




DSE精选文章
地理标记实体扩展参与系统中Top-k实体的高效索引
Efficient Indexing of Top-k Entities in Systems of Engagement with Extensions for Geo-tagged Entities
文章介绍
目前,基于参与系统(SOE,Systems of Engagement)模型的新一代企业管理系统发展迅速。SOE可被视为一组实体组成,每个实体由具有动态嵌入链接(即子文档)的单个父文档建模,其中包含来自网络实体的多模态信息。由于SOE中的实体通常使用关键字进行查询,因此该文通过考虑父文档和子文档的相关性分数,有效地检索相关的前k个实体。这项工作的主要贡献有四个方面:
(1)提出了一种有效的基于位图快速识别候选实体集的方法,其父文档包含所有查询的关键字。同时提出了一种该方法的变体,通过利用关键字流行度的偏差来减少内存的消耗。
(2)提出了双层HI-tree索引结构,同时使用了哈希和倒排索引,用于高效的文档相关性得分查找。
(3)提出了一种基于R树的方法,将上述方法扩展到实体被地理标记的情况中。
(4)在真实数据集和合成数据集上进行了全面的实验,证明了所提出的方案确实能够在可接受的查询响应时间内表现出良好的top-k结果召回性能。
实验效果
图1展示了一个面向SOE的CRM应用程序,其中实体是客户,如Alice、Bob和Chuck。观察Alice的子文档如何构成其在电子邮件系统、电话系统、社交网络页面和产品评论页面上的交互。SOE可以包含每个实体的不同类型的数据模型(例如电子邮件、电话、社交页面等),可以通过采用数据集成方法进行集成。除此之外,该文还考虑到可以转录成文本的多模式数据(例如,电话的语音数据)。
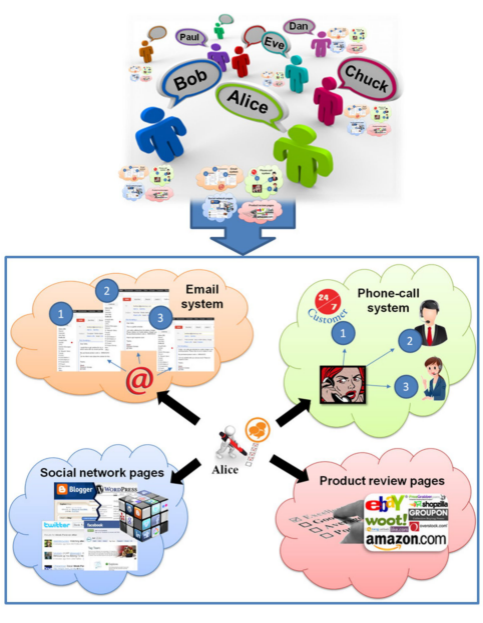
图1 面向SOE的CRM应用程序
如图2所示,描述了面向SOE的CRM应用程序的父文档和子文档的示例。举例来说,假设Alice最近购买了三星Galaxy note 2手机,并就其手机充电器问题对各种系统发表了评论。该公司可能希望找到投诉手机充电器问题的top-k个客户。这里,top-k查询可以基于与充电器问题相关联的关键字在客户的各种交互网络中的出现频率来定义。
