





一、前言
带标签属性图(LPG)是具有标签和属性的有向图,其中标签定义顶点和边的不同子集(或类),属性是表示真实世界属性的任意数量的键值对。LPG模型在实际应用中可以很容易地表示许多复杂关系,并具有高表达性的优点。此外,方便理解的特性使其在数据库社区中越来越流行。
1.2、LDBC基准
LDBC SNB模拟了一个类似于Facebook的社交网络,由人及其活动组成。它具有丰富的实体、关系和属性类型,模拟了真实社会网络中信息架构的特征。它提出了三种查询工作负载:交互式、商业智能和图算法。由于最后一个适用于图分析系统,这超出了本文的范围,因此本文仅将前两个作为测试对象,包括评估商业图数据库处理实际业务需求的能力。
交互工作负载定义了以用户为中心的事务式交互查询,包括8个事务更新(IU)、7个简单只读(IS)和14个复杂只读(IC)查询。其中,IU查询是简单的顶点或边插入。IS和IC查询都是从特定顶点开始的信息检索操作。不同之处在于,它的目标是简单的模式匹配,最多访问2跳顶点并收集基本数据,而IC定义复杂的路径遍历并返回计算和聚合结果。
商业智能(BI)工作负载定义了25个分析查询,以响应业务关键问题。与交互式工作负载不同,BI查询开始对最近的具有多个顶点的图数据库系统331进行实证研究,并包含更复杂的图分析和结果统计操作,旨在收集有价值的业务信息。LDBC SNB数据集的结构和工作负载的详细定义见官方规范。
二、相关工作
随着图数据库的发展,进行了许多评估和基准测试,以比较这些产品。对于现有的评估工作,一些仅侧重于列出图数据库的特征,而没有任何实证探索,一些将评估局限于微观操作、小规模数据和有限的产品集,一些旨在展示自己产品的优势。同时,许多现有的基准测试无法评估图数据库处理实际和业务需求的能力。例如,微基准仅限于微操作,而RDF基准仅适用于查找RDF结构。本文的实验研究填补了这一空白。我们不仅总结了流行和年轻企业图数据库的特征,还使用基准LDBC SNB评估了大型数据集上代表性产品的性能,该基准LDBC模拟了现实的社交网络,并定义了微观和宏观查询工作负载。
三、图数据库
