




开发小哥很久没在群里说话了,今天又在群里说话了。
“兄弟,在吗?有个SQL从Oracle迁移到PostgreSQL后,执行太慢了,能不能给看一下啊!”

每次一看是分析这套系统的SQL,就感到头皮发麻。因为他接手的系统都是前人留下的烂摊子,垃圾SQL语句一大堆,N张表关联嵌套循环,SQL特别复杂。
我还是决定先看看SQL情况再说。
问题SQL
首先把它的SQL拿到PostgreSQL数据库中运行了一下,发现运行需要280秒,真的很慢。

通过OMNIDB对执行计划稍微格式化一下。会发现整个计划的瓶颈在于对分区表所有分区扫描合并后的排序操作。
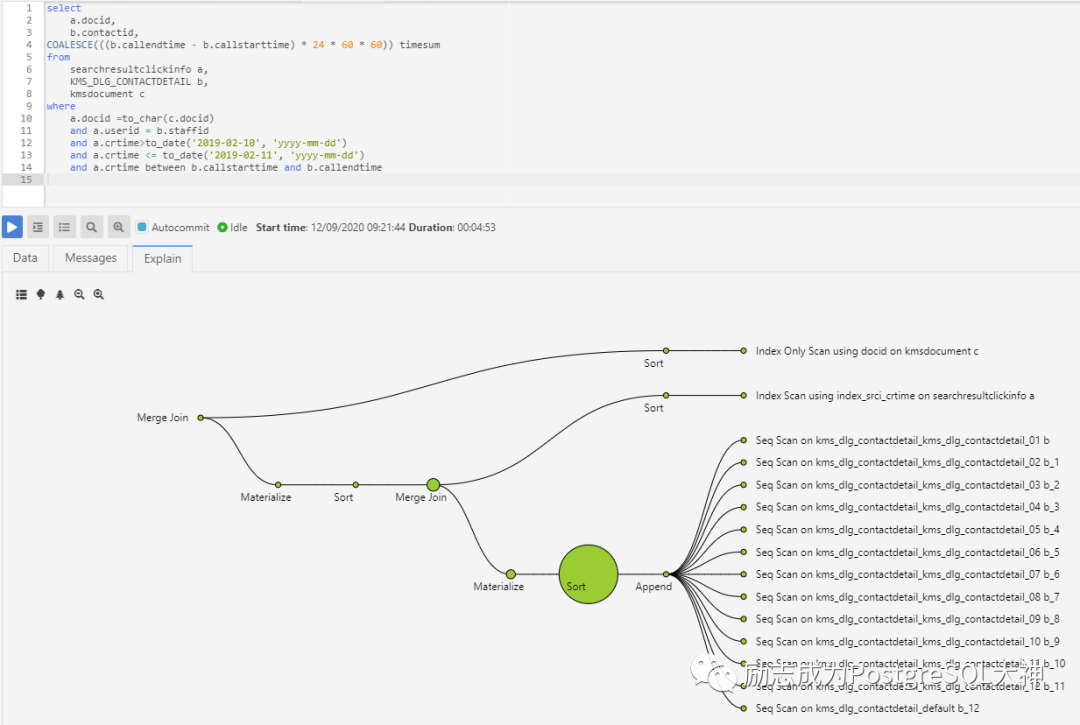
而排序的字段是b.staffid,排序产生了临时段, Sort Method: external merge Disk: 4568744kB,换算过来是4.35GB。
然后拿到Oracle中执行了一下,执行时间只需要44秒,发现是hash join的连结方式。
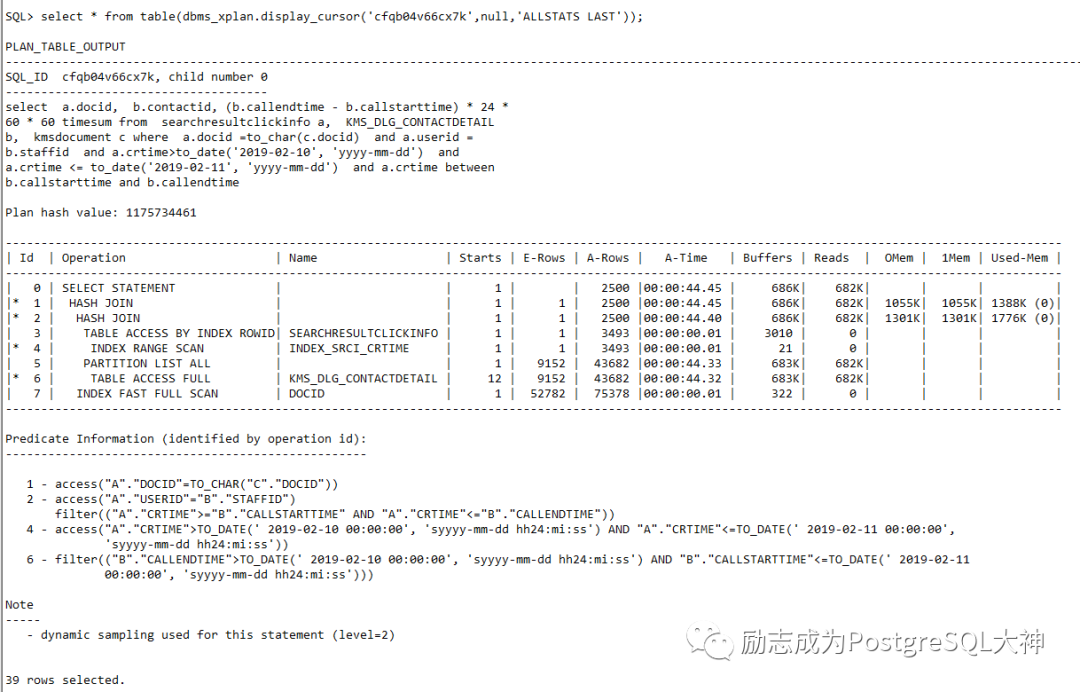
在PostgreSQL中通过设置参数enable_mergejoin为off,可以让执行计划选择走hash join,然后速度得到大幅提升,和Oracle执行速度相似。