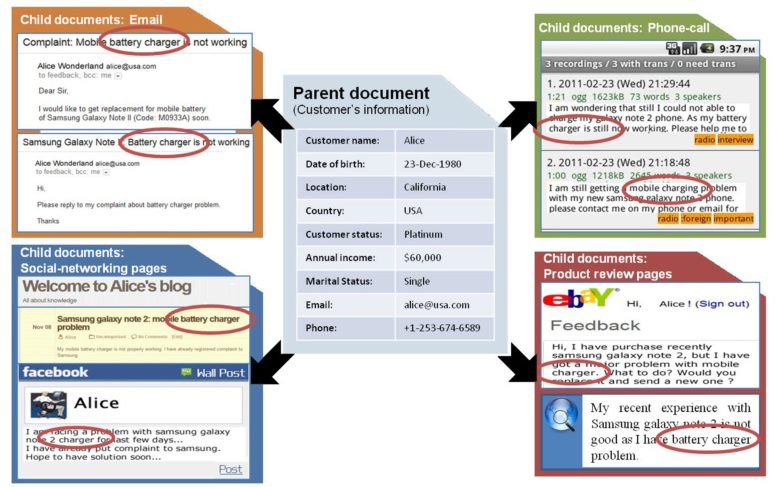
图2 面向SOE的CRM应用程序中父文档和子文档的示例
如图3和图4所示,分别描述了计算父文档相关性分数的示例。在图3中,父文档和子文档分别是D1到D4和C1到C6。对应于D1、D2、D3和D4的子文档分别为{C1、C2、C3}、{C3、C5}、{C1、C5}和{C1、C2、C4、C6},在其中可以进行一个具有两个关键字a1和a2和的top-k查询。
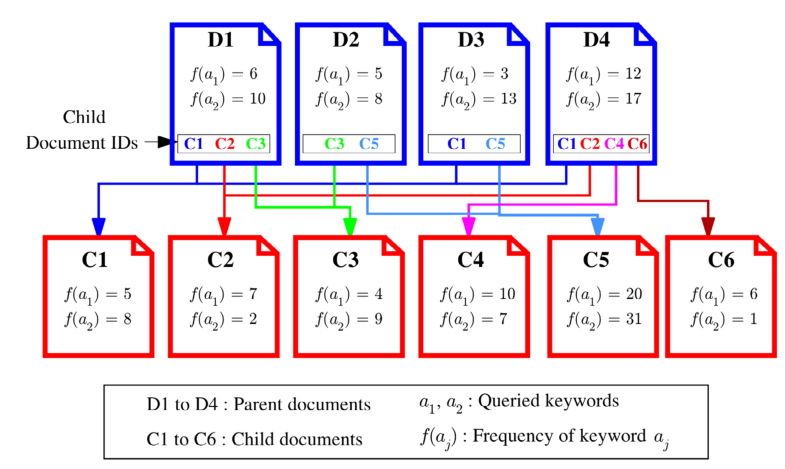
图3 嵌入链接的文档语料库
图4以两种方式显示了D1到D4 w.r.t.a1和a2的相关性分数的计算,分别对应考虑和不考虑子文档中查询关键字出现的情况。
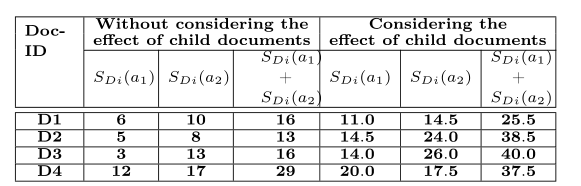 图4 计算文档相关性分数
图4 计算文档相关性分数
如图5所示,给出了如何进行搜索以查找给定的桶。为了快速定位与给定关键字搜索查询相关的哈希桶,哈希桶以B+树的形式组织。B+树中散列桶的排序是基于单词的字典顺序,此顺序可以作为标识符分配给这些桶。
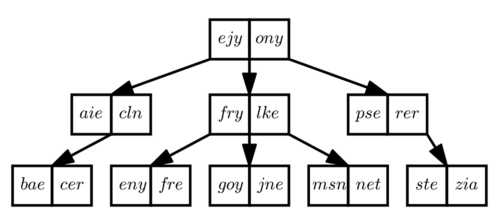
图5 通过哈希树查找相关桶示例
如图6所示,描述了父文档在空间中各自位置的示例,图(a)中每个点表示父文档的位置(b)描述了(a)中父文档在空间中的分布相对应的R树的结构。观察通用空间如何划分为三个MBRs,即R1、R2和R3。进一步观察R1如何细分为MBRs A、B和C;R2细分为D、E和F,而R3细分为G、H和I。
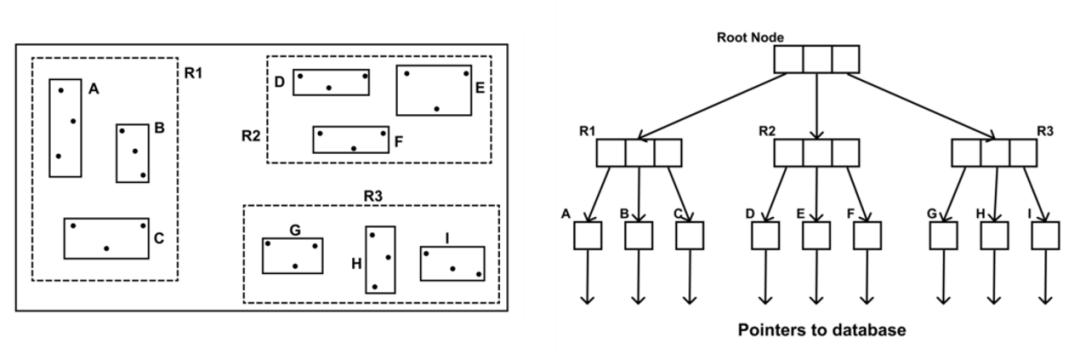
(a)父文档在空间中分布 (b) R树索引结构
图6 父文档在空间中分布的示例
结语
该文通过有效检索SOE中的前k个实体解决了基于关键字的查询问题,并将上述问题扩展到处理地理标记实体。特别地,该文提出了一种有效的基于位图的方法来快速识别候选集,通过利用关键字流行度的偏差来减少内存消耗的变体。进一步作者提出了使用散列索引和倒排索引的两层HI-tree 索引,用于文档相关性分数高效查找。此外,该文还讨论了一种基于R树的方法进行扩展,以解决地理标记实体的问题。
作者简介




期刊简介



