




PostgreSQL BRIN 索引是一个专用索引(如文档所述)“处理非常大的表,其中某些列与其在表中的物理位置具有某种自然相关性”。
对于这类数据,BRIN 索引提供极低的插入成本(适用于高速数据)和极小的索引大小(适用于大容量数据)。
但是什么数据有这种“自然相关性”呢?
最常见的是带有不断添加新行的时间戳的数据。
- 日志表
- GPS轨迹点表
- 物联网传感器测量表
在这些示例中,时间戳将是插入时间或测量时间,并且新数据流将以与时间戳列值相同的顺序或多或少地附加到表中。
所以这是您可能管理的数据类型的一个非常狭窄的子集。但是,如果您确实拥有此类数据,则 BRIN 索引可能会有所帮助。
在封面下
因为 BRIN 索引非常简单,所以几乎可以不用任何简化来描述内部结构。
PostgreSQL 表中的数据以每个 8kb 的大小相等的“页面”排列在磁盘上。因此,表将作为页面集合物理驻留在磁盘上。在每一页中,行从前面打包,随着数据的删除/更新而出现间隙,并且通常在末尾有一些空闲空间以供将来更新。
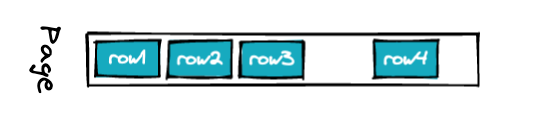
具有窄行(少列,小值)的表将在一个页面中容纳很多行。 具有宽行(更多列,长字符串)的表格只适合少数人。
因为每个页面包含多行,我们可以声明该页面中的给定列在该页面中具有最小值和最大值。 搜索特定值时,如果该值不在页面的最小/最大值范围内,则可以跳过整个页面。 这是 BRIN 的核心魔法。
因此,要使 BRIN 有效,您需要一个表,其中物理布局和感兴趣列的顺序密切相关。 在完全相关的情况下(我们在下面测试)每个页面实际上将包含一组完全独特的值。
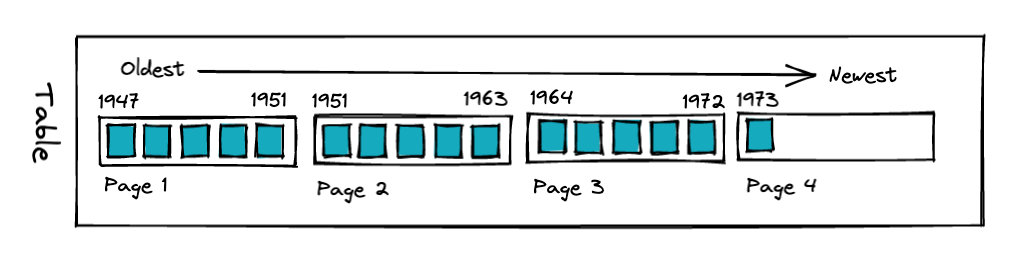
BRIN 索引是一个小表格,它将一系列值与表格顺序中的一系列页面相关联。 建立索引只需要对表进行一次扫描,因此相比于构建像 BTree 这样的结构,它是非常快的。
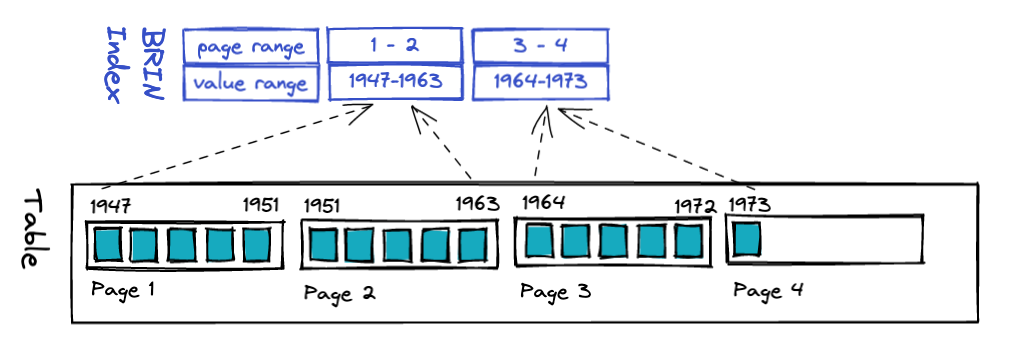
因为 BRIN 对每一页范围都有一个条目,所以它也非常小。 一个范围内的页数是可配置的,但默认值为 128。正如我们将看到的,调整这个数字可以对查询性能产生很大影响。
测量差异
为了测试,我们生成了一个包含三列的表:一个键与磁盘上的存储完全不相关(“随机”),一个键完全相关(“顺序”),以及一个要检索的“值”列。
CREATE TABLE test AS SELECT 1000000.0*random() AS random, a::float8 AS sequential, 1.0 AS value FROM generate_series(1, 1000000) a; ANALYZE test;复制
