




这是博客系列的第二部分,通过Kafka和Kafka Connect逐步介绍数据管道。我将使用AWS进行演示,但这些概念适用于任何等效选项(例如,在Docker中本地运行这些选项)。
本部分将展示实际的更改数据捕获,它允许您跟踪数据库表中的行级更改,以响应创建、更新和删除操作。例如,在MySQL中,这些更改数据事件通过MySQL二进制日志(binlog)公开。
在第1部分中,我们在数据管道的源部分使用了Datagen连接器,它帮助我们为MSK主题生成模拟数据,并使事情变得简单。我们将使用Aurora MySQL作为数据源,并利用其更改数据捕获功能和Debezium connector for MySQL从Aurora MySQL中的表中实时提取数据,并将其推送到MSK主题。然后,我们将继续像以前一样使用DynamoDB接收器连接器。
如果你是Debezium的新手…
它是一个分布式平台,构建在不同数据库中可用的更改数据捕获功能之上。它提供了一组Kafka Connect连接器,用于接入数据库表中的行级更改(使用CDC),并将其转换为事件流。这些文件被发送到卡夫卡,并可供所有下游应用程序使用。
这是本博客文章中提出的解决方案的高级图表。
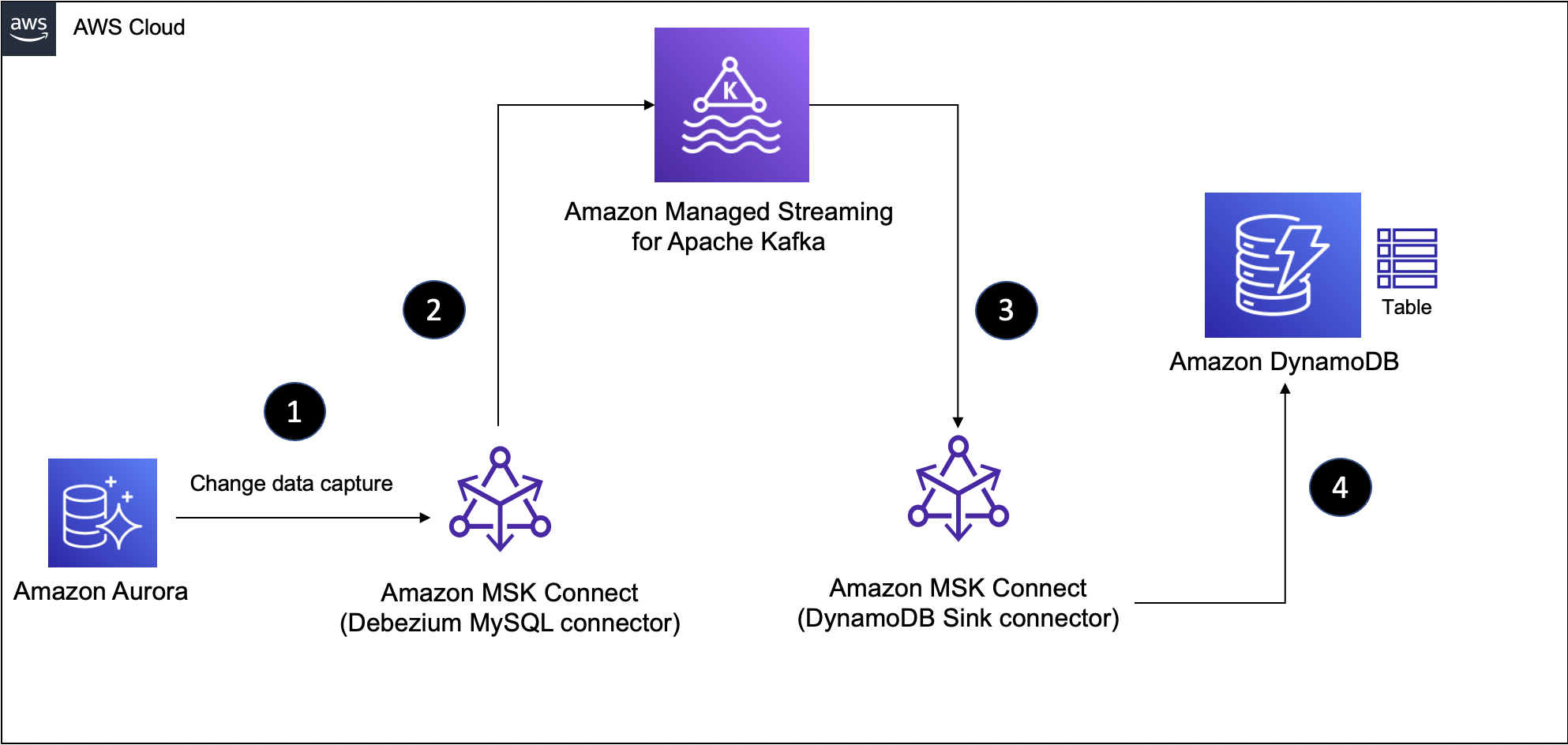
我假设您遵循第1部分的内容,其中已经介绍了本教程所需的基本基础设施和服务的创建过程。如果您还没有,请参阅第1部分中的“准备基础设施组件和服务”一节
数据管道第1部分:Aurora MySQL到MSK
我们先创建管道的前半部分,将Aurora MySQL表中的数据同步到MSK中的主题。
在本节中,您将:
-
下载Debezium连接器工件
-
在MSK中创建自定义插件
-
将Debezium源连接器部署到MSK Connect
最后,您将准备好数据管道的前一半!
