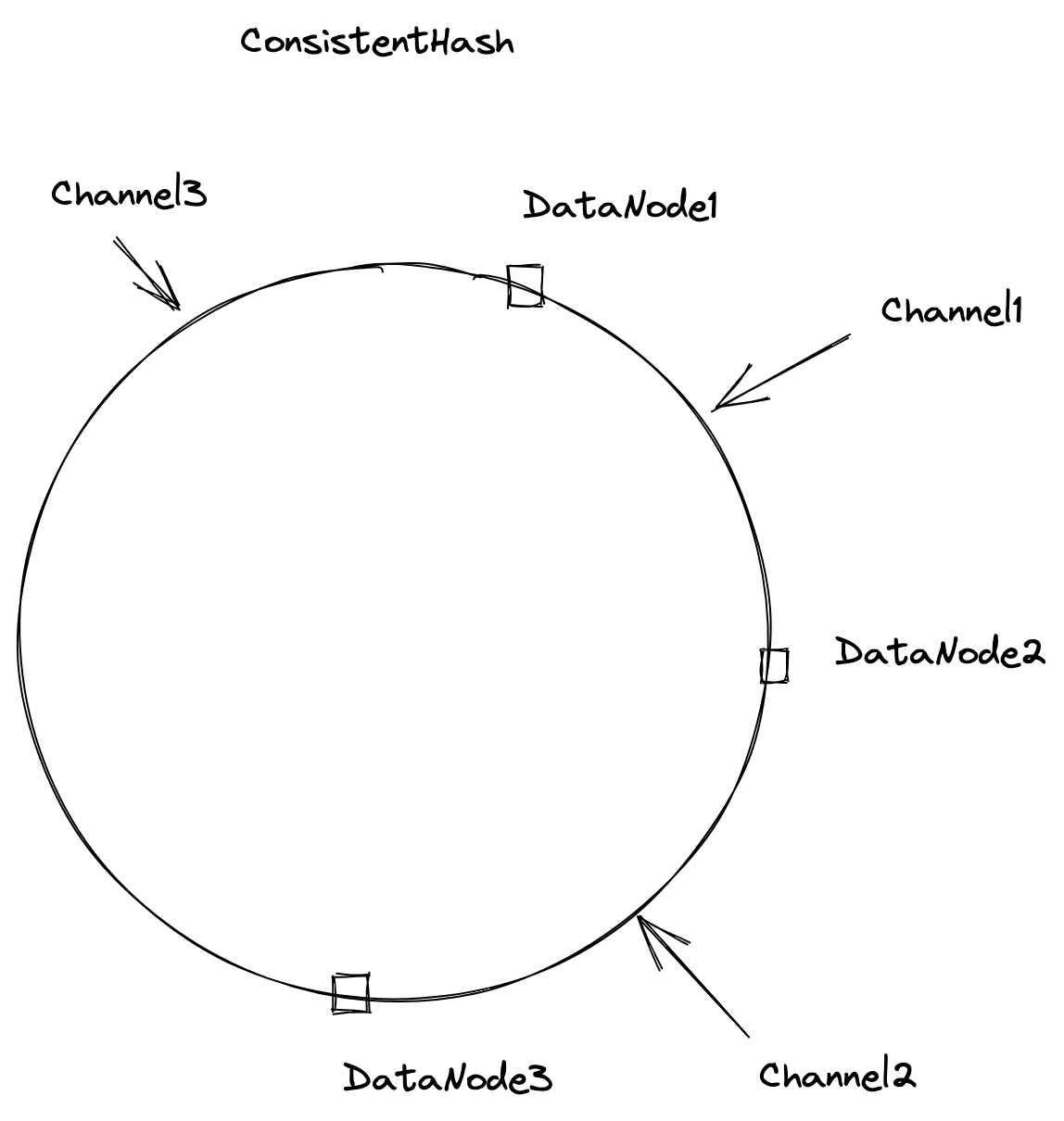
Milvus中的默认策略。该策略利用哈希技术在环上为每个通道分配一个位置,然后沿顺时针方向搜索,以找到距离通道最近的数据节点。因此,在上图中,信道1分配给数据节点2,而信道2分配给数据节点3。
然而,该策略的一个问题是,数据节点数量的增加或减少(例如,新的数据节点启动或数据节点突然关闭)可能会影响信道分配过程。为了解决这个问题,数据协调员通过等监控数据节点的状态,以便在数据节点的状态发生任何变化时可以立即通知数据协调员。然后,数据坐标进一步确定要正确分配信道的数据节点。
2、负载平衡
第二种策略是将相同集合的通道分配给不同的数据节点,确保通道均匀分配。该策略的目的是实现负载平衡。
数据分配:时间和方式
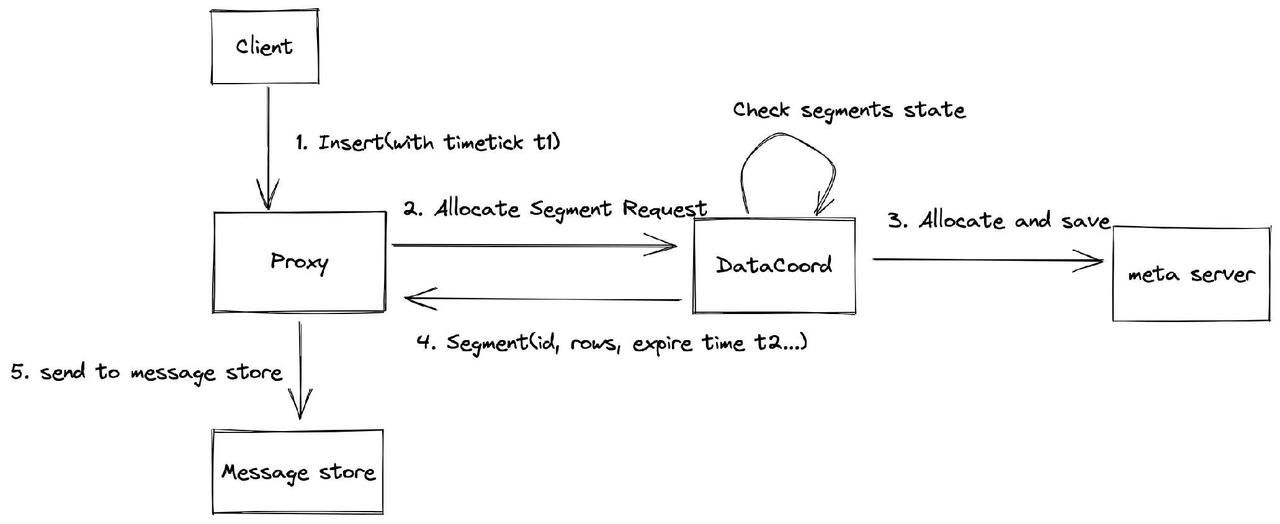
数据分配过程从客户端开始。它首先向代理发送带有时间戳t1的数据插入请求。然后,代理向数据坐标发送请求,以进行段分配。
在收到段分配请求后,数据协调员检查段状态并分配段。如果创建的段的当前空间足以容纳新插入的数据行,则数据坐标会分配这些创建的段。但是,如果当前段中的可用空间不足,数据坐标将分配一个新段。数据坐标可以在每次请求时返回一个或多个段。同时,数据坐标还将分配的段保存在元服务器中,以实现数据持久性。