两个键都在零到一百万的范围内,因此对它们的范围查询将具有相似数量的返回值。 现在我们用越来越大的结果集测量一些基线时间。
EXPLAIN ANALYZE SELECT Sum(value) FROM test WHERE random between 0.0 and 100.0; EXPLAIN ANALYZE SELECT Sum(value) FROM test WHERE sequential between 0.0 and 100.0;复制
这是下面所有时间都使用的摘要查询。 它基于随机或顺序键的过滤器对值列求和。
(值得注意的是,在汇总索引列的情况下,btree 具有能够使用仅索引扫描的优势。为了进行苹果对苹果的比较,我们避免了这种情况 这里通过总结一个单独的“价值”列。)
对于第一个测试,由于还没有索引,系统每次都必须扫描整个表,所以唯一的变化是随着结果集的变大,将所有值相加的时间会稍微长一些。
| 行 | Filter Rand | Filter Seq |
|---|---|---|
| 100 | 220ms | 218ms |
| 1000 | 230ms | 224ms |
| 10000 | 250ms | 249ms |
| 100000 | 262ms | 264ms |
现在让我们建立索引。
CREATE INDEX btree_random_x ON test (random); CREATE INDEX btree_sequential_x ON test (sequential); CREATE INDEX brin_random_x ON test USING BRIN (random); CREATE INDEX brin_sequential_x ON test USING BRIN (sequential);复制
请注意索引之间的巨大大小差异!
SELECT pg_size_pretty(pg_relation_size('test')) AS table_size, pg_size_pretty(pg_relation_size('btree_random_x')) AS btree_random_size, pg_size_pretty(pg_relation_size('brin_random_x')) AS brin_random_size, pg_size_pretty(pg_relation_size('btree_sequential_x')) AS btree_sequential_size, pg_size_pretty(pg_relation_size('brin_sequential_x')) AS brin_sequential_size;复制