创建自定义插件和连接器
将Debezium连接器上载到Amazon S3
登录Kafka客户端EC2实例并运行以下命令:
sudo -u ec2-user -i
mkdir debezium && cd debezium
wget https://repo1.maven.org/maven2/io/debezium/debezium-connector-mysql/1.9.0.Final/debezium-connector-mysql-1.9.0.Final-plugin.tar.gz
tar xzf debezium-connector-mysql-1.9.0.Final-plugin.tar.gz
cd debezium-connector-mysql
zip -9 ../debezium-connector-mysql-1.9.0.Final-plugin.zip *
cd ..
aws s3 cp ./debezium-connector-mysql-1.9.0.Final-plugin.zip s3://msk-lab-<ENTER_YOUR_AWS_ACCOUNT_ID>-plugins-bucket/
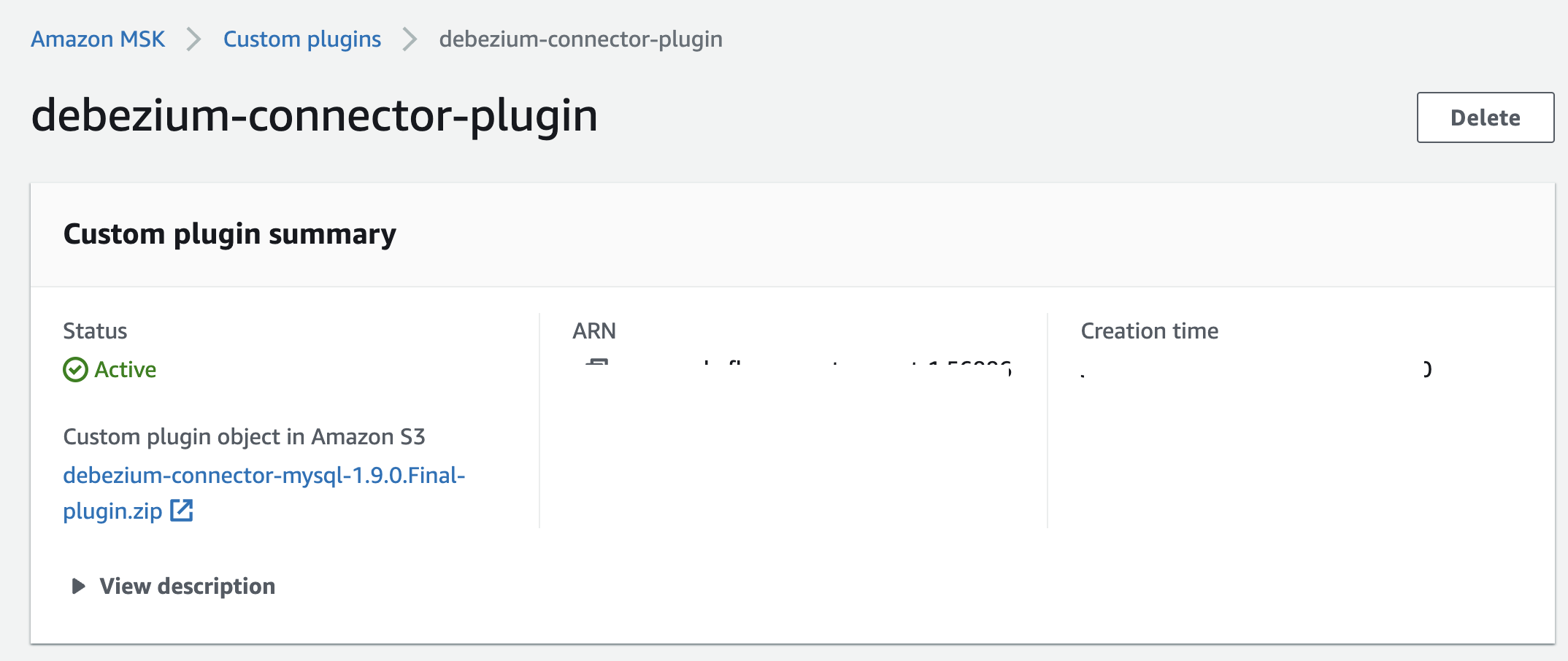
创建自定义插件
有关如何创建MSK Connect插件的分步说明,请参阅官方文档中的使用AWS管理控制台创建自定义插件。
在创建自定义插件时,请确保选择在上一步中上载到S3的Debezium连接器zip文件。
创建Debezium源连接器
有关如何创建MSK Connect连接器的分步说明,请参阅官方文档中的创建连接器。
要创建连接器,请执行以下操作:
1.选择您刚刚创建的插件。
2.输入连接器名称并选择MSK群集和IAM身份验证
3.您可以在连接器配置部分输入以下提供的内容。确保根据设置更换以下配置:
4.database.history.kafka.bootstrap.servers—独自创立服务器-输入MSK群集端点
5.数据库主机名-输入Aurora RDS MySQL端点
保持其余配置不变
connector.class=io.debezium.connector.mysql.MySqlConnector
database.user=master
database.server.id=123456
tasks.max=1
database.history.kafka.topic=dbhistory.salesdb
database.history.kafka.bootstrap.servers=<ENTER MSK CLUSTER ENDPOINT>
database.server.name=salesdb
database.port=3306
include.schema.changes=true
database.hostname=<ENTER RDS MySQL ENDPOINT>
database.password=S3cretPwd99
database.include.list=salesdb
value.converter.schemas.enable=false