收集统计信息能解决吗?
那么现在问题来了,总不能让应用侧在代码里面去执行禁用参数的命令吧。
因为表kms_dlg_contactdetail数据量是8000万,根据相关的执行条件,对相关列的统计信息提升比例进行收集。
ALTER TABLE kms_dlg_contactdetail alter column staffid SET STATISTICS 10000;
ALTER TABLE kms_dlg_contactdetail alter column staffid SET STATISTICS 10000;
ALTER TABLE kms_dlg_contactdetail alter column staffid SET STATISTICS 10000;
kms=> select attname,attstattarget from pg_catalog.pg_attribute where attrelid='kms_dlg_contactdetail'::regclass;
attname | attstattarget
---------------+---------------
tableoid | 0
cmax | 0
xmax | 0
cmin | 0
xmin | 0
ctid | 0
contactid | -1
callstarttime | 10000
callendtime | 10000
staffid | 10000
callerno | -1
month | -1
(12 rows)
ALTER TABLE searchresultclickinfo alter column crtime SET STATISTICS 10000;
ALTER TABLE searchresultclickinfo alter column userid SET STATISTICS 10000;
kms=> select attname,attstattarget from pg_catalog.pg_attribute where attrelid='searchresultclickinfo'::regclass;
attname | attstattarget
-------------+---------------
tableoid | 0
cmax | 0
xmax | 0
cmin | 0
xmin | 0
ctid | 0
docid | -1
title | -1
crcityid | -1
query | -1
seq | -1
crtime | 10000
userid | 10000
classify | -1
searchtype | -1
status | -1
sortbyfield | -1
dockeywords | -1
(18 rows)
kms=> analyze kms_dlg_contactdetail;
ANALYZE
kms=> analyze kms_dlg_contactdetail_kms_dlg_contactdetail_01;
ANALYZE
kms=> analyze kms_dlg_contactdetail_kms_dlg_contactdetail_02;
ANALYZE
kms=> analyze kms_dlg_contactdetail_kms_dlg_contactdetail_03;
ANALYZE
kms=> analyze kms_dlg_contactdetail_kms_dlg_contactdetail_04;
ANALYZE
kms=> analyze kms_dlg_contactdetail_kms_dlg_contactdetail_05;
ANALYZE
kms=> analyze kms_dlg_contactdetail_kms_dlg_contactdetail_06;
ANALYZE
kms=> analyze kms_dlg_contactdetail_kms_dlg_contactdetail_07;
ANALYZE
kms=> analyze kms_dlg_contactdetail_kms_dlg_contactdetail_08;
ANALYZE
kms=> analyze kms_dlg_contactdetail_kms_dlg_contactdetail_09;
ANALYZE
kms=> analyze kms_dlg_contactdetail_kms_dlg_contactdetail_10;
ANALYZE
kms=> analyze kms_dlg_contactdetail_kms_dlg_contactdetail_11;
ANALYZE
kms=> analyze kms_dlg_contactdetail_default;
ANALYZE
kms=> analyze searchresultclickinfo;
ANALYZE
Time: 118121.649 ms (01:58.122)复制
统计收集之后,再次执行这个SQL,仍然无改善。还是走Merge sort join.
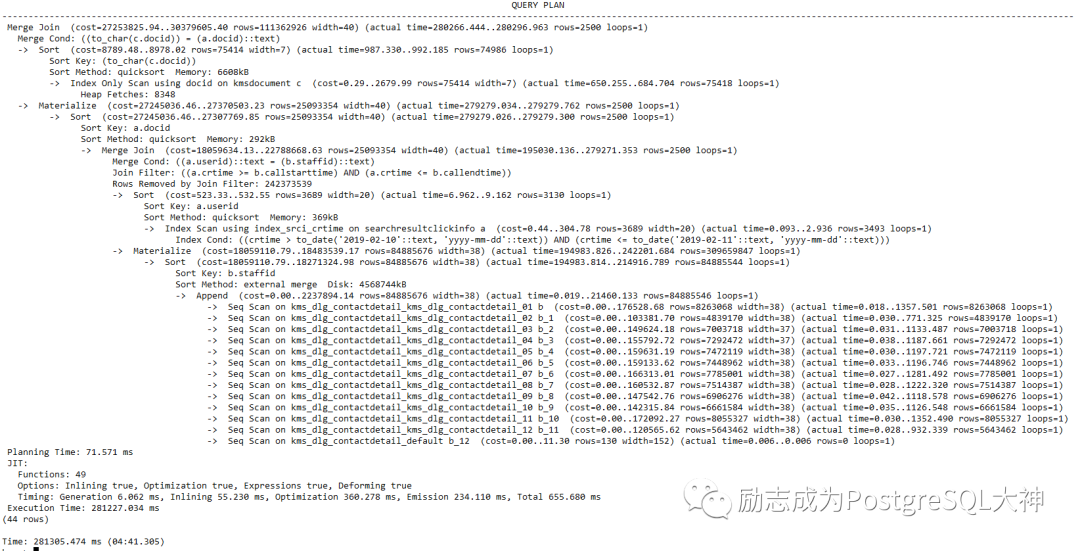
调整work_mem?
由于使用了Merge Join,我决定试试把work_mem参数调大,看看有没有什么改善?将work_mem设置为128MB。重新执行,发现下面部分已经走了hash join。而上面部分仍然是Merge Join。

