点击蓝字关注我们
最近在学习Mysql的相关知识,小有所得,现总结并记录下来,以防止日后忘记。
当然如有理解不正确的地方还请不吝赐教。
注:本文仅对InnoDB的存储引擎进行讲解。
本文主要讲解Mysql常见的索引类型,以及索引的实现方式。

Mysql数据的存储结构
Mysql主要是通过聚簇索引来存储全部的数据,聚簇索引并非一种单独的索引类型,而是一种数据的存储方式。当表有聚簇索引时,它的数据行实际上存放在索引的叶子页中。术语”聚簇“,表示数据行和相邻的键值紧凑地存储在一起。
可以这样理解,相邻主键的数据行所在物理(磁盘)的位置是相近的。
Mysql一张表只有一个聚簇索引,就是使用主键这个字段进行索引的。
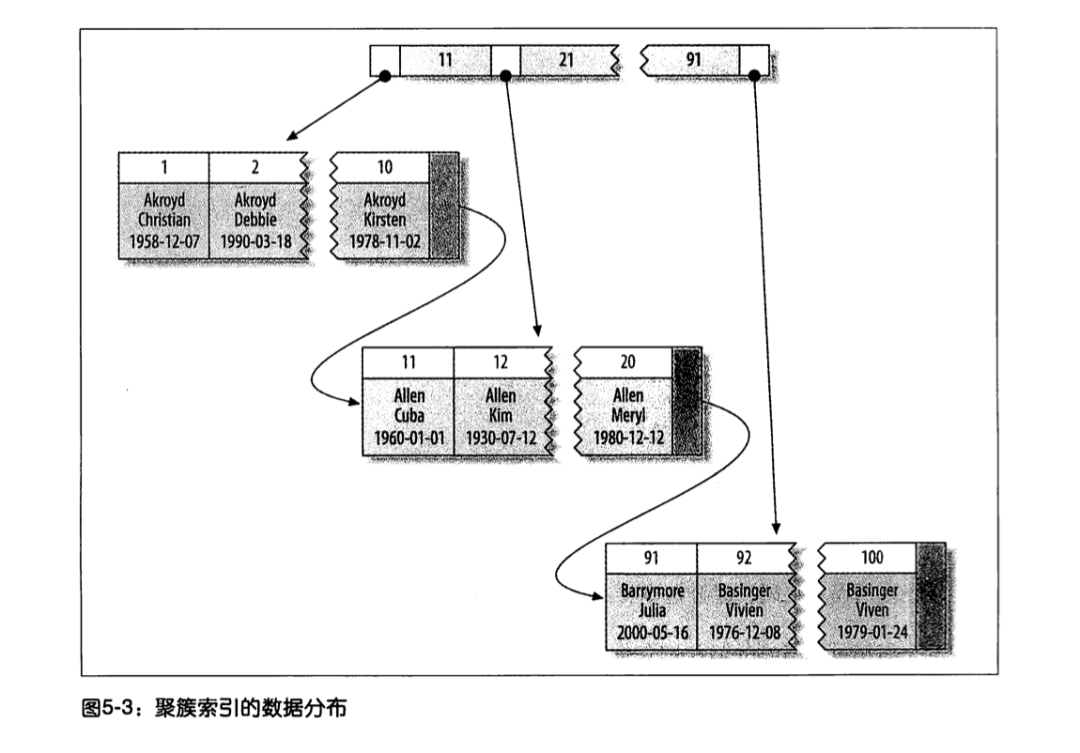
可以看到1、2、10、11、12等等即为主键,下面的灰色部分即为数据行,相邻主键的数据行彼此是互相靠近的。有关聚簇索引的数据结构B+树我们稍后会系统的讲解。
Mysql是通过一个个大小为16KB的数据页来存储数据的,这也是其一次从磁盘中读取的最少单位。
新增数据的时候,先根据上一个主键id是多少,然后在其后面再插入一条记录,如果当前数据页写满了,就会换到下一个数据页。
所以说Mysql推荐使用自增主键而要尽量避免无规则的UUID。因为一旦主键不连续,前一个主键是1,后一个主键是100,那就要给1~100之间的数据留个位置,当然由于留的位置很可能不准确,就可能导致后续插入到时候空间不够大了,会在两个相邻的数据页开辟一个新的数据页,并需要移动大量数据,该操作被称为页分裂。会花费大量的时间,甚至数据还可能会有碎片。
Mysql索引结构:B+树
终于到了本篇的重中之重啦,在这里着重谈及一下B+树相关的知识。
Mysql使用的是B+树作为数据的存储结构,B+树 是一个多路平衡查找树。多路的特点是一个父亲节点可以指向多个子节点。与二叉树、红黑树相比,B+树的高度会有所降低,相对磁盘IO的次数会较少。
可以思考一下为什么Mysql选用树而不使用其他的方式呢?
我是这样思考的,在这里用浅显易懂的方式介绍一下。Mysql在索引数据的时候,假如所有的数据都是平铺在一起,那么想要查数据就得全表的查找,时间复杂度是o(n)。随着数据量的增大,效率会急剧下降。
那么同学们可能会说,为了改善数据平铺在一起使用全表扫描,那为什么不使用hash呢?