key.converter.schemas.enable=false
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
database.history.consumer.security.protocol=SASL_SSL
database.history.consumer.sasl.mechanism=AWS_MSK_IAM
database.history.consumer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
database.history.consumer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
database.history.producer.security.protocol=SASL_SSL
database.history.producer.sasl.mechanism=AWS_MSK_IAM
database.history.producer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
database.history.producer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
transforms=unwrap
transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
1.在“访问权限”下,为连接器选择正确的IAM角色(名称中包含AuroraConnectorIAMRole的角色)
2.单击“下一步”移动到安全选项-保持不变
3.单击“下一步”。对于日志交付,请选择交付到Amazon CloudWatch日志。定位并选择/msk连接演示cwlog组
4.单击下一步-在最后一页上,向下滚动并单击创建连接器以启动该过程,并等待连接器启动。
完成后,连接器转换到运行状态,继续执行以下步骤。
测试管道
我们想确认salesdb数据库中SALES_ORDER表中的记录是否已推送到MSK主题。为此,从EC2主机上运行Kafka CLI consumer。
注意主题名salesdb。salesdb。SALES_订单-这符合Debezium约定。
sudo -u ec2-user -i
export MSK_BOOTSTRAP_ADDRESS=<ENTER MSK CLUSTER ENDPOINT>
/home/ec2-user/kafka/bin/kafka-console-consumer.sh --bootstrap-server $MSK_BOOTSTRAP_ADDRESS --consumer.config /home/ec2-user/kafka/config/client-config.properties --from-beginning --topic salesdb.salesdb.SALES_ORDER | jq --color-output .