不过现在执行速度可以从280秒下降到90秒了,和Oracle还有一定的差距。
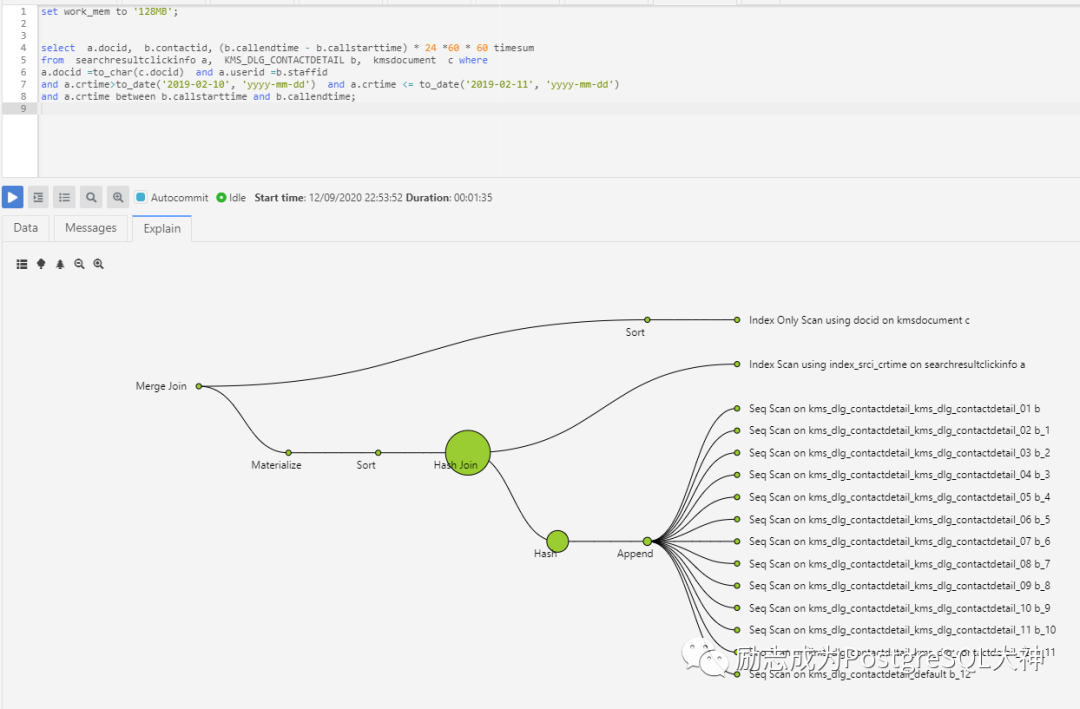
类型转换导致的问题?
注意看上面的执行计划,在sort排序的时候,出现了一个Sort Key: (to_char(c.docid)),这竟然要对to_char函数执行结果进行sort。而默认PostgreSQL中to_char的版本是带两个参数的,这里使用单参数版本是orafce兼容插件提供的。

