




初学TiDB,先从基本的框架入手了解TiDB各个基础组件的功能,看看它们在TiDB集群承担的工作职责。
整个TiDB集群基础的架构,如图:
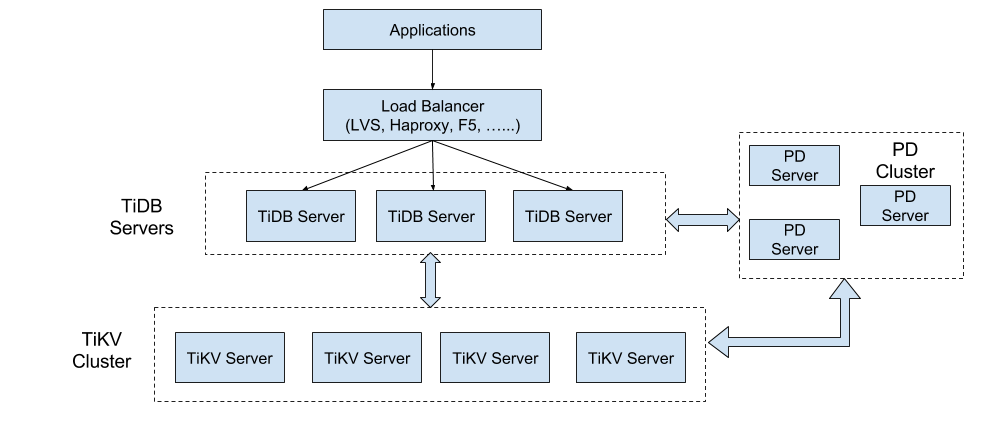
-
TiDB Servers:
TiDB是无状态的SQL层,应用层可以通过Haproxy、LVS、Nginx反向代理、F5等软硬件负载均衡产品将请求均衡的分配给多个TiDB实例。TiDB实例对SQL语句进行解析并生成分布式执行计划后,会将实际的数据请求下发到数据层(TiKV)。TiDB集群中各个节点相互独立,一个节点挂了不会影响其他节点。TiDB Servers不存储数据,兼容MySQL协议。 -
PD Cluster:
PD 是 TiDB 集群的管理模块,同时也负责集群数据的实时调度,可以说是整个TiDB集群的大脑,大致有如下功能:
1)收集并存储集群的元数据,比如Region处于哪些TIKV上。
2)调度和负载均衡Region,比如把Region调度到另外几个TIKV上,或者把Raft leader迁移给另一个Flower。
3)负责分配全局单调递增的时间戳。 -
TiKV Cluster:
TiKV是TiDB集群的存储层,通过 Key-Value 模型保存数据,并且提供有序遍历方法。TiKV以Region为单位,将数据分散在集群中所有的节点上。TiKV并不直接向磁盘写数据,而是使用Facebook的开源项目RocksDB单机KV存储引擎保存数据。TiKV使用Raft一致性协议将数据复制到raft group中每一个成员中,以防单机失效,在写入数据时只要多数成员返回成功就认为数据写入成功。
TiDB 4.0后 Realtime HTAP 形态架构图如下:
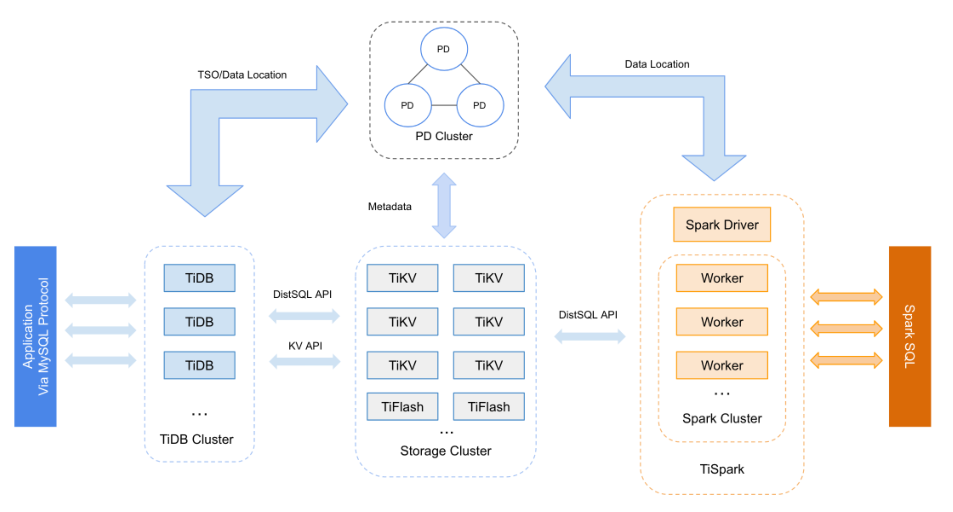
-
TiFlash:
TiFlash 是 TiDB 为完善 Realtime HTAP 形态引入的关键组件, TiFlash 通过 Multi-Raft Learner 协议实时从 TiKV 复
制数据,确保行存储引擎 TiKV 和列存储引擎 TiFlash 之间的数据强一致。 TiKV 、 TiFlash 可按需部署在不同
的机器,解决 HTAP 资源隔离的问题。TiFlash是列式存储引擎,适合分析处理。 -
TiSpark:
TiSpark是将Spark SQL 直接运行在 TIKV上 的OLAP解决方案。从数据集群的角度看,TiSprk+TIDB可以让用户无需进行脆弱和难以维护的etl,直接在同一平台进行事务和分析两种操作,简化了系统架构和运维。