在另一个终端中,使用MySQL客户端并连接到Aurora数据库并插入一些记录:
sudo -u ec2-user -i
export RDS_AURORA_ENDPOINT=<ENTER RDS MySQL ENDPOINT>
mysql -f -u master -h $RDS_AURORA_ENDPOINT --password=S3cretPwd99
USE salesdb;
select * from SALES_ORDER limit 5;
INSERT INTO SALES_ORDER (ORDER_ID, SITE_ID, ORDER_DATE, SHIP_MODE) VALUES (29001, 2568, now(), 'STANDARD');
INSERT INTO SALES_ORDER (ORDER_ID, SITE_ID, ORDER_DATE, SHIP_MODE) VALUES (29002, 1649, now(), 'ONE-DAY');
INSERT INTO SALES_ORDER (ORDER_ID, SITE_ID, ORDER_DATE, SHIP_MODE) VALUES (29003, 3861, now(), 'TWO-DAY');
INSERT INTO SALES_ORDER (ORDER_ID, SITE_ID, ORDER_DATE, SHIP_MODE) VALUES (29004, 2568, now(), 'STANDARD');
INSERT INTO SALES_ORDER (ORDER_ID, SITE_ID, ORDER_DATE, SHIP_MODE) VALUES (29005, 1649, now(), 'ONE-DAY');
INSERT INTO SALES_ORDER (ORDER_ID, SITE_ID, ORDER_DATE, SHIP_MODE) VALUES (29006, 3861, now(), 'TWO-DAY');
如果一切设置正确,您应该可以在消费终端中看到记录。
{
"ORDER_ID": 29001,
"SITE_ID": 2568,
"ORDER_DATE": 1655279536000,
"SHIP_MODE": "STANDARD"
}
{
"ORDER_ID": 29002,
"SITE_ID": 1649,
"ORDER_DATE": 1655279536000,
"SHIP_MODE": "ONE-DAY"
}
{
"ORDER_ID": 29003,
"SITE_ID": 3861,
"ORDER_DATE": 1655279563000,
"SHIP_MODE": "TWO-DAY"
}
...
压缩更改事件有效负载的秘密
请注意,更改数据捕获事件负载是多么紧凑。这是因为我们将连接器配置为使用io。德贝齐姆。变换。ExtractNewRecordState是一种Kafka单消息转换(SMT)。默认情况下,Debezium更改事件结构相当复杂-与更改事件一起,它还包括元数据,如模式、源数据库信息等。它看起来像这样:
{
"before": null,
"after": {
"ORDER_ID": 29003,
"SITE_ID": 3861,
"ORDER_DATE": 1655279563000,
"SHIP_MODE": "TWO-DAY"
},
"source": {
"version": "1.9.0.Final",
"connector": "mysql",
"name": "salesdb",
