




众所周知,在分布式数据库中,除了本身的基础性能外,最重要的就是充分利用所有节点能力,避免让单个节点成为瓶颈。但随着业务场景的复杂性,各节点上的数据读写访问热度,总是无法保证均衡的,热点现象就此产生。严重的热点问题,会导致单个节点成为资源瓶颈,进而影响整个系统的吞吐能力。如果不能很好的解决热点问题,数据库的水平扩展能力及稳定性也就无法得到保障。TiDB 作为一个分布式数据库,虽然会自动且动态的进行数据的重新分布以到达尽可能的均衡,但是有时候由于业务特性或者业务负载的突变,仍然会产生热点,这时候往往就会出现性能瓶颈。
1. 确认热点问题
通过TIDB的Grafana监控工具确认集群是不是存在热点问题:
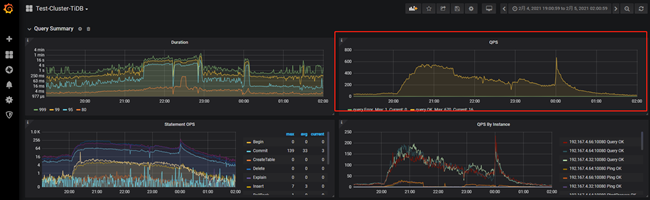
在Cluster-TiDB的Query Summary面板中发现,在20:00和00:00两个时间段出现了访问高峰。
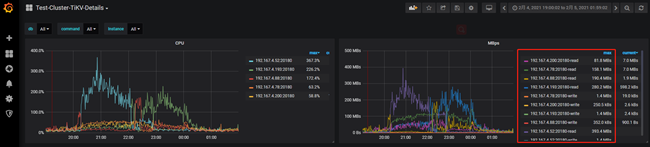
在Cluster-TiKV-Details的Cluster面板中发现查询的请求的CPU和流量消耗都集中出现在一台tikv节点。
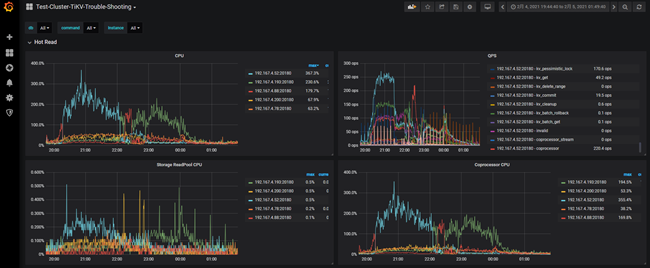
在TiKV-Trouble-Shooting的Hot Read面板中也可以发现资源消耗都集中在一台tikv节点上,并且都是Coprocessor线程消耗了CPU资源。
#注Coprocessor线程是处理TIDB计算节点将计算任务下推到tikv节点的线程,具体可参考 https://pingcap.com/blog-cn/tikv-source-code-reading-14/
2. 定位热点表/索引(Region)
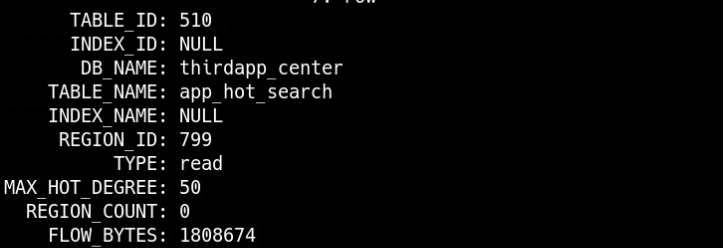
通过在热点现场SQL查询 information_schema.TIDB_HOT_REGIONS 表定位热点表/索引(Region)。
MySQL [information_schema]> select * from information_schema.TIDB_HOT_REGIONS where type = ‘read’\G
也可以通过pd-ctl工具查看到查询读、写流量最大的Region
$ pd-ctl -u http://{pd}:2379 -d region topread [limit]
$ pd-ctl -u http://{pd}:2379 -d region topwrite [limit]