随后,数据坐标将分配段的信息(包括段ID、行数、到期时间等)返回给代理。代理将分配段的此类信息发送到消息存储,以正确记录此信息。注意,t1的值必须小于t2的值。t2的默认值为2000毫秒,可以通过配置参数段进行更改。数据坐标中的assignmentExpiration。yaml文件。
Binlog文件结构和数据持久性
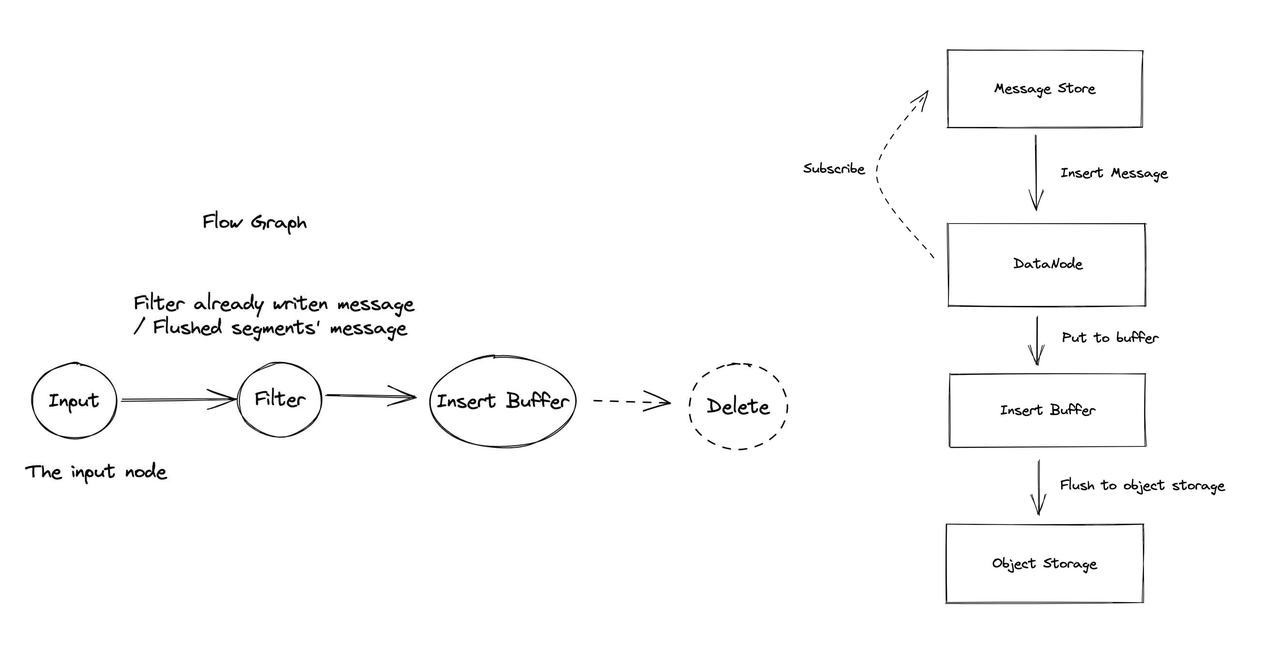
数据节点订阅消息存储,因为数据插入请求保存在消息存储中,因此数据节点可以使用插入消息。数据节点首先将插入请求放在插入缓冲区中,随着请求的累积,它们将在达到阈值后刷新到对象存储中。
Binlog文件结构

Milvus中的binlog文件结构与MySQL中的相似。Binlog用于实现两个功能:数据恢复和索引建立。
binlog包含许多事件。每个事件都有一个事件头和事件数据。
元数据(包括binlog创建时间、写入节点ID、事件长度、NextPosition(下一个事件的偏移量)等)写入事件头中。
事件数据可以分为两部分:固定和可变。
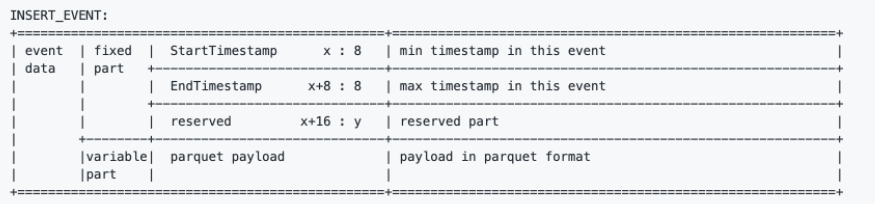
INSERT_EVENT的事件数据中的固定部分包含StartTimestamp、EndTimestamp和reserved。
可变零件存储插入的数据。插入数据按拼花格式排序并存储在此文件中。
数据持久层
如果模式中有多个列,Milvus将在列中存储binlog。
