




问题现象:
这个问题是开发的同事发过来邮件,说有一个批量跑一会儿就报错退出,提了几次都是这个情况,让分析下原因。
问题分析:
我个人有一个习惯,当处理线上问题的时候,登录os后,会先用操作系统命令df -Th,top命令查看下系统文件系统的使用率,CPU的使用情况。因为有的时候往往会忽略一些系统上的小点,
曾经碰到一个问题,查了很长一会儿没查明白,最后一看是文件分区满了,这就很尴尬了。当然,这次问题跟操作系统无关。
步骤一、三八大盖---》alert日志
我登录系统的时候,这个批量还没开始跑,我就先上去看了下alert日志,看看有没有什么报错,果然一下就发现问题了,日志里有很明显的问题报错,临时表空间TEMP不足导致的SQL执行失败,而且基本确认了问题时间是08:27分左右。
Thu Apr 28 08:28:27 2022
ORA-1652: unable to extend temp segment by 128 in tablespace TEMP
Thu Apr 28 08:28:27 2022
ORA-1652: unable to extend temp segment by 128 in tablespace TEMP
Thu Apr 28 08:30:02 2022
Thread 1 advanced to log sequence 19844 (LGWR switch)
步骤二、万金油----》ASH
碰到这种TEMP表空间的问题,基本进入了我熟悉的问题分析流程了。我之前听一个中老dba说,用活了v$ash,就超过市面上百分之80的dba了,虽然可能不准确,但是从一个方面反应了v$ASH在oracle dba心里的地位。好嘞,这个问题直接开撸,直接查占用TEMP高的SQL:
col event for a40
set linesize 300
select sql_id,event,sum(TEMP_SPACE_ALLOCATED)/1024/1024/1024 from
gv$active_session_history
where sample_time>to_date('20220428 08:15','yyyymmdd hh24:mi:ss')
and sample_time<to_date('20220428 08:30','yyyymmdd hh24:mi:ss')
group by sql_id,event
order by 3;
SQL_ID EVENT SUM(TEMP_SPACE_ALLOCATED)/1024/1024/1024
------------- ---------------------------------------- ----------------------------------------
8frr3ar9ybj9u 26.9384766
dfpfwghbnjyn5 local write wait 64.6708984
dfpfwghbnjyn5 DFS lock handle 105.486328
dfpfwghbnjyn5 direct path write temp 310.296875
dfpfwghbnjyn5 694.869141
8j32rtkhswuwp enq: TS - contention 705.788086
8j32rtkhswuwp enq: SS - contention 1031.95996
8j32rtkhswuwp buffer busy waits 1275.9707
8j32rtkhswuwp gc current block busy 1887.78711
8j32rtkhswuwp DFS lock handle 33453.5674
8j32rtkhswuwp local write wait 33579.8975
SQL_ID EVENT SUM(TEMP_SPACE_ALLOCATED)/1024/1024/1024
------------- ---------------------------------------- ----------------------------------------
8j32rtkhswuwp direct path write temp 54793.2061
8j32rtkhswuwp 131070.298
我这个查询SQL不是很准确哈,这个V$ASH是1s一次的采样,我这个SQL会把同一个SQL在这一段时间的采样到的TEMP全部累加起来,值会很大。但是呢我已经用习惯了,准确性还是比较高的,甭管是PGA还是TEMP我都习惯这么撸。
好的,那基本上确定了sql了,SQL text如下,这是一个insert哈。
SQL> select sql_text from v$sql where sql_id='8j32rtkhswuwp';