图数据库是针对传统关系数据库的局限性而出现的一种NoSQL数据库。图数据库经过高度优化,可用于处理连接数据。近年来,由于图数据库的高性能和易用性,图数据库的普及率急剧增加。我们概述了当前商业市场中的图数据库系统,包括发展良好的图和多模型数据库系统,如Neo4j、JanusGraph(successor of Titan)和ArangoDB,以及其他相对年轻的系统,如AgensGraph、TigerGraph、LightGraph和Nebula。表1总结了它们的基本特性,包括数据库类型、存储结构、是否开源(Op.)、是否支持分布式处理(Ds.)、是否事务(Ta.)、是否无模式(Sf.)、实现语言(Impl.)和查询语言(Lang.)。
从表1中,我们可以看到,作为企业产品,这些图数据库系统几乎都是事务性的,具有ACID保证。此外,大多数的原生图数据库更喜欢自行设计的存储结构和图查询语言,而混合数据库更灵活,支持多种存储引擎或查询语言。此外,随着对处理大数据的需求不断增加,许多产品都以高可扩展性为目标,支持数据的分布式存储,并且可以部署在机器集群中。在所有研究的图数据库中,只有TigerGraph和LightGraph不是开源项目,因此对其存储技术的研究有限。
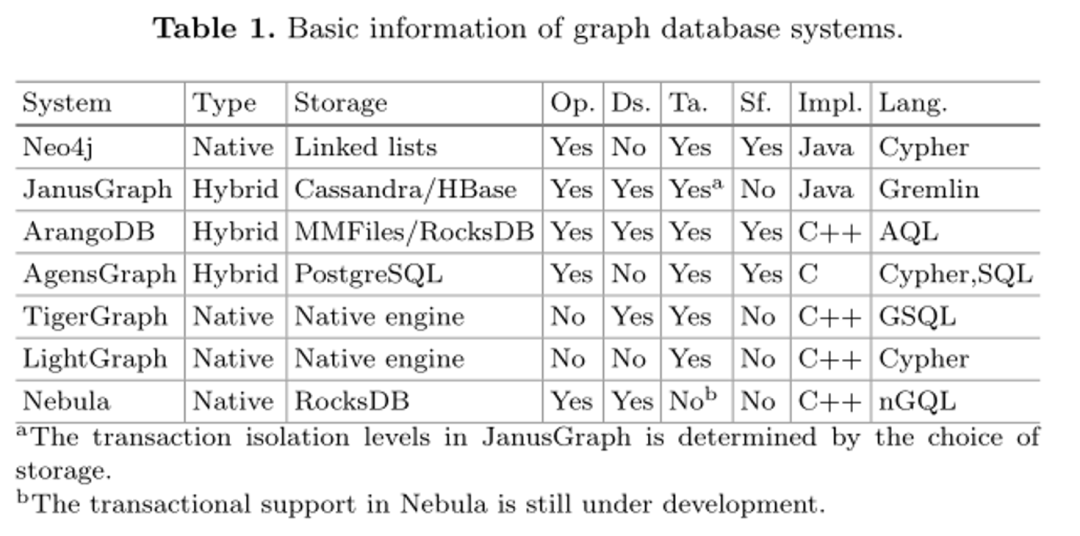
然后,我们选择了几个系统在基准LDBC SNB的基础上进行进一步的研究和性能评估。总之,选择标准是:1)支持带标签的属性图模型,2)支持声明性图查询语言,3)支持OLTP,4)可以在LDBC SNB中完全实现查询工作负载,5)完全许可可用。因此,我们采用Neo4j、AgensGraph、TigerGraph和LightGraph进行调查和基准测试。特别是后三个,作为年轻的图数据库,在现有的工作中很少得到关注,尽管它们在自己的报告中显示了良好的性能。
四、实验
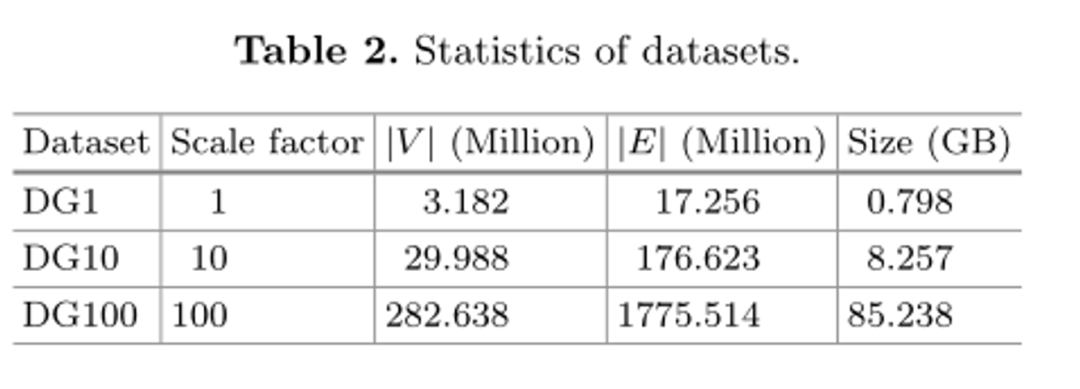
我们使用LDBC数据生成器生成了三个不同尺度的数据集。所有数据集具有相同的结构。表2中总结了数据集的统计数据。我们可以发现,顶点和边的数量以及数据集的原始大小几乎与比例因子呈线性增长。