INSERT\u事件的事件数据中的固定部分包含StartTimestamp、EndTimestamp和reserved。
可变零件存储插入的数据。插入数据按拼花格式排序并存储在此文件中。
数据持久层
如果模式中有多个列,Milvus将在列中存储binlog。
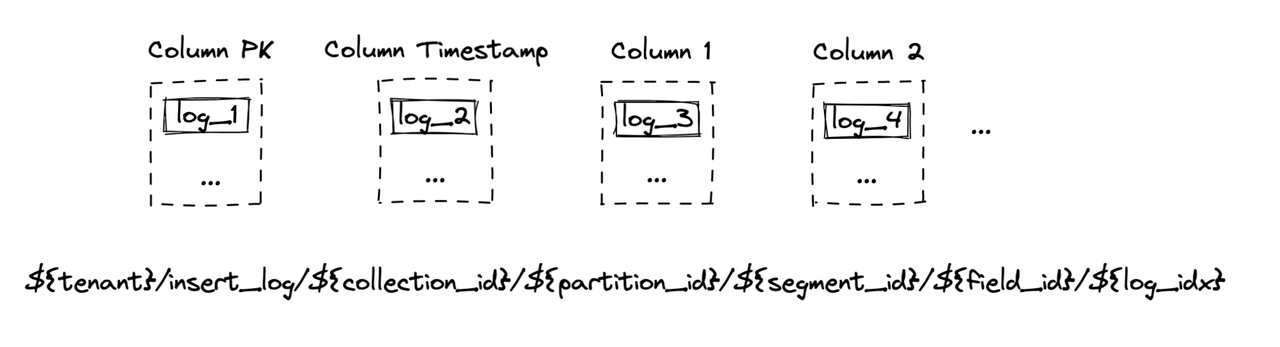
如上图所示,第一列是主键binlog。第二个是时间戳列。其余的是模式中定义的列。MinIO中binlog的文件路径也显示在上图中。
接下来是什么?
随着Milvus 2.0正式发布,我们精心策划了这个Milvus Deep Dive博客系列,以提供对Milvus架构和源代码的深入解释。本系列博客涵盖的主题包括:
-
Milvus架构概述
-
API和Python SDK
-
数据处理
-
数据管理
-
实时查询
-
标量执行引擎
-
QA系统
-
Milvus_Cli和Attu
-
矢量执行引擎
原文标题:Data Insertion and Data Persistence in a Vector Database
原文作者:Angela Ni
原文链接:https://dzone.com/articles/data-insertion-and-data-persistence-in-a-vector-da
评论

 0 点赞
0 点赞


