




ICML 2022 | GraphFM: Improving Large-Scale GNN Training via Feature Momentum
文章信息
「来源」:Proceedings of the 39th International Conference on Machine Learning(ICML) 2022
「标题」:GraphFM: Improving Large-Scale GNN Training via Feature Momentum
「作者」:Haiyang Yu, Limei Wang, Bokun Wang, Meng Liu, Tianbao Yang, Shuiwang Ji
「链接」:https://proceedings.mlr.press/v162/yu22g.html
内容简介
训练用于大规模节点分类的图神经网络 (GNN) 具有挑战性。一个关键的困难在于获得准确的隐藏节点表示,同时避免邻域爆炸问题。在这里本文提出了一种名为特征动量(FM)的新技术,它在更新特征表示时使用动量步骤来合并历史嵌入。作者开发了两种特定算法,称为 GraphFM-IB 和 GraphFM-OB,它们分别考虑批内和批外数据。GraphFM-IB 将 FM 应用于批内采样数据,而 GraphFM-OB 将 FM 应用于批内数据的 1 跳邻域的批外数据。作者为 GraphFM-IB 提供了收敛性分析,并为 GraphFM-OB 提供了一些理论见解。根据经验,作者观察到 GraphFM-IB 可以有效缓解现有方法的邻域爆炸问题。此外,GraphFM-OB 在多个大规模图数据集上取得了可喜的性能。
特征动量(FM)在历史节点嵌入上应用动量步骤来估计准确的隐藏节点表示。基于FM,作者分别开发了基于子采样节点估计和伪满邻域估计的两种算法。第一个算法,称为 GraphFM-IB,在对批内节点进行采样后应用 FM。GraphFMIB 递归地对目标节点的 1 跳邻居进行采样,然后使用动量步骤使用来自其采样邻居的聚合嵌入来更新它们的历史嵌入。第二种算法,称为 GraphFM-OB,使用基于集群的采样来绘制批内节点,并使用 FM 使用批内节点传递的消息更新 1 跳批外节点的历史嵌入。GraphFMOB 的操作如下图所示。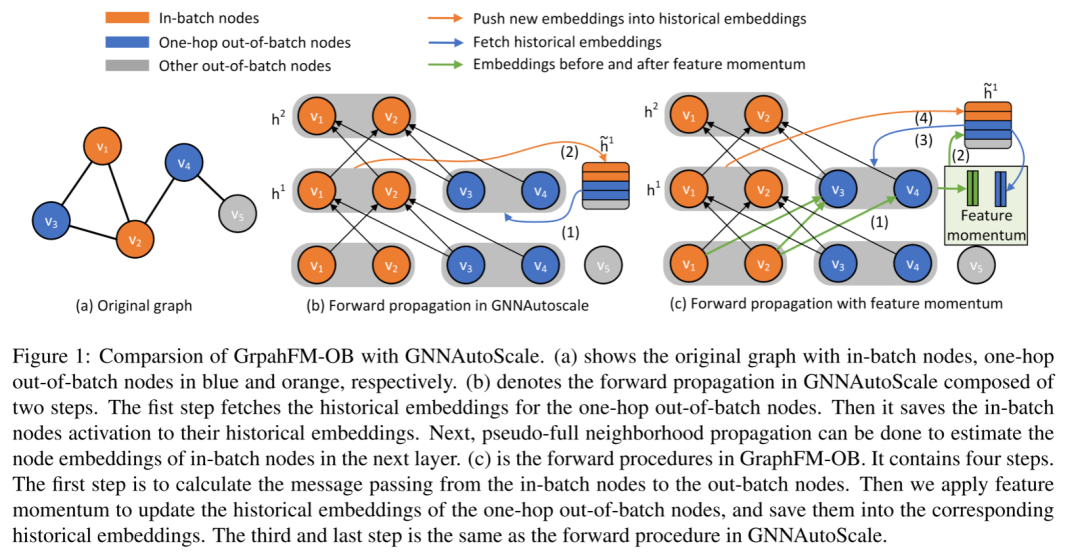 GraphFM-IB 理论上可以收敛到具有足够迭代次数和恒定批量大小的静止点。