对于基准LDBC SNB,在交互和商业智能工作负载中总共有54个查询。它们在四个图数据库中的实现是从他们的官方人员那里获得的,或者是我们自己实现的,比如AgensGraph、IU中的BI查询和LightGraph中的IS查询,尽可能保证每个数据库中查询语句的最佳性。为了进行公平的比较,我们对所有系统中的相同查询采用相同的参数。请注意,对于LightGraph,由于其Cypher接口尚未完全实现和优化,我们仅使用Cypher实现了IU和IS查询,并使用作者提供的C++存储过程进行了其他实验。其他三个数据库由查询语言操作。我们在一台运行Ubuntu16.04.5操作系统的机器上进行了所有实验,该机器具有两个20核处理器Intel Xeon E5-2680 v2 2.80 GHz、96 GB主内存和960G NVMe SSD。我们测试了快速NVMe SSD存储的性能,因为它已经是数据库系统的默认选项。为了进行实验,我们将每个微查询(IU和IS)运行100次,每个宏查询(IC和BI)运行3次,并将平均运行时间设置为结果。默认情况下,我们将每个查询处理的超时设置为1h,并使用符号“TO”和“OOM”分别表示超时和内存不足。
数据导入:由于原始数据量大,数据集被大量导入图数据库系统。数据导入也是生产中的常见操作。我们在图1中分别给出了四个数据库的数据导入时间和每个加载数据集的存储大小 。
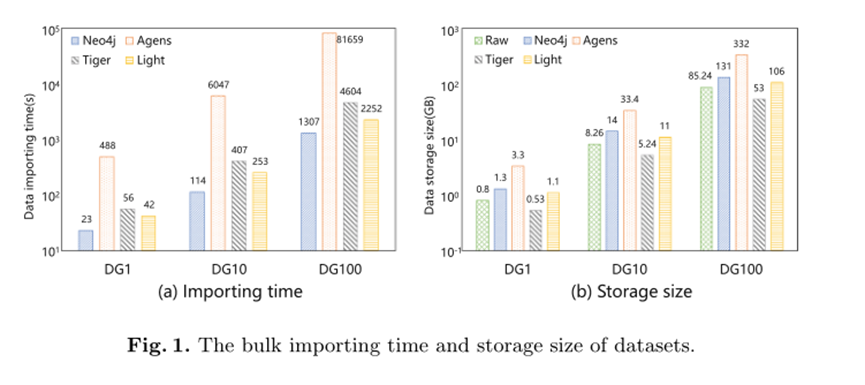
图1-a显示,对于所有三个比例数据集,Neo4j中的数据导入时间最短,其次是LightGraph、TigerGraph和AgensGraph。实际上,即使我们考虑Neo4j中的索引创建时间和LightGraph中存储过程的预处理时间,它们仍然比TigerGraph和AgensGraph具有更好的批量导入性能。AgensGraph受其第三方关系存储引擎PostgreSQL的限制,数据批量导入的速度比其他系统慢得多。