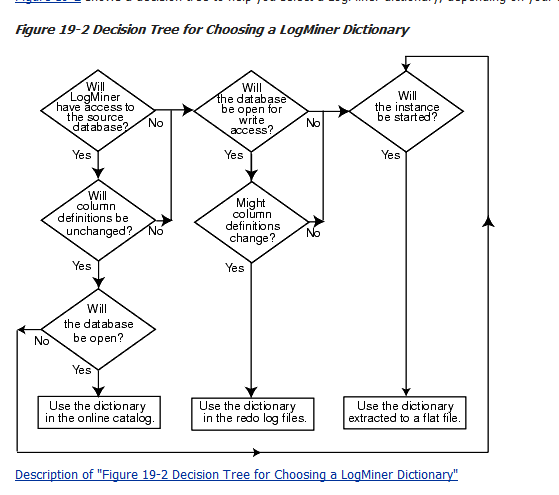
logminer 几种例外情况测试
表结构发生了改变的情况
接上篇测试环境,仍然是oraclr 19c rac,大开归档,打开了附加日志.
表drop column(add column)情况
session 1:
SQL> select * from t2;
CONS_NO CONS_NAME ID
---------- ---------- ----------
1 aaaaa
2 aaaaa
3 aaaaa
4 aaaaa
5 aaaaa
6 ddddd
7 aaaaa
8 aaaaa
9 aaaaa
10 aaaaa
10 rows selected.
SQL> update t2 set CONS_NAME='bbbbb' where CONS_NO='7';
1 row updated.
SQL> commit;
Commit complete.
复制session 2
SQL> SQL> SELECT supplemental_log_data_min min,
2 supplemental_log_data_pk pk,
3 supplemental_log_data_ui ui,
4 supplemental_log_data_fk fk,
5 supplemental_log_data_all allc
6 FROM v$database;
MIN PK UI FK ALL
-------- --- --- --- ---
YES NO NO NO NO
SQL> alter system switch logfile;
System altered.
SQL> SELECT NAME, SEQUENCE# FROM V$ARCHIVED_LOG WHERE FIRST_TIME = (SELECT MAX(FIRST_TIME) FROM V$ARCHIVED_LOG);
NAME SEQUENCE#
---------------------------------------------------------------------- ----------
+DATADG/ORA19C/ARCHIVELOG/2022_08_19/thread_1_seq_40.297.1113151651 40
复制update的语句在seq#=40里面。
此时,保存下此刻的数据字典到redo文件中,因为后面要做表结构变更。其实这是我们穿越了,提前做好预备,在实际场景中,肯定没有提前保存数据字典这一步的,都是事后排查,此处我们知识做实验说明原理。
继续在session 2里面做操作:
session 2:
SQL> select SEQUENCE#,name from v$archived_log where dictionary_begin='YES';
no rows selected
SQL> execute dbms_logmnr_d.build(options=>dbms_logmnr_d.store_in_redo_logs);
PL/SQL procedure successfully completed.
SQL> select SEQUENCE#,name from v$archived_log where dictionary_begin='YES';
SEQUENCE# NAME
---------- ----------------------------------------------------------------------
43 +DATADG/ORA19C/ARCHIVELOG/2022_08_19/thread_1_seq_43.300.1113151917
复制相当于此刻做了个快照,此时的数据字典保存在seq#=43的归档日志中。
继续session 1 做表结构变更(drop表,add 字段,drop 字段都行,模拟表的ddl发生变化):
SQL> alter table t2 drop (id);
Table altered.
SQL> select * from t2;
CONS_NO CONS_NAME
---------- ----------
1 aaaaa
2 aaaaa
3 aaaaa
4 aaaaa
5 aaaaa
6 ddddd
7 bbbbb
8 aaaaa
9 aaaaa
10 aaaaa
10 rows selected.
复制session 2:
SQL> alter system switch logfile;
System altered.
