




spark-SQL全代码生成
火山模型是数据库界已经很成熟的解释计算模型,sparkSQL中使用了火山模型。由于火山模型的CPU效率较低,在当下成为计算的瓶颈。为了优化spark作业的CPU和内存效率(相对于被认为足够快的网络和磁盘I/O),使得其性能更接近现代硬件的极限,提出Tungsten项目(钨丝计划)。Tungsten项目主要包括以下措施:
1. 内存管理和二进制处理:利用应用程序语义显示管理内存并消除JVM对象模型和垃圾收集机制。
2. 缓存感知计算:利用符合内存层次结构的算法和数据结构。
3. 全代码生成:使用代码生成来更有高效地利用现代编译器和CPUs。
本文主要讨论第三项全代码生成,包括为什么使用全代码生成;spark全代码生成控制节点如何插入;spark全代码生成流程。
1. 为什么需要全代码生成
全代码生成是为了优化火山模型,提高CPU和内存效率,所以我们从火山模型入手,了解什么是火山模型,火山模型的缺点,火山模型的优化方向。探索为什么需要全代码生成。
1.1 火山模型(Volcano Iterator Model)
火山模型,是Goete Graefe于1994年在《Volcano,An Extensible and Parallel Query Evaluation System》论文中提出的独立于数据模型,可扩展和并发的灵活模型。其核心是解决数据库查询处理中的的可扩展性和并行问题。
在数据库查询中,一般是将SQL进行解析生成抽象语法树(AST),然后遍历AST,生成执行语法树。火山模型的设计思路是将执行语法树的每个节点都视作一个独立的操作(Operator),这里的操作也可以理解是一个算子。作为树的节点,往往会有父节点和子节点,当作为父节点的时候,会调用其所有子节点的操作来获取当前节点的输入数据;当作为子节点,则会被父节点调用,提供数据给父节点。这样做的优点在于:
a. 单个节点不需要关注自己的父节点或者子节点是什么类型算子和具体的实现,只需要调用接口提供的方法,获取输入数据,然后执行当前计算逻辑,最后输出。如果是要新增算子只需要实现具体的接口,并在构建语法树的时候加入到树的结构中即可,因此火山模型有良好的可扩展性。