点击蓝字关注我们
五一回来后,发现某微服务无法响应,出现卡死的现象。
重启后正常,过一段时间后就又会出现上文提到的现象。遂深入调查,并作文记录于下。

追踪服务日志
排查任何问题都先看日志,发现触发无响应的时候并无特殊日志提示,一切正常。
锁定服务进程
首先需要确定是哪个服务导致的cpu100%,使用命令
top -c
可以显示当前进程的运行列表,默认是按照 CPU 的使用率进行排序,即可找到占有cpu最高的进程的PID 。
锁定服务线程
然后根据进程的PID,去查找是哪个线程占用cpu最多。使用命令
top -Hp 【进程的PID】
找到这个进程对应的线程,默认按照 CPU 的使用率进行排序,即可找到占有cpu最高的线程。
打印线程的堆栈信息
先将上一步查出来的线程PID转换成16进制。
printf "%x \n" 【线程的PID】
紧接着通过jstack命令打印堆栈信息
jstack 【进程PID】 | grep '【16进制的线程的PID】' -C 50
追踪堆栈信息
走到这里,如果看到堆栈里面有大量的WAITING状态,或者提示有死锁,根据堆栈信息就会定位到自己的代码行数了。
但是在我这次并没有找到团队开发的代码,全都是依赖第三方jar的堆栈信息。
本次尝试并没有结果,放弃了。决定尝试其他的手段。
打印堆快照
jmap -dump:format=b,file=/usr/local/test.hprof 【进程PID】
然后将生成的文件导入到Java VisualVM中,Java VisualVM是JDK的bin目录下自带的工具,可以通过JMX协议连接JAVA进程进行监控,也可以通过导入堆快照的方式用来分析堆内情况。

发现一个动态代理生成的跟日志相关的类占有了大量的堆空间。
下图为正常的堆空间

可以看到正常的堆空间字符串占有的是最多的,因此定位到可能是由于堆空间设置的太小了,导致堆空间不足,于是接下来借助下GC日志观察下情况。
在JAVA_OPTS中添加以下内容
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:./gclogs -XX:+PrintTenuringDistribution -XX:+PrintHeapAtGC
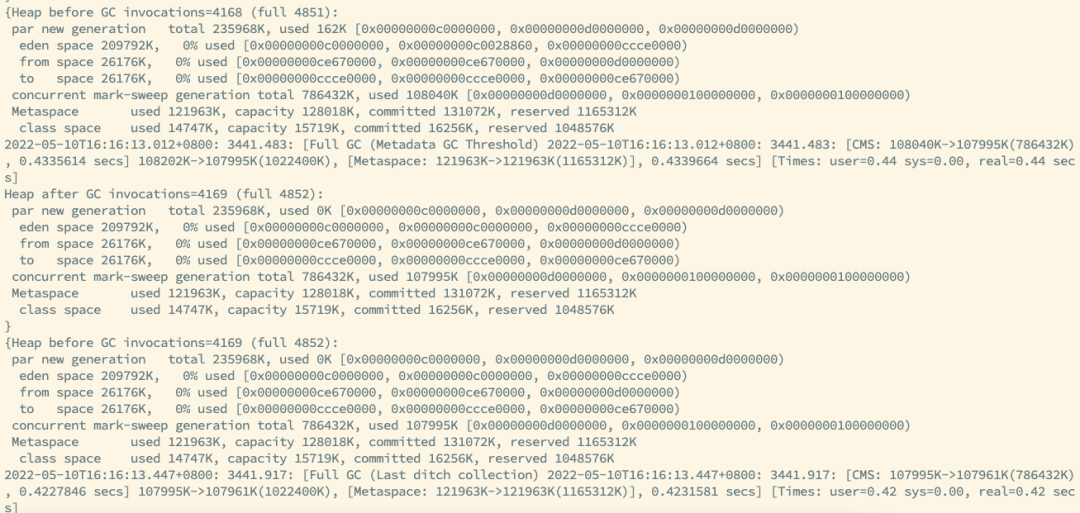
可以看到JVM在频繁地触发了Full GC,触发Full GC后,会进入STW状态。
进入STW状态后,整个JVM的线程都会暂停,此时对于外界来说就是服务无响应了。
此外还观察到Metaspace的空间满了。
进入到服务的启动脚本中,观察当前使用的JAVA_OPTS参数
JAVA_OPTS="-XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Xms1024m -Xmx1024m -Xmn256m -Xss256k -XX:SurvivorRatio=8 -XX:+UseConcMarkSweepGC"
很可能是由于元空间设置的太小,而动态代理生成的类的结构信息正好就在这里面,存不下了,导致了Full GC。
删除参数启动后,经过一段时间后发现一切正常,破案了。
之前还在奇怪,为什么之前没问题,最近突然出现了这个情况,代码并没有提交什么奇怪的地方,看来是之前元空间就基本快满了,又加了些代码之后,云空间不够用了导致的,当然我们使用的Log4j也肯定哪里有问题,或者就是我们使用的哪里不对,待后续继续排查。