SQL> SELECT NAME, SEQUENCE# FROM V$ARCHIVED_LOG WHERE FIRST_TIME = (SELECT MAX(FIRST_TIME) FROM V$ARCHIVED_LOG);
NAME SEQUENCE#
---------------------------------------------------------------------- ----------
+DATADG/ORA19C/ARCHIVELOG/2022_08_19/thread_1_seq_45.302.1113152225 45
复制所以此时drop 列的日志存储在seq#=45 中。那么下面就对40和45 两个日志进行分析。
session 3:
[oracle@19crac1 ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Fri Aug 19 16:59:37 2022
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
SQL> EXECUTE DBMS_LOGMNR.ADD_LOGFILE(LOGFILENAME => '+DATADG/ORA19C/ARCHIVELOG/2022_08_19/thread_1_seq_40.297.1113151651',OPTIONS => DBMS_LOGMNR.NEW);
EXECUTE DBMS_LOGMNR.ADD_LOGFILE(LOGFILENAME => '+DATADG/ORA19C/ARCHIVELOG/2022_08_19/thread_1_seq_45.302.1113152225',OPTIONS => DBMS_LOGMNR.ADDFILE);
PL/SQL procedure successfully completed.
PL/SQL procedure successfully completed.
SQL> EXECUTE DBMS_LOGMNR.START_LOGMNR(-
> OPTIONS => DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG + -
> DBMS_LOGMNR.COMMITTED_DATA_ONLY + -
> DBMS_LOGMNR.PRINT_PRETTY_SQL);
PL/SQL procedure successfully completed.
SQL> set linesize 300 pagesize 9999
SQL> col seg_owner for a10
SQL> col seg_name for a20
SQL> col table_name for a20
SQL> col USR for a10
SQL> col sql_redo for a35
SQL> col SQL_UNDO for a35
SQL> SELECT SEG_OWNER,
2 SEG_NAME,
3 TABLE_NAME, USERNAME AS usr,SQL_REDO,SQL_UNDO,operation FROM
4 V$LOGMNR_CONTENTS WHERE SEG_OWNER ='TEST1';
SEG_OWNER SEG_NAME TABLE_NAME USR SQL_REDO SQL_UNDO OPERATION
---------- -------------------- -------------------- ---------- ----------------------------------- ----------------------------------- --------------------------------
TEST1 T2 T2 TEST1 update "TEST1"."T2" update "TEST1"."T2" UPDATE
set set
"COL 2" = HEXTORAW('6262626262' "COL 2" = HEXTORAW('6161616161'
) )
where where
"COL 2" = HEXTORAW('6161616161' "COL 2" = HEXTORAW('6262626262'
) and ) and
ROWID = 'AAAFsDAAOAAAACWAAG'; ROWID = 'AAAFsDAAOAAAACWAAG';
TEST1 T2 T2 TEST1 alter table t2 drop (id); DDL
复制结果可以看到,ddl语句解析正常,但是之前的update语句都是乱码。
我们模拟测试表结构发生变化,本例是drop clomun,那在线数据字典是不是就跟原来t2数据字典不一样了?但是前面的UPDATE的REDO确是针对t2表有id列的,添加日志文件,我们先采用常规的联机数据字典方式来分析日志。在线目录,只能使用当前的字典来转化。结果都是不认识的函数和数字,所以我们需要测试表定义发生改变之前的数据字典。
我们利用ddl发生之前的数据字典来解析,刚好我们drop column之前通过BUILD把数据字典存储在了归档日志中。所以我们利用seq#=43和40 来解析。
session 4:
SQL> +DATADG/ORA19C/ARCHIVELOG/2022_08_19/thread_1_seq_43.300.1113151917^C
SQL> EXECUTE DBMS_LOGMNR.ADD_LOGFILE(LOGFILENAME => '+DATADG/ORA19C/ARCHIVELOG/2022_08_19/thread_1_seq_43.300.1113151917',OPTIONS => DBMS_LOGMNR.NEW);
PL/SQL procedure successfully completed.