GraphFM-OB 被证明具有一些理论洞察力,可能缓解历史嵌入的陈旧问题。本文进行了广泛的实验来评估我们在多个大规模图上的方法。结果表明,GraphFM-IB 的性能优于 GraphSAGE,并取得了与其他基线相当的结果。重要的是,当仅对一个邻居进行采样时,GraphFM-IB 实现了与使用大批量时相似的性能,从而缓解了邻域爆炸问题。本文还表明 GraphFM-OB 在各种大规模图形数据集上优于当前基线
GraphFM-IB 理论上可以收敛到具有足够迭代次数和恒定批量大小的静止点。GraphFM-OB 被证明具有一些理论洞察力,可能缓解历史嵌入的陈旧问题。本文进行了广泛的实验来评估我们在多个大规模图上的方法。结果表明,GraphFM-IB 的性能优于 GraphSAGE,并取得了与其他基线相当的结果。重要的是,当仅对一个邻居进行采样时,GraphFM-IB 实现了与使用大批量时相似的性能,从而缓解了邻域爆炸问题。本文还表明 GraphFM-OB 在各种大规模图形数据集上优于当前基线
提出的特征动量方法
算法设计动机
递归计算每一层所有节点的特征表示。可以将 表示为:
其中 是参数化的非线性函数。因此可以将优化问题写成多层嵌套函数:
解决 GNN 优化问题的两个挑战是(i)更高层 的节点表示可能取决于前一层中大量节点的表示;(ii) 当节点总数很大时,并非所有节点的表示都可以在每次迭代中重新计算。为此,GNN 训练通常伴随着每一层的节点采样。然而,当每个节点的采样邻域不够大时,使用子采样节点计算每一层的特征表示可能会导致很大的优化误差。非采样相邻节点的历史嵌入已用于减少此错误。然而,根据 mini-batch 的大小,历史嵌入可能已经过时并且也可能有很大的错误。为了解决这些问题,本文引入了节点动量特征。为了激发这个想法,考虑以下两级函数:
本文假设 及其梯度的评估代价高昂,但无偏随机版本很容易计算。特别是让 和 表示取决于随机变量 的随机版本,使得:
批量节点的特征动量
GNN 训练中的一个基本算子是使用其较低级别的特征嵌入从其邻域节点计算每个节点的新特征嵌入。这个算子可以用以下两步来表示:
其中第一步将节点 的直接邻域中的节点的表示聚合为单个向量 ,第二步将节点的当前表示 与聚合的邻域向量连接并通过具有激活函数 σ(·) 和权重 的非线性层。特别感兴趣的是,zuozhe 考虑平均聚合器:
具体算法如下:
批量外节点的特征动量