于是我重新创建了一个test1表。
kms=> create table test1 as select * from kmsdocument;
SELECT 75418
kms=> alter table test1 alter column docid type character varying(20) USING docid::character varying(20);
ALTER TABLE
kms=> ALTER TABLE test1 alter column docid SET STATISTICS 1000;
ALTER TABLE
kms=> create index idx_test1 on test1(docid);
CREATE INDEX
kms=> analyze test1;
ANALYZE
Time: 12872.419 ms (00:12.872)复制
重新执行之后,这次很快大概只要38秒就出了结果,而且使用了Parallel hash join的方式。
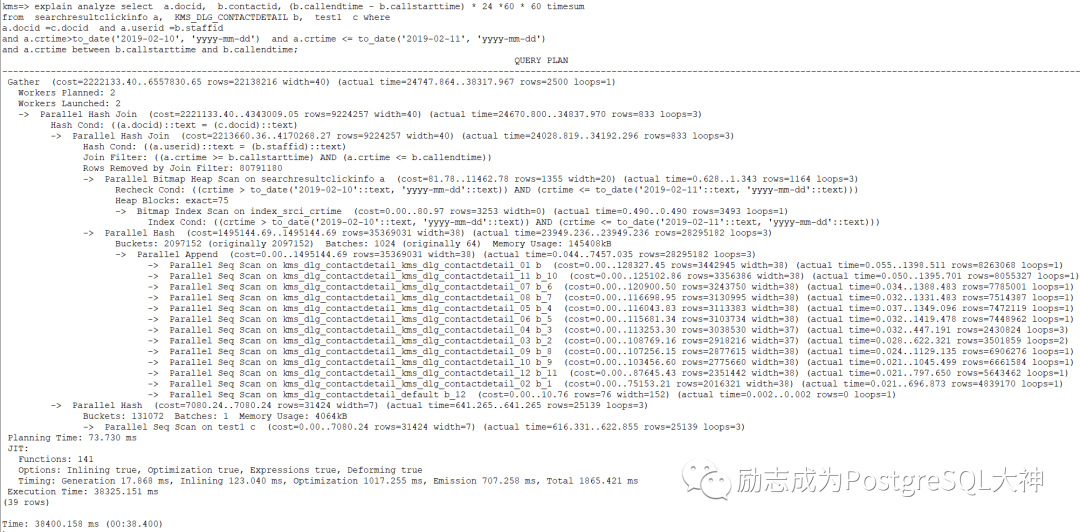
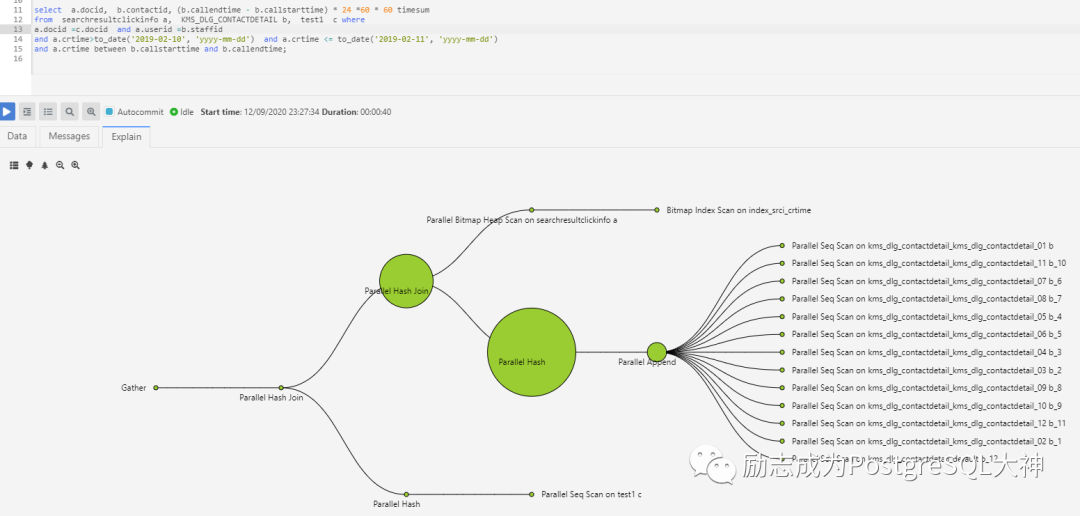
总结
虽然从280秒优化到30多秒,但是不是很完美。因为需要调大work_mem
,同时还需要修改问题表字段的类型,让它不要使用Orafce插件提供的to_char函数。所以我准备改天用pg_hint_plan
试试,直接让开发使用hint改变执行计划。
评论

 0 点赞
0 点赞