"ts_ms": 1634569283000,
"snapshot": "false",
"db": "salesdb",
"sequence": null,
"table": "SALES_ORDER",
"server_id": 1733046080,
"gtid": null,
"file": "mysql-bin-changelog.000003",
"pos": 43275145,
"row": 0,
"thread": null,
"query": null
},
"op": "c",
"ts_ms": 1655279563000,
"transaction": null
...
多亏了Kafka SMT(使用transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState指定),我们可以有效地展平事件负载,并根据需要进行定制。
有关详细信息,请参阅Debezium文档中的新记录状态提取。
数据管道第2部分:MSK到DynamoDB
现在,我们可以将重点转移到管道的另一半,该管道负责在DynamoDB接收器连接器的帮助下将数据从MSK主题提取到DynamoDB表。
如果DynamoDB表不存在,连接器会自动为您创建一个,但它使用默认设置,即在配置模式下创建一个表,其中包含10个读取容量单元(RCU)和10个写入容量单元(WCU)。
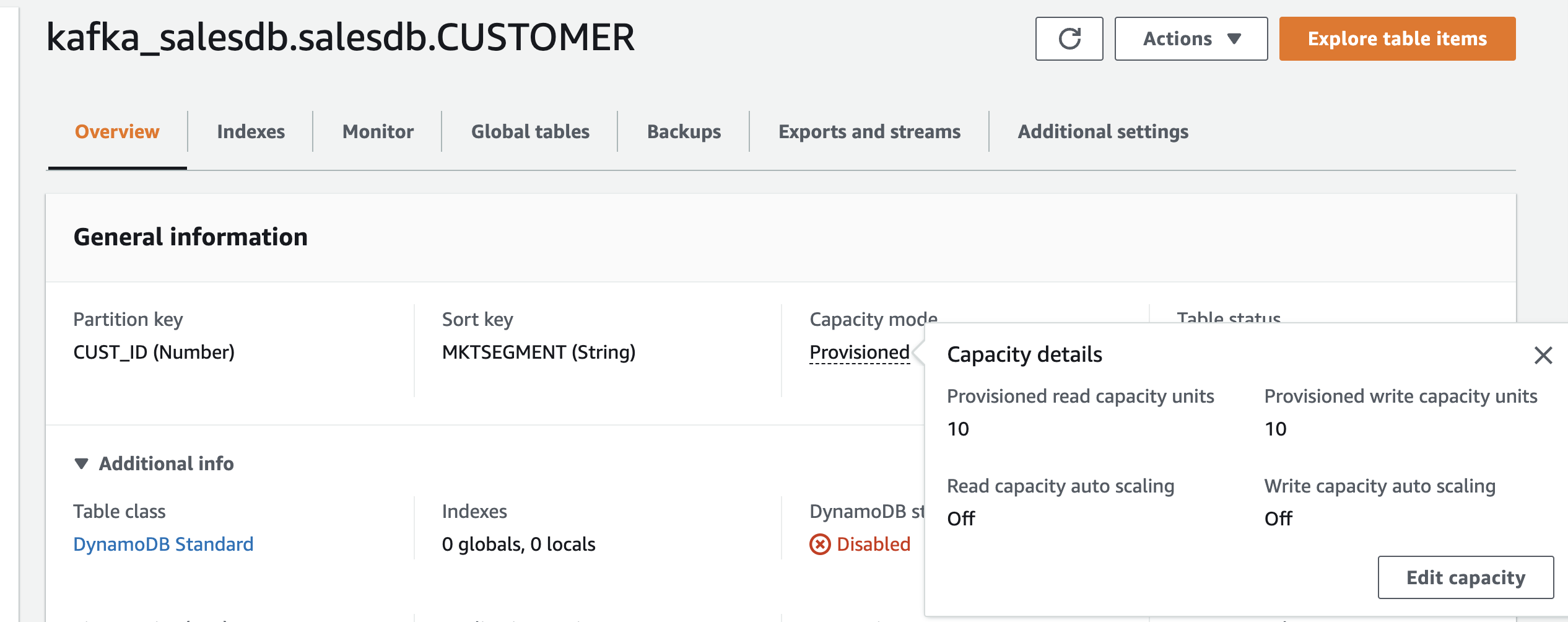
但是您的用例可能需要配置。例如,为了处理大量数据,您可能需要配置自动缩放,或者更好地为您的表激活按需模式。
这正是我们要做的。
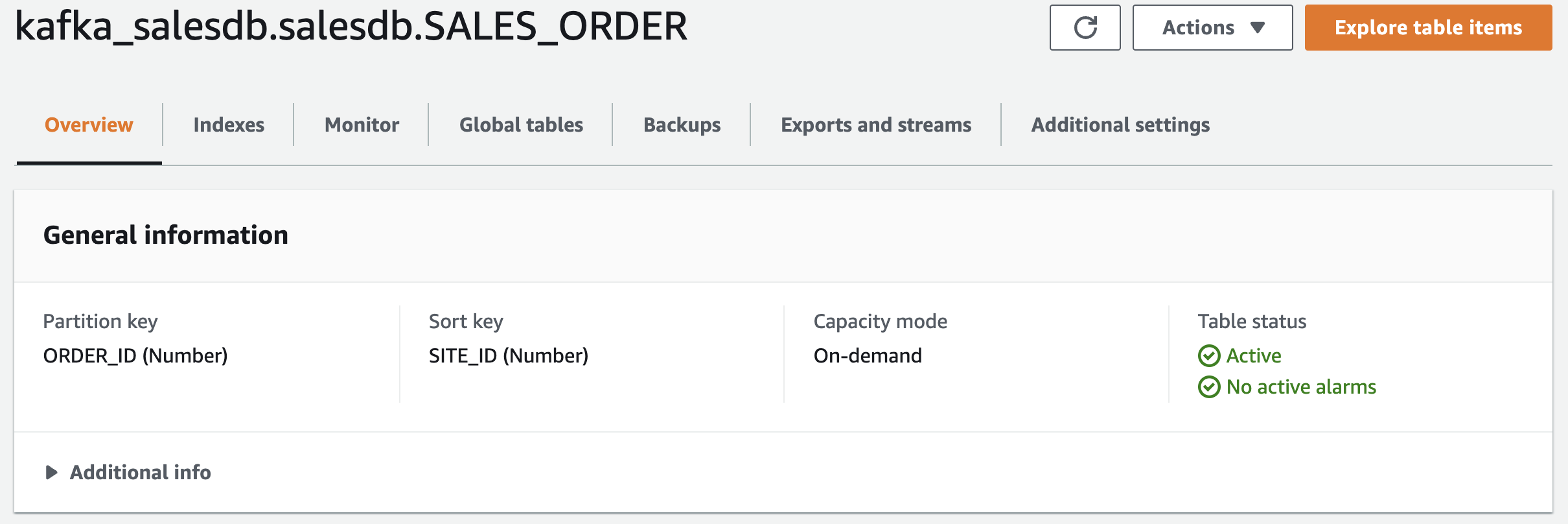
在继续之前,创建DynamoDB表
使用以下设置:
-
表名-kafka_salesdb。salesdb。SALES_ORDER(不更改表名)
-
分区键-ORDER_ID(Number)
-
范围键-SITE_ID(数字)
-
容量模式-按需
创建自定义插件和连接器
有关如何创建MSK Connect插件的分步说明,请参阅官方文档中的使用AWS管理控制台创建自定义插件。
在创建自定义插件时,请确保选择在上一步中上载到S3的DynamoDB连接器zip文件。
有关如何创建MSK Connect连接器的分步说明,请参阅官方文档中的创建连接器。
要创建连接器,请执行以下操作:
1.选择您刚刚创建的插件。
2.输入连接器名称并选择MSK群集和IAM身份验证
3.您可以在连接器配置部分输入以下提供的内容。确保根据设置更换以下配置:
-
为topics属性使用正确的主题名(在本例中,我们使用的是salesdb.salesdb.SALES_ORDER,因为这是Debezium源连接器采用的主题名格式)
-
用于汇流。话题独自创立服务器,输入MSK群集端点
-
适用于aws。发电机B。端点和aws。发电机B。区域,输入创建DynamoDB表的区域,例如us-east-1
保持其余配置不变。
connector.class=io.confluent.connect.aws.dynamodb.DynamoDbSinkConnector
tasks.max=2
aws.dynamodb.region=<ENTER AWS REGION e.g. us-east-1>
aws.dynamodb.endpoint=https://dynamodb.<ENTER AWS REGION>.amazonaws.com
topics=salesdb.salesdb.SALES_ORDER
