By大数据研习社
概要:1. 使用JDBC SQL Connector,Source只支持批处理,Sink支持批处理和流处理。
2. Sink支持数据追加和更新,如果Flink Table API做聚合操作,使用Sink必须指定指定主键。
3. 本案例独家使用Flink Table API(非SQL)方式读写MySQL,官网只讲解了SQL的使用方式。
需求:Flink Table API从MySQL读取数据,然后做聚合操作,最后将聚合结果写入MySQL。2.添加Maven依赖
FlinkTable集成MySQL需引⼊如下依赖: <groupId>org.apache.flink</groupId> <artifactId>flink-connector-jdbc_2.11</artifactId> <version>${flink.version}</version> <artifactId>mysql-connector-java</artifactId> <version>5.1.38</version>3.准备MySQL数据源
在MySQL的test数据库中,创建clicklog表并导入初始数据集。DROP TABLE IF EXISTS `clicklog`;CREATE TABLE `clicklog` ( `user` varchar(20) NOT NULL, `url` varchar(100) NOT NULL, `cTime` varchar(30) NOT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8;insert into `clicklog`(`user`,`url`,`cTime`) values ('Mary','./home','2022-02-02 12:00:00'),('Bob','./cart','2022-02-02 12:00:00'),('Mary','./prod?id=1','2022-02-02 12:00:05');4.代码实现
Flink Table API读写MySQL的完整代码如下所示。package com.bigdata.chap02;import org.apache.flink.table.api.*;import static org.apache.flink.table.api.Expressions.$;public class FlinkTableAPIMySQL2MySQL {public static void main(String[] args) {EnvironmentSettings settings = EnvironmentSettingsTableEnvironment tEnv = TableEnvironment.create(settings);Schema sourceschema = Schema.newBuilder().column("user", DataTypes.STRING()).column("url", DataTypes.STRING()).column("cTime", DataTypes.STRING())tEnv.createTemporaryTable("sourceTable", TableDescriptor.forConnector("jdbc").option("url","jdbc:mysql://hadoop1:3306/test").option("driver","com.mysql.jdbc.Driver").option("table-name","clicklog").option("username","hive").option("password","hive")tEnv.from("sourceTable").printSchema();Schema sinkschema = Schema.newBuilder().column("username",DataTypes.STRING().notNull()).column("count", DataTypes.BIGINT())tEnv.createTemporaryTable("sinkTable", TableDescriptor.forConnector("jdbc").option("url","jdbc:mysql://hadoop1:3306/test").option("driver","com.mysql.jdbc.Driver").option("table-name","clickcount").option("username","hive").option("password","hive")Table reusltTable = tEnv.from("sourceTable").aggregate($("url").count().as("count")).select($("user").as("username"), $("count"))reusltTable.printSchema();reusltTable.executeInsert("sinkTable");备注:Flink Table API做聚合操作插入MySQL,必须指定主键(.primaryKey("username")),同时必须指定主键为非空(.column("username",DataTypes.STRING().notNull()))5.MySQL业务建表
在MySQL的test数据库中,创建clickcount表用于Flink Table的聚合数据。DROP TABLE IF EXISTS `clickcount`;CREATE TABLE `clickcount` ( `username` varchar(20) NOT NULL DEFAULT '', `count` int(11) DEFAULT NULL,) ENGINE=InnoDB DEFAULT CHARSET=utf8;注意:如果clickcount表需要做更新操作,需要指定主键(primary key),如username。6.测试运行
打开MySQL连接工具,查询clickcount表中的数据,如果聚合数据能插入clickcount表,说明Flink Table API能成功将聚合数据写入MySQL数据库。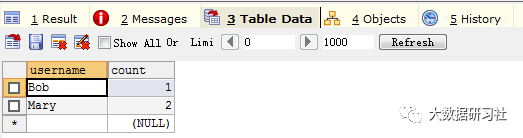
7.注意事项
4. 使用JDBC SQL connector过程中,作为source只支持批处理,作为sink既可以用于批处理又可以用于流处理。5. Sink支持数据的追加和更新,如果Flink Table API做聚合操作,使用sink更新聚合数据,必须指定指定主键。6. 本案例独家使用Flink Table API(非SQL)方式读写MySQL,官网只讲解了SQL的使用方式。长按识别左侧二维码
关注领福利
领10本经典大数据书
复制