SQL> EXECUTE DBMS_LOGMNR.ADD_LOGFILE(LOGFILENAME => '+DATADG/ORA19C/ARCHIVELOG/2022_08_19/thread_1_seq_40.297.1113151651',OPTIONS => DBMS_LOGMNR.ADDFILE);
PL/SQL procedure successfully completed.
SQL> EXECUTE DBMS_LOGMNR.START_LOGMNR(-
> OPTIONS => DBMS_LOGMNR.DICT_FROM_REDO_LOGS + -
> DBMS_LOGMNR.PRINT_PRETTY_SQL);
BEGIN DBMS_LOGMNR.START_LOGMNR( OPTIONS => DBMS_LOGMNR.DICT_FROM_REDO_LOGS + DBMS_LOGMNR.PRINT_PRETTY_SQL); END;
*
ERROR at line 1:
ORA-01371: Complete LogMiner dictionary not found
ORA-06512: at "SYS.DBMS_LOGMNR", line 72
ORA-06512: at line 1
复制按照之前文章说的方法,会报错;
如果EXECUTE DBMS_LOGMNR.START_LOGMNR(OPTIONS => DBMS_LOGMNR.DICT_FROM_REDO_LOGS);ADD_LOGFILE需要添加多个的redo log 文件,否则会报错。根据字典文件的大小不同,它可能包含在一个或多个log文件中,在进行日志分析时,也就需要将这些字典文件所在的log文件包含在分析日志列表中。
添加的日志少了,不包含全部的数据字典,所以会报错,我们应该添加包含全部数据字典的日志。如下:
SQL> select SEQUENCE#,name from v$archived_log where dictionary_begin='YES';
SQL> select SEQUENCE#,name from v$archived_log where DICTIONARY_END='YES';
复制SQL> select SEQUENCE#,name from v$archived_log where DICTIONARY_END='YES';
SEQUENCE# NAME
---------- ----------------------------------------------------------------------
44 +DATADG/ORA19C/ARCHIVELOG/2022_08_19/thread_1_seq_44.301.1113151917
复制字典结束的日志文件保存在44号中,所以还应包含44号日志。
session 5:
SQL> EXECUTE DBMS_LOGMNR.ADD_LOGFILE(LOGFILENAME => '+DATADG/ORA19C/ARCHIVELOG/2022_08_19/thread_1_seq_43.300.1113151917',OPTIONS => DBMS_LOGMNR.NEW);
EXECUTE DBMS_LOGMNR.ADD_LOGFILE(LOGFILENAME => '+DATADG/ORA19C/ARCHIVELOG/2022_08_19/thread_1_seq_40.297.1113151651',OPTIONS => DBMS_LOGMNR.ADDFILE);
EXECUTE DBMS_LOGMNR.ADD_LOGFILE(LOGFILENAME => '+DATADG/ORA19C/ARCHIVELOG/2022_08_19/thread_1_seq_44.301.1113151917',OPTIONS => DBMS_LOGMNR.ADDFILE);
PL/SQL procedure successfully completed.
SQL>
PL/SQL procedure successfully completed.
SQL>
PL/SQL procedure successfully completed.
SQL> EXECUTE DBMS_LOGMNR.START_LOGMNR(-
OPTIONS => DBMS_LOGMNR.DICT_FROM_REDO_LOGS + -
> > DBMS_LOGMNR.PRINT_PRETTY_SQL);
PL/SQL procedure successfully completed.