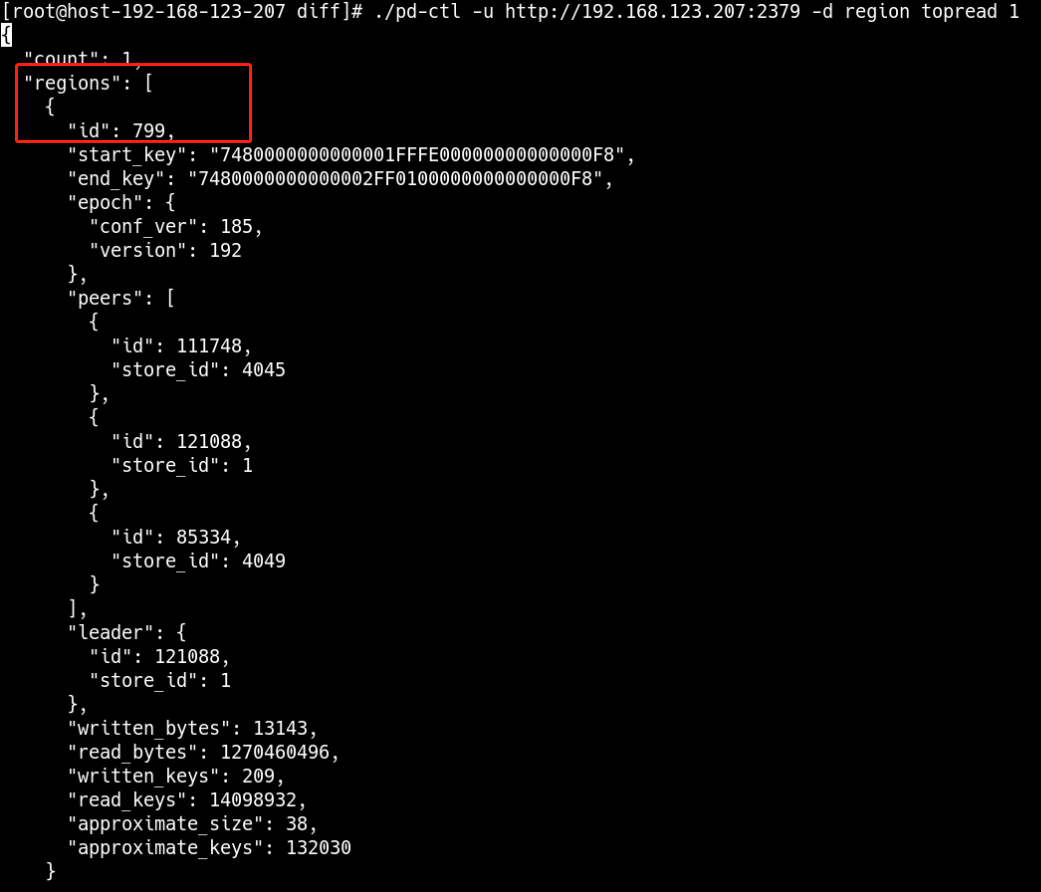
再从 Region ID 定位到表或索引
$ curl http://{TiDBIP}:10080/regions/{RegionId}
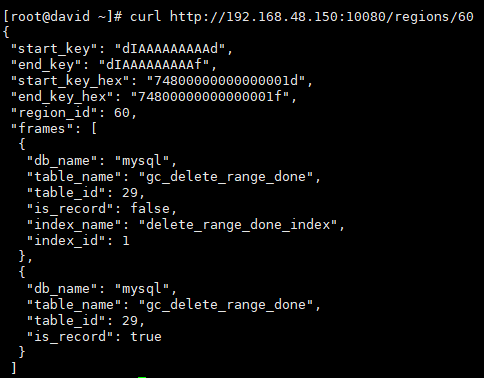
#注:因系统环境问题,此图在测试环境抓取,仅展示命令的功能。
至此已查询到热点的表和对应的region,后续可根据热点表表结构和业务沟通改造方案。
3. 建议
1、在新建表时通过设置SHARD_ROW_ID_BITS参数在尽量避免热点问题,官方文档对该参数的介绍如下:
对于主键非整数或没有主键的表或者是联合主键, TiDB 会使用一个隐式的自增 RowID ,大量 INSERT 时会把数 据集中写入单个 Region ,造成写入热点。 通过设置 SHARD_ROW_ID_BITS ,可以把 RowID 打散写入多个不同的 Region ,缓解写入热点问题。但是设置的过大 会造成 RPC 请求数放大,增加 CPU 和网络开销。 349 SHARD_ROW_ID_BITS = 4 表示 16 个分片 \ SHARD_ROW_ID_BITS = 6 表示 64 个分片 \ SHARD_ROW_ID_BITS = 0 表示默认值 1 个分片 语句示例: CREATE TABLE : CREATE TABLE t (c int) SHARD_ROW_ID_BITS = 4; ALTER TABLE : ALTER TABLE t SHARD_ROW_ID_BITS = 4; SHARD_ROW_ID_BITS 的值可以动态修改,每次修改之后,只对新写入的数据生效。 TiDB alter-primary-key 参数设置为 false 时,会使用表的整数型主键作为 RowID ,因为 SHARD_ROW_ID_BITS 会 改变 RowID 生成规则,所以此时无法使用 SHARD_ROW_ID_BITS 选项。在 alter-primary-key 参数设置为 true 时, TiDB 在建表时不再使用整数型主键作为 RowID ,此时带有整数型主键的表也可以使用 SHARD_ROW_ID_BITS 特 性。复制
2、通过手动split region拆分热点region。
3、在TIDB4.0中,PD 会提供 Load Base Splitting 策略,除了根据 Region 的大小进行 Region 分裂之外,还会根据访
问 QPS 负载自动分裂频繁访问的小表的 Region