对于DG100,AgensGraph加载数据大约需要一天时间,这在通常使用中是不合理的。图1-b显示了四个数据库中三个数据集的原始和加载存储大小,表明TigerGraph需要最少的空间来存储数据,甚至比原始数据更少,其次是LightGraph、Neo4j和AgensGraph。LightGraph中的存储消耗大约是TigerGraph的两倍,Neo4j大约是Tiger Graph的三倍。AgensGraph需要最大的存储空间。基于上述实验,Neo4j在大数据导入效率方面表现最佳,但其存储成本非常大。TigerGraph存储数据花费的空间最少,但加载数据需要较长的时间。LightGraph总体上表现良好。AgensGraph显示了最差的性能。
处理交互式查询。交互式工作负载由IU、IS和IC查询组成。其中,IU和IS都是微操作。IC是更复杂交互场景下的宏查询。我们选择了几个有代表性的结果,并在线提供了完整的数据。由于IU和IS操作的运行时间不超过1秒,我们以毫秒为单位记录它们,并以秒为单位记录IC查询的运行时间。
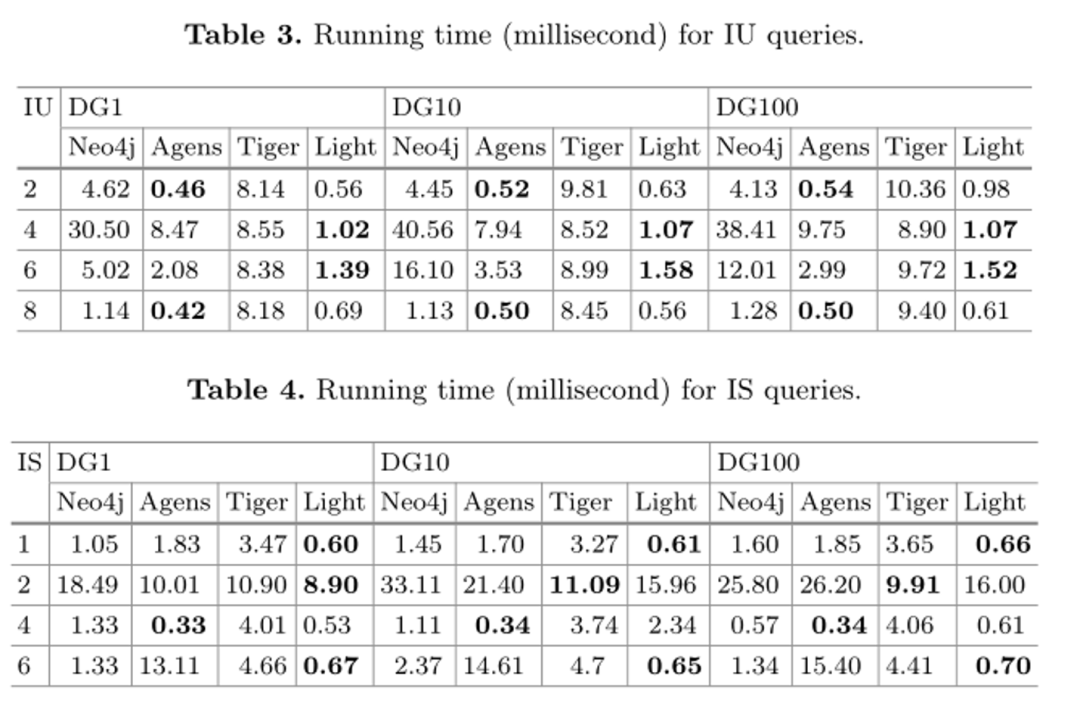
表3列出了IU查询的处理时间,表明LightGraph和AgensGraph比其他两个数据库更高效。LightGraph擅长插入顶点,如IU 4和 I U 6,AgensGraph擅长于插入边,如Iu2 和 l U 8。Neo4j在更新边方面比TigerGraph快,但在更新顶点方面慢。表4中列出了IS查询的实验结果。我们发现LightGraph在大多数情况下是最有效的。根据完整数据,TigerGraph和AgensGraph仅在一些情况下显示良好性能,如IS 2和IS 4,而在大多数情况下比Neo4j更差。
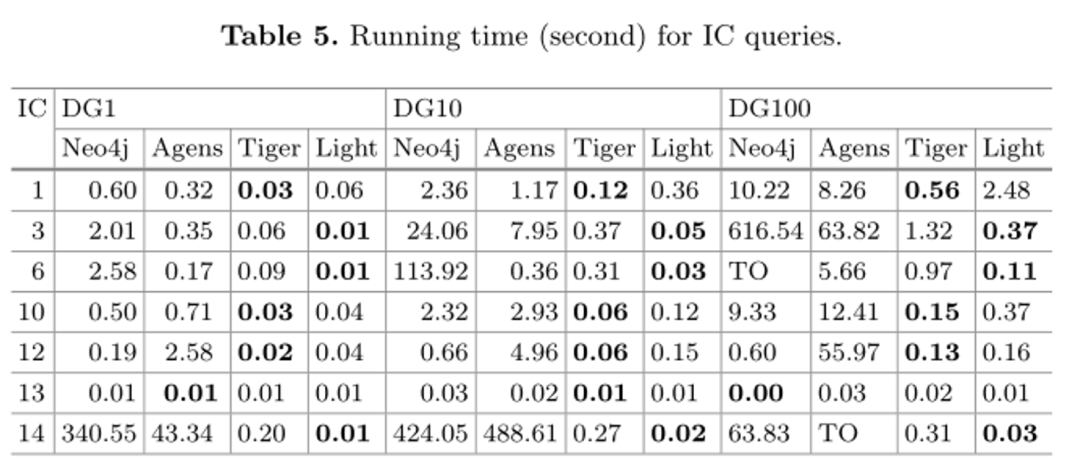