value.converter.schemas.enable=false
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
table.name.format=kafka_${topic}
confluent.topic.bootstrap.servers=<ENTER MSK CLUSTER ENDPOINT>
confluent.topic.security.protocol=SASL_SSL
confluent.topic.sasl.mechanism=AWS_MSK_IAM
confluent.topic.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
confluent.topic.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
aws.dynamodb.pk.hash=value.ORDER_ID
aws.dynamodb.pk.sort=value.SITE_ID
1.在“访问权限”下,为连接器选择正确的IAM角色(名称中包含DynamoDBConnectorIAMRole的角色)
2.单击“下一步”移动到安全选项-保持不变
3.单击“下一步”。对于日志交付,请选择交付到Amazon CloudWatch日志。定位并选择/msk连接演示cwlog组
4.单击下一步-在最后一页上,向下滚动并单击创建连接器以启动该过程,并等待连接器启动。
完成后,连接器转换到运行状态,继续执行以下步骤。
选择DynamoDB的主键
在上述配置中,我们设置了aws。发电机B。pk。哈希和aws。发电机B。pk。按值排序。订单ID和值。站点ID。这意味着Kafka主题事件负载中的ORDER\u ID字段将用作分区键,SITE\u ID的值将被指定为范围键(根据您的要求,您也可以将aws.dynamodb.pk.sort留空)。
测试端到端管道
作为初始加载过程的一部分,连接器确保Kafka主题中的所有现有记录都保存在连接器配置中指定的DynamoDB表中。在这种情况下,您应该在DynamoDB中看到29000多条记录(根据SALES_ORDER表),您可以运行查询来探索数据。

要继续测试端到端管道,您可以在SALES_ORDER表中插入更多数据,并确认它们已通过Debezium源连接器同步到Kafka,并一直同步到DynamoDB,这要归功于接收器连接器。
删除资源
完成后,删除您创建的资源。
-
删除S3 bucket的内容(msk lab-<YOUR ACCOUNT\u ID>-plugins bucket)
-
删除CloudFormation堆栈
-
删除DynamoDB表
-
删除MSK Connect连接器、插件和自定义配置
更改数据捕获是一个强大的工具,但我们需要一种方法来利用这些事件日志,并使其可用于依赖该数据的其他服务。在这一部分中,您了解了如何利用此功能,使用Kafka Connect在MySQL和DynamoDB之间建立流数据管道。
本系列到此结束。
原文标题:MySQL to DynamoDB: Build a Streaming Data Pipeline on AWS Using Kafka
原文作者:Abhishek Gupta
原文链接:https://dzone.com/articles/mysql-to-dynamodb-build-a-streaming-data-pipeline