BTree 索引最终非常接近表的大小。 BRIN 索引小 1000 倍。 这是默认 pages_per_range 为 128 - pages_per_range 的较小值将导致稍大(但仍然非常小!)的索引。

现在,我们删除所有索引,然后一次重新创建一个,测试每个索引以获得越来越大的结果集。
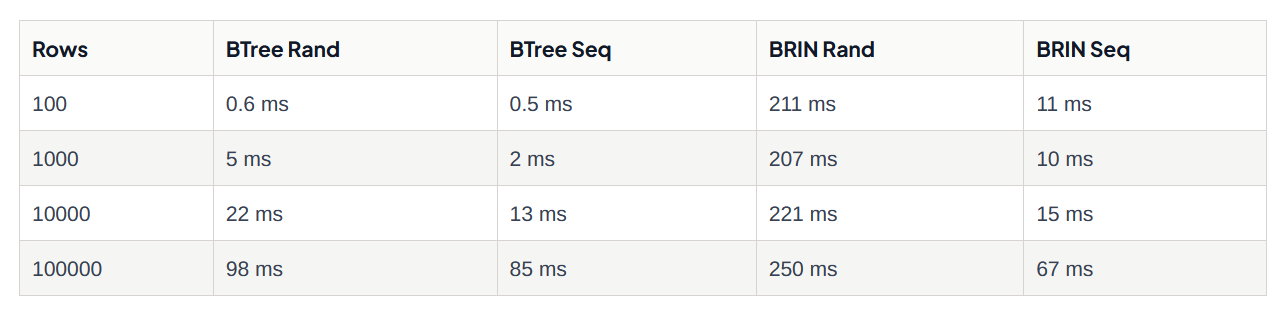
首先,请注意,正如预期的那样,BRIN 索引在过滤随机密钥时完全没用。 磁盘上数据的顺序与键的顺序是不相关的,所以 BRIN 索引并不比顺序扫描好。
其次,请注意,对于小的结果集,BTree 优于 BRIN,但随着结果集变大,BRIN 索引实际上会领先。 对于更大的结果集(10M 或 100M 记录表的 1M 记录),BRIN 优势只会增加。
即使对于小型结果集,请记住 BRIN 索引仅占用 BTree 内存空间的 0.1%,并且新行的索引更新成本也低得多。
调整参数
此测试使用的默认 pages_per_range 为128。将此参数调整为一般查询过滤器宽度可能会导致完全不同的性能结果。
DROP INDEX brin_sequential_x; CREATE INDEX brin_sequential_x ON test USING BRIN (sequential) WITH (pages_per_range=64);复制
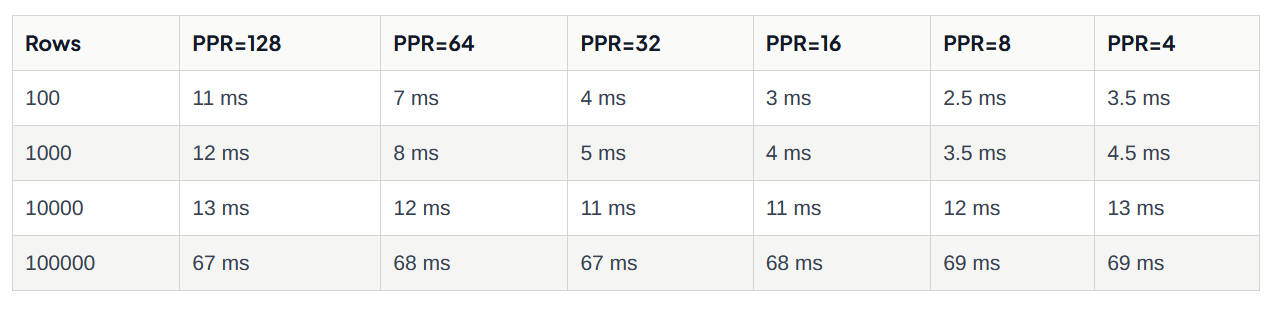
可变性能是表的每个页面中适合多少行以及查询过滤器需要读取多少页面才能完成查询的相互作用。
使用 stattuple 扩展,我们可以获得适合每个页面的元组数。
SELECT 1000000 / pg_relpages('test'); -- 156复制
对于狭窄的 100 行查询,较大的 pages_per_range 值意味着很多页面没有相关数据,因此读取和过滤它是纯粹的开销,就像序列扫描一样。 对于较小的 pages_per_range 值,任何拉取页面中的大多数值都是相关的,因此查询速度更快,特别是对于窄过滤器。
结论
- 对于特定情况,BRIN 索引可以是 BTree 的有用替代方案:
- 对于具有“仅插入”数据模式和相关列(如时间戳)的表
- 对于具有非常大的表(对于 btree 来说太大)或非常高的速度(更新成本高)或两者兼而有之的用例
- 对于从表中提取相当大(100K+)结果集的查询
- 构建成本低,内存占用少,使 BRIN 索引成为值得关注的选项,特别是对于具有相关列数据的较大表
原文标题:Postgres Indexing: When Does BRIN Win?
原文作者:Paul Ramsey
原文地址:https://www.crunchydata.com/blog/postgres-indexing-when-does-brin-win