SQL> set linesize 300 pagesize 9999
SQL> col seg_owner for a10
SQL> col seg_name for a20
SQL> col table_name for a20
SQL> col USR for a10
SQL> col sql_redo for a35
SQL> col SQL_UNDO for a35
SQL> SELECT SEG_OWNER,
2 SEG_NAME,
3 TABLE_NAME, USERNAME AS usr,SQL_REDO,SQL_UNDO,operation FROM
4 V$LOGMNR_CONTENTS WHERE SEG_OWNER ='TEST1';
SEG_OWNER SEG_NAME TABLE_NAME USR SQL_REDO SQL_UNDO OPERATION
---------- -------------------- -------------------- ---------- ----------------------------------- ----------------------------------- --------------------------------
TEST1 T2 T2 TEST1 update "TEST1"."T2" update "TEST1"."T2" UPDATE
set set
"CONS_NAME" = 'bbbbb' "CONS_NAME" = 'aaaaa'
where where
"CONS_NAME" = 'aaaaa' and "CONS_NAME" = 'bbbbb' and
ROWID = 'AAAFsDAAOAAAACWAAG'; ROWID = 'AAAFsDAAOAAAACWAAG';
复制现在能够正常的分析出来,不乱码了。
DICT_FROM_REDO_LOGS,也可以看出两点:
1、不止远程分析,本库也能分析,主要就是要结构完整,4检讨不能少,目标端在哪都可以;
2、包含数据字典的日志一定要添加全,begin 和end 都要验证。
session 5继续添加drop column的日志:
SQL> EXECUTE DBMS_LOGMNR.ADD_LOGFILE(LOGFILENAME => '+DATADG/ORA19C/ARCHIVELOG/2022_08_19/thread_1_seq_45.302.1113152225',OPTIONS => DBMS_LOGMNR.ADDFILE);
PL/SQL procedure successfully completed.
SQL> EXECUTE DBMS_LOGMNR.START_LOGMNR(-
OPTIONS => DBMS_LOGMNR.DICT_FROM_REDO_LOGS + -
DBMS_LOGMNR.PRINT_PRETTY_SQL);
> >
PL/SQL procedure successfully completed.
SQL> set linesize 300 pagesize 9999
col seg_owner for a10
col seg_name for a20
SQL> SQL> SQL> col table_name for a20
SQL> col USR for a10
SQL> col sql_redo for a35
SQL> col SQL_UNDO for a35
SQL> SELECT SEG_OWNER,
2 SEG_NAME,
3 TABLE_NAME, USERNAME AS usr,SQL_REDO,SQL_UNDO,operation FROM
4 V$LOGMNR_CONTENTS WHERE SEG_OWNER ='TEST1';
SEG_OWNER SEG_NAME TABLE_NAME USR SQL_REDO SQL_UNDO OPERATION
---------- -------------------- -------------------- ---------- ----------------------------------- ----------------------------------- --------------------------------
TEST1 T2 T2 TEST1 update "TEST1"."T2" update "TEST1"."T2" UPDATE
set set
"CONS_NAME" = 'bbbbb' "CONS_NAME" = 'aaaaa'
where where
"CONS_NAME" = 'aaaaa' and "CONS_NAME" = 'bbbbb' and
ROWID = 'AAAFsDAAOAAAACWAAG'; ROWID = 'AAAFsDAAOAAAACWAAG';
TEST1 T2 T2 TEST1 alter table t2 drop (id); DDL
复制可以看到利用之前的字典,后面drop column的ddl也能正常解析。
drop table极端情况的修改表字段
按如上方法,drop table 发生极端字段修改,也能解析:
online catalog 解析:
SQL> EXECUTE DBMS_LOGMNR.START_LOGMNR(-
> OPTIONS => DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG + -
> DBMS_LOGMNR.COMMITTED_DATA_ONLY + -
> DBMS_LOGMNR.PRINT_PRETTY_SQL);
PL/SQL procedure successfully completed.