表5显示了IC查询的运行时间,图数据库之间的性能有很大差异。总的来说,TigerGraph和LightGraph都表现出了高效的性能,差异很小,而AgensGraph(对最近的图数据库系统337和Neo4j进行的一项实证研究)的性能比其他两个系统差得多。在为DG1和DG10执行IC 14的情况下,Neo4j甚至比LightGraph慢四个数量级。然而,对于IC 13,它需要返回两个给定顶点之间的最短路径的长度,结果显示所有数据集的所有数据库之间几乎没有差异。这是因为Neo4j和AgensGraph都支持关键字最短路径,并优化了内部计算过程。对于交互式工作负载,所有数据库在微查询中都工作得很好,但在宏查询中表现出很大的差异。LightGraph在大多数情况下性能最佳。 TigerGraph仅在处理复杂查询时有效,但在微操作方面不好。AgensGraph和Neo4j适用于微操作,但在处理IC查询时,它们的性能比其他两个数据库差得多。
处理商业智能查询。考虑到更多的实际业务应用程序,业务智能工作负载要求数据库具有更高的性能,以响应复杂的场景。表6列出了12个代表性查询作为示例,以秒为单位记录结果。实际上,所有图数据库都不能成功地在所有数据集中执行所有BI查询。总体而言,TigerGraph表现最佳,其次是LightGraph。Neo4j和AgensGraph的性能仍然很差,在许多情况下,结果是超时。在为DG1执行BI 7的情况下,Neo4j是四个数量级,AgensGraph比LightGraph慢五个数量级。这显示了很大的性能差异。尽管查询语句优化可能有一些原因,但最大的问题在于数据存储和查询处理技术。例如,对于BI 16,AgensGraph即使在DG1下也超时。通过拆分其原始查询语句,我们发现AgensGraph无法在合理的时间内匹配模式(Person)-[:KNOWS*3..5](Person),这可能与其存储结构或查询执行机制有关。
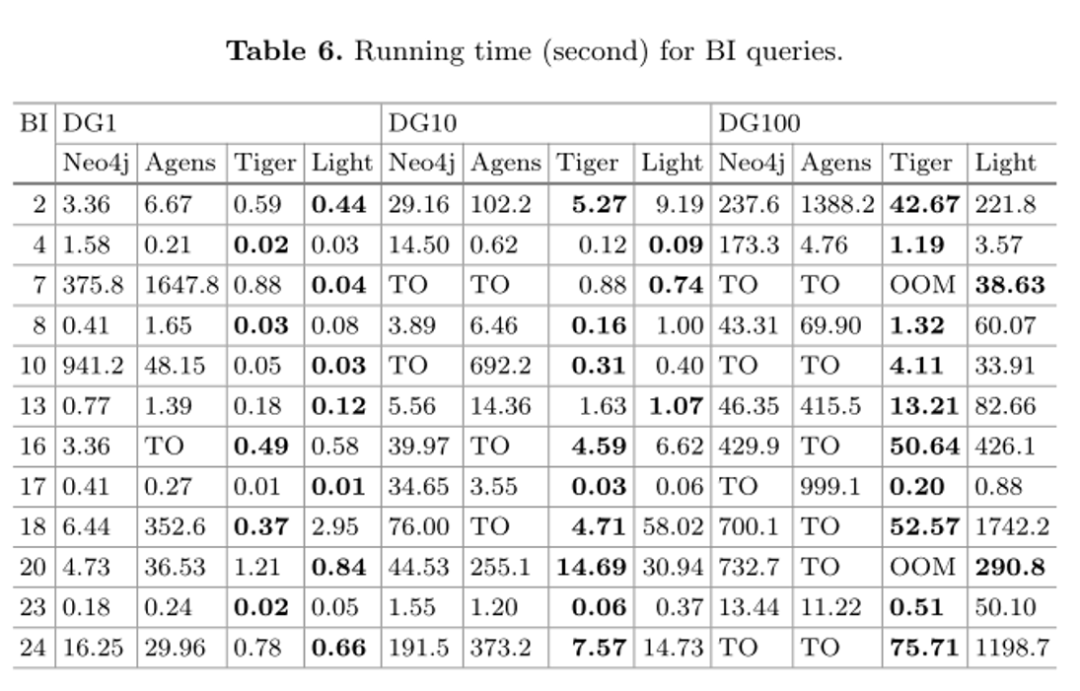
在比较TigerGraph和LightGraph时,对于DG1,它们的性能几乎没有差异。但随着数据集规模的增加,光图的处理时间比TigerGraph的处理时间增加得更快。因此,在DG10和DG100下,TigerGraph效率更高,部分原因在于内置并行处理机制和GSQL实现的存储过程类查询语句。然而,对于DG100中的BI 7 和 B I 20,TigerGraph内存不足,但LightGraph成功完成了它们,表明在处理大型数据集时,TigerGraph需要更多内存。