采用hash的方式确实会让时间复杂度变成o(1),但是对于like、大于这种模糊却不能支持。所以也给他排除掉。
在这里介绍一下B+树与B树,并对比一下两者的区别。
B+树(Mysql使用该结构)
Mysql的主键使用的是聚簇索引。聚簇索引采用的是B+树的数据结构。Mysql有一个叫做数据页的概念(刚刚提到过),一个数据页的大小是16KB。每次IO会读取一个数据页的内容。
对于B+树,首先会在根节点存储主键值与指针,指针指向的是子节点,子节点也是如此,存储的是主键值与指针。只有叶子节点会存储数据。包括指向数据的物理地址(行指针),与指向其他叶子节点的双向链表。叶子节点是有顺序的,通过该双向链表可以找到比该条记录大或者小的数据。
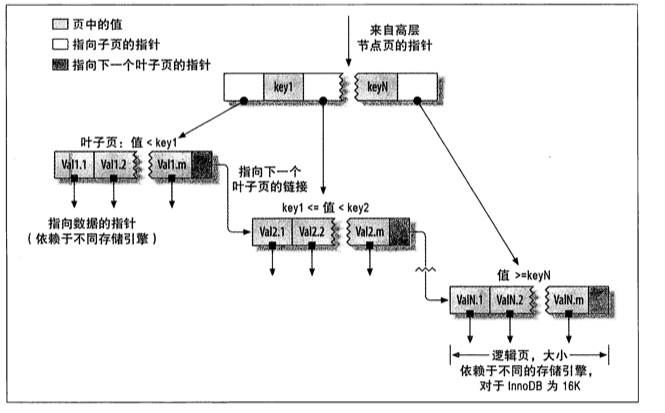
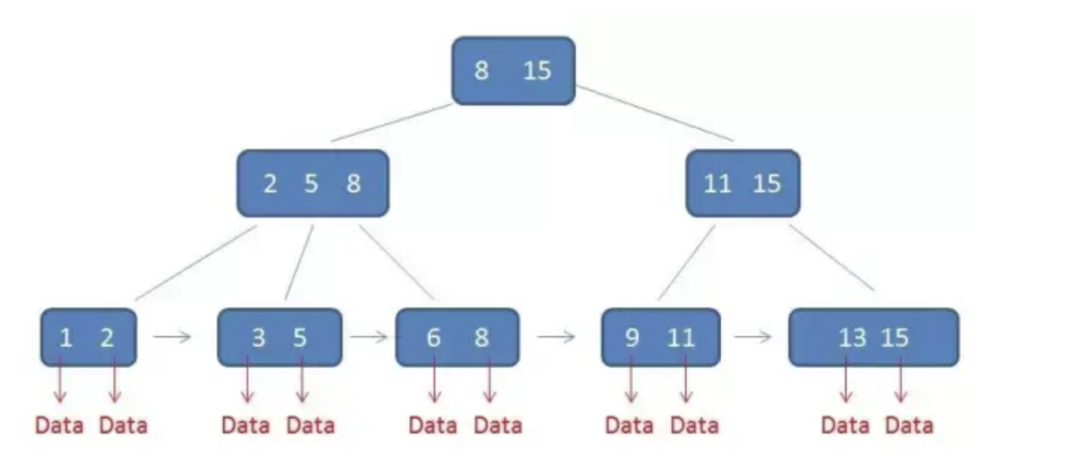
上图转自网络
可以这么说,在B树上查找数据所花费的时间基本是一致的,都是会从根节点一层一层地找到最下面一层的叶子节点。
Mysql检索数据的时候,首先会从根节点进行查找,然后通过二分查找法,直到找到相应的下一层节点,反复如此即可找到相应的数据。
B树(Mysql不使用该结构)
B树的特点就是可以在任意节点存储数据,存储的是整行记录。B树在跟节点就开始存储数据,根节点16KB的数据页存储多条数据行,与B+树存储主键值相比,B树的每一个节点存储的记录的数量都会比B+树小。这就意味着存储相同数量的数据,B树的层数更高,会导致查询的IO次数更多,花费时间更长,这就是不采用B树的原因。
辅助索引(二级索引)
刚刚谈到了聚簇索引,接下来说一说Myslq还有哪些索引。
辅助索引,就是我们自己创建的索引,辅助索引也称为二级索引。
下面谈一下我对辅助索引的理解。首先辅助索引也是使用B+树结构的,但是他和聚簇索引的区别在于辅助索引的叶子结点存储的是聚簇索引的主键值而不是行指针。也就意味着它还需要再去聚簇索引中去根据主键值去找到相应的数据。
这样做的好处也是显而易见,会减少当出现行移动或者数据页分裂时二级索引的维护工作。
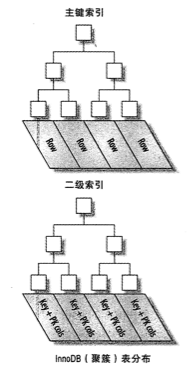
辅助索引检索数据需要搭配聚簇索引来进行回表的查询,需要走两遍,这就是其为什么也被称为二级索引的原因。当然如果想要查询的字段都在索引里面,那么就不需要回表查询了。这种情况的索引称之为覆盖索引。
今天就到这里,我们后续会继续探讨Mysql的相关知识,感谢观看。