本文提出了一种基于 GNNAutoScale 的方法,将特征动量应用于批外节点。为此,作者首先描述 GNNAutoScale (Fey et al., 2021)。它基于伪全邻域估计,使用所有邻域来计算批内节点的新特征表示。然而,并不是所有的邻居都更新了他们在前一层的特征表示,因为有些邻居不在采样批次中。为了解决这个问题,使用了这些批次外节点的历史嵌入。让 表示批内节点。然后对于每个节点 ,作者用 表示它的邻域,包括它自己。可以将其分解为两个子集, 和 。在 GNNAutoScale 中,节点 的第 k 层嵌入计算为:
实验分析
数据集
作者评估了本文提出的算法 GraphFMIB 和 GraphFM-OB,并对五个大型图的节点分类任务进行了广泛的实验,包括 Flickr (Zeng et al., 2019), Yelp (Zeng et al., 2019), Reddit (Hamilton et al., 2017)、ogbn-arxiv (Hu et al., 2021) 和 ogbn-products (Hu et al., 2021)。它们包含数千或数百万个节点和边,下表中总结了这些数据集的统计信息: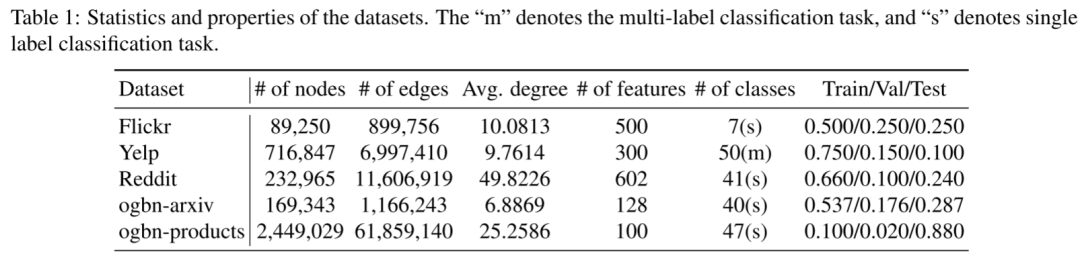
实验结果
本文首先研究采样邻居大小对 GraphSAGE 和 GraphFMIB + SAGE 性能的影响,并表明提出的 GraphFM-IB 可以通过更小的采样邻居大小实现具有竞争力的性能。如下图所示,2 层 GraphSAGE 的性能与采样的邻居大小高度相关。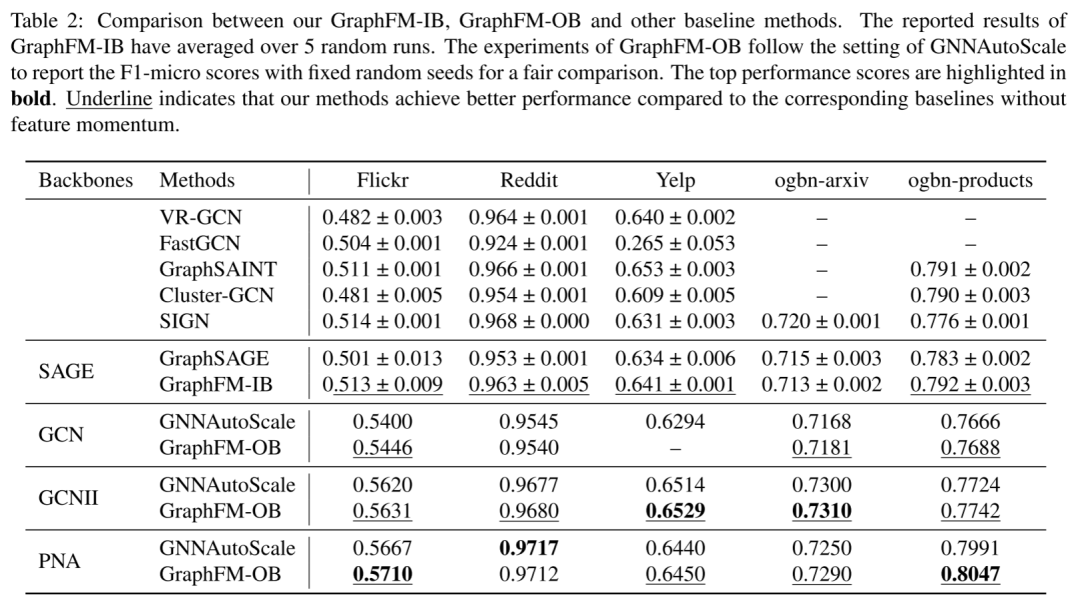 它需要对每个节点至少采样 8 个邻居以保证良好的性能。相比之下,GraphFM-IB + SAGE 仅用 1 个采样邻居就取得了很好的效果。因此,可以通过使用特征动量来减少采样的邻居大小,同时获得有竞争力的性能。
它需要对每个节点至少采样 8 个邻居以保证良好的性能。相比之下,GraphFM-IB + SAGE 仅用 1 个采样邻居就取得了很好的效果。因此,可以通过使用特征动量来减少采样的邻居大小,同时获得有竞争力的性能。
总结
为了获得准确的隐藏节点表示,本文「提出了特征动量 (FM) 以将历史嵌入合并到 Adam 更新样式中」。基于 FM,本文「开发了两种算法,GraphFM-IB 和 GraphFM-OB,分别具有收敛保证和一些理论洞察力」。大量实验表明,本文提出的方法可以「有效缓解邻域爆炸和陈旧问题,同时取得可喜的结果」。