我们仅列出部分实验结果,完整数据可在线获取。根据全部结果,这四个数据库表现出不同的性能,没有人能在所有场景中表现最佳。调查结果总结如下:
Neo4j是用户友好的,也是数据导入中最高效的。然而,它仅适用于微查询和小规模数据集,在运行复杂的商业智能查询时表现出较差的性能;
AgensGraph可以很好地处理SQL伴随的工作负载和简单的更新和查询操作,但在处理复杂查询和管理大型数据集时性能非常差;
TigerGraph在复杂的商业智能查询(如IC和BI查询)方面功能强大,尤其是在DG100等大型数据集上。它需要最少的内存来存储数据,尽管加载数据需要花费较长的时间LightGraph是一个更平衡的产品,在所有类型的查询中都能获得良好的性能。但是,它不能完全支持密码语法,复杂查询只能通过存储过程实现;
虽然我们无法更深入地了解封闭源代码产品TigerGraph和LightGraph的实现细节,但我们列出了它们优于社区驱动图数据库的性能优势的三个潜在原因,即Neo4j和AgensGraph。第一个原因是实现中的语言差异,因为TigerGraph和LightGraph是在C++中实现的,通常表现出比实现Neo4j的语言(即Java)更高的性能。第二个原因是其他两个系统是无模式的,TigerGraph和LightGraph都有固定模式,这允许进行更多优化。第三个原因是商业产品倾向于使用先进的算法和优化来提高效率。最后,对于混合系统AgensGraph,其底层关系数据库的额外层对图数据库总体而言会遇到显著的额外成本。这四个图数据库系统都是业务产品,稳定、专业,适合处理实际和业务查询需求。根据我们的使用经验,Neo4j和AgensGraph更用户友好,支持更完整的查询语言语法。TigerGraph和LightGraph的查询语句更像是存储过程,需要一些表示查询的技术。最重要的是,这两个产品不是免费的,用户无法自行更改或优化。