SQL> set linesize 300 pagesize 9999
SQL> col seg_owner for a10
SQL> col seg_name for a20
SQL> col table_name for a20
SQL> col USR for a10
SQL> col sql_redo for a35
SQL> col SQL_UNDO for a35
SQL> SELECT SEG_OWNER,
2 SEG_NAME,
3 TABLE_NAME, USERNAME AS usr,SQL_REDO,SQL_UNDO,operation FROM
4 V$LOGMNR_CONTENTS WHERE SEG_OWNER ='TEST1';
SEG_OWNER SEG_NAME TABLE_NAME USR SQL_REDO SQL_UNDO OPERATION
---------- -------------------- -------------------- ---------- ----------------------------------- ----------------------------------- --------------------------------
TEST1 BIN$5pToLfsKiTvgUxYL BIN$5pToLfsKiTvgUxYL TEST1 update "TEST1"."BIN$5pToLfsKiTvgUxY update "TEST1"."BIN$5pToLfsKiTvgUxY UPDATE
AQq6UA==$0 AQq6UA==$0 LAQq6UA==$0" LAQq6UA==$0"
set set
"COL 2" = HEXTORAW('6473657765' "COL 2" = HEXTORAW('6161616161'
) )
where where
"COL 2" = HEXTORAW('6161616161' "COL 2" = HEXTORAW('6473657765'
) and ) and
ROWID = 'AAAFsDAAOAAAACWAAI'; ROWID = 'AAAFsDAAOAAAACWAAI';
TEST1 T2 T2 TEST1 ALTER TABLE "TEST1"."T2" RENAME TO DDL
"BIN$5pToLfsKiTvgUxYLAQq6UA==$0" ;
TEST1 T2 T2 TEST1 drop table t2 AS "BIN$5pToLfsKiTvgU DDL
xYLAQq6UA==$0" ;
复制DICT_FROM_REDO_LOGS离线数据字典的方法可以正常解析:
SQL> EXECUTE DBMS_LOGMNR.START_LOGMNR(-
OPTIONS => DBMS_LOGMNR.DICT_FROM_REDO_LOGS + -
> > DBMS_LOGMNR.PRINT_PRETTY_SQL);
PL/SQL procedure successfully completed.
SQL> set linesize 300 pagesize 9999
SQL> col seg_owner for a10
SQL> col seg_name for a20
SQL> col table_name for a20
SQL> col USR for a10
SQL> col sql_redo for a35
SQL> col SQL_UNDO for a35
SQL> SELECT SEG_OWNER,
2 SEG_NAME,
3 TABLE_NAME, USERNAME AS usr,SQL_REDO,SQL_UNDO,operation FROM
4 V$LOGMNR_CONTENTS WHERE SEG_OWNER ='TEST1';
SEG_OWNER SEG_NAME TABLE_NAME USR SQL_REDO SQL_UNDO OPERATION
---------- -------------------- -------------------- ---------- ----------------------------------- ----------------------------------- --------------------------------
TEST1 T2 T2 TEST1 update "TEST1"."T2" update "TEST1"."T2" UPDATE
set set
"CONS_NAME" = 'dsewe' "CONS_NAME" = 'aaaaa'
where where
"CONS_NAME" = 'aaaaa' and "CONS_NAME" = 'dsewe' and
ROWID = 'AAAFsDAAOAAAACWAAI'; ROWID = 'AAAFsDAAOAAAACWAAI';
TEST1 T2 T2 TEST1 ALTER TABLE "TEST1"."T2" RENAME TO DDL
"BIN$5pToLfsKiTvgUxYLAQq6UA==$0" ;
TEST1 T2 T2 TEST1 drop table t2 AS "BIN$5pToLfsKiTvgU DDL
xYLAQq6UA==$0" ;
复制综上,当有表的字段发生ddl改变后(drop clomun,add column,drop table),推荐使用DICT_FROM_REDO_LOGS。为了保证字典的可用性,建议能够定期备份该字典文件(即定期做
SQL> execute dbms_logmnr_d.build(options=>dbms_logmnr_d.store_in_redo_logs);)。要不然都没数据字典,肯定解析不了。即前提是要有备份的数据字典,才能随时随地解析,尤其这种表的字段发生变化的情况。