SQL_TEXT
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
insert into cc_ins_client_asset(client_id, acct_id , portfolio_id, portfolio_type, asset_section, asset_scale, data_type , data_range, type, update_date, fund_type, fund_code,subAcctId) select his.productid,his.acctid,his.gportfolioid,his.portfoliotype,:1 ,sum(his.currentvol * hi.nav) as scale,:2 ,
:3 ,:4 ,to_char(sysdate,'yyyymmddhh24miss') ,max(wr.wsc_category1_code),his.fundcode,his.subacctid from ofs_fundlist_portfoliohis his inner join pof_netvalue_his hi on his.fundcode = hi.ticker inner join ( select p.ticker,max(p.nav_date) as maxNavDate from pof_netvalue_his p group by p.ticker
)m on hi.ticker = m.ticker and hi.nav_date = m.maxNavDate inner join wr_portfolio_subfund wr on his.fundcode = wr.ticker where substr(his.occurtime,0,8) = :5 and his.portfoliotype =:6 group by his.productid,his.gportfolioid ,his.portfoliotype,his.acctid ,his.fundcode,his.subacctid
步骤三、意大利炮---》sql monitor
有了sql id 了,那就直接干执行计划吧,我一般看执行计划我喜欢display_cursor/display_awr和sql monitor一块看,sql monitor可以看sql正在执行过程中的情况,display_cursor呢会有一些谓词条件啊,优化器参数啊,这两块结合着看。
先是display_cursor的内容,放这里一会儿用哈。
select * from table(dbms_xplan.display_cursor('8j32rtkhswuwp',null,'allstats last'));
Plan hash value: 2121924847
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------------
| 0 | INSERT STATEMENT | | | | 24700 (100)| |
| 1 | LOAD TABLE CONVENTIONAL | | | | | |
| 2 | HASH GROUP BY | | 1 | 135 | 24700 (1)| 00:04:57 |
| 3 | VIEW | VM_NWVW_1 | 1 | 135 | 24700 (1)| 00:04:57 |
|* 4 | FILTER | | | | | |
| 5 | HASH GROUP BY | | 1 | 184 | 24700 (1)| 00:04:57 |
|* 6 | HASH JOIN | | 472 | 86848 | 24699 (1)| 00:04:57 |
| 7 | MERGE JOIN CARTESIAN| | 700 | 103K| 24452 (1)| 00:04:54 |
|* 8 | HASH JOIN | | 1 | 135 | 24206 (1)| 00:04:51 |
|* 9 | TABLE ACCESS FULL | OFS_FUNDLIST_PORTFOLIOHIS | 1 | 113 | 24202 (1)| 00:04:51 |
| 10 | TABLE ACCESS FULL | WR_PORTFOLIO_SUBFUND | 591 | 13002 | 4 (0)| 00:00:01 |
| 11 | BUFFER SORT | | 69950 | 1092K| 24448 (1)| 00:04:54 |
| 12 | TABLE ACCESS FULL | POF_NETVALUE_HIS | 69950 | 1092K| 246 (1)| 00:00:03 |
| 13 | TABLE ACCESS FULL | POF_NETVALUE_HIS | 69950 | 2254K| 246 (1)| 00:00:03 |
--------------------------------------------------------------------------------------------------------
下面是slq-monitor的内容,很明显,sql monitor里的显示第6步用了TEMP 320G,这一步是hash join,占用temp是正常的,但是占用这么多就不正常了。这一步的hash是由第7步和第13步的结果集做的。第13步是一个全表扫描问题不大,第7步就由很大问题了。这个第7步是MERGE JOIN CARTESIAN,这明眼一看就是笛卡尔积啊,我一直觉得这货没有存在的意义,而且一旦他出现,问题会大大的,看后面这一步最终返回的结果集行数是2G。
SET LONG 1000000
SET LONGCHUNKSIZE 1000000
SET LINESIZE 1000
SET PAGESIZE 0
SET TRIM ON
SET TRIMSPOOL ON
SET ECHO OFF
SET FEEDBACK OFF
SELECT DBMS_SQLTUNE.REPORT_SQL_MONITOR(
SQL_ID => '8j32rtkhswuwp',
TYPE => 'TEXT',
REPORT_LEVEL => 'ALL') AS REPORT
FROM dual;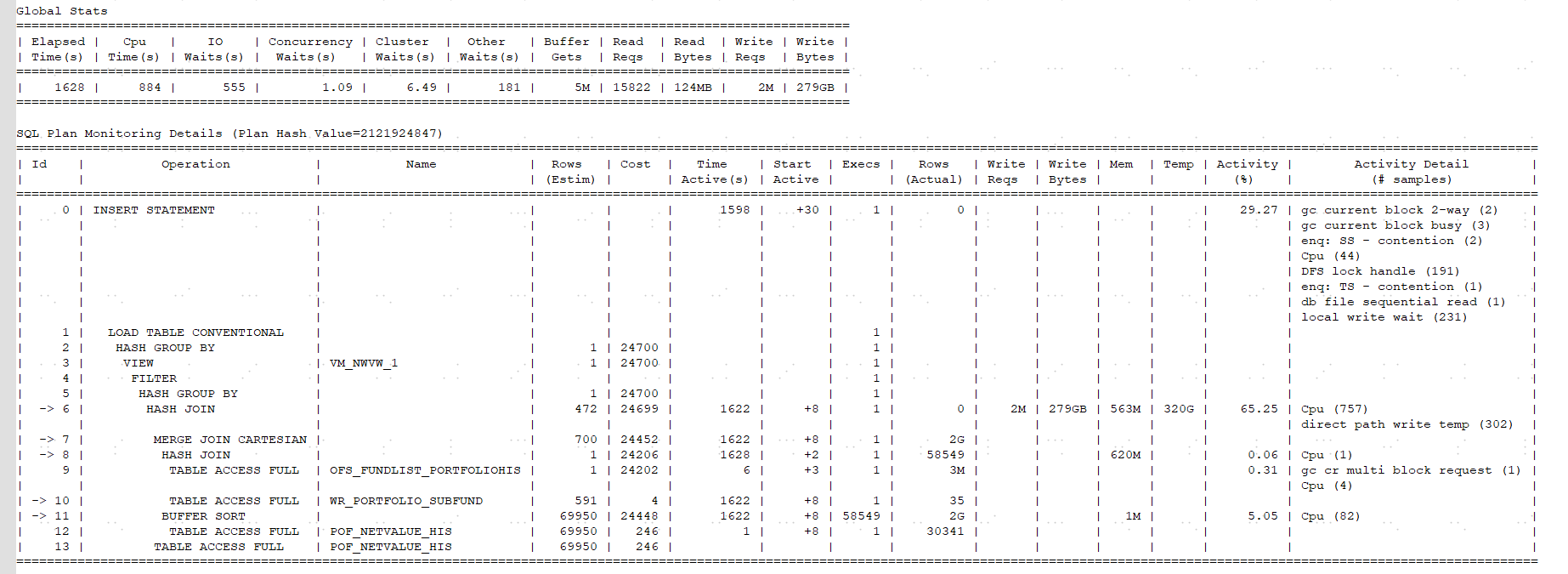
我查了下,这货出现一般是有三种情况:1、应用需求。2、缺少关联条件。3、表的行数很少,oracle 优化器评估了下,这样返回很快。其实前两种都是没有关联条件产生的。这个sql我简单看了下,不是这种情况,不缺条件。那就剩下第三种情况了,我们仔细看,执行计划中,这个笛卡尔积是由第8步和第11步产生的,这个第8步评估出来才1行,第11步评估出来69950行,这个人家oracle就有理由了,你一个1行的表和一个69950行的表关联,我用笛卡尔积的方式也没啥消耗啊。再往后看,实际上第8步实际返回58594行,这就麻烦了,笛卡尔积是一个两个表相乘的关系,一个6w条数据的表和一个7w条的结果集,返回的结果集可想而知。
那稳了,问题就出在第8步啊,评估是1行,咋返回了6w行的。这个第8步又是由第9步和第10步产生的结果,这个第9步也是一样的问题,评估出来1行,实际返回3M行,第9步就是最内层了,那就看看他是啥问题吧,这是一个对表OFS_FUNDLIST_PORTFOLIOHIS的全表扫描,这个时候我就回去看display_cursor里的第9步的谓词条件,两个过滤条件PORTFOLIOTYPE和OCCURTIME,都用了绑定变量。
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("HI"."NAV_DATE"=MAX("P"."NAV_DATE"))
6 - access("HI"."TICKER"="P"."TICKER" AND "HIS"."FUNDCODE"="HI"."TICKER")
8 - access("HIS"."FUNDCODE"="WR"."TICKER")
9 - filter(("HIS"."PORTFOLIOTYPE"=:6 AND SUBSTR("HIS"."OCCURTIME",0,8)=:5))
再看sql monitor里的绑定变量值,这个OCCURTIME是时间字段20220427,
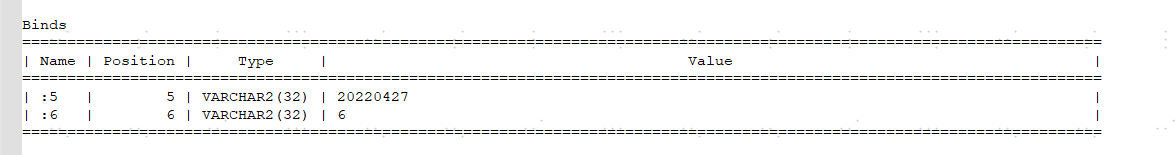
这个时候其实我大概率有想法了,因为碰到过类似的情况,我果断去查了下表的统计信息的情况。有木有发现问题,统计信息收集的时间是21年12月12号,带入的绑定变量值是22年4月27号,那oracle可不就认为你数据量极少吗,问题解决起来就容易了,统计信息收起来,解决战斗。

总结:
1、这种情况我碰到很多次哈,由于统计信息不准导致执行计划异常的情况,oracle自己的统计信息收集是由时间窗口和规则的,这个不一定适用于所有的业务,如果统计信息不准产生了比较大的影响,还是需要酌情调整统计信息收集的方式。
2、这个笛卡尔积的问题,其实还可以通过设置隐藏参数_optimizer_mjc_enabled来关闭笛卡尔积的,系统层和会话层都可以,在我以前的公司,关闭笛卡尔积已经是标准化参数了。
评论

 0 点赞 0 点赞
0 点赞 0 点赞 0
0 ,就是有些文字被自动翻译了
,就是有些文字被自动翻译了 点赞
点赞 0
0 点赞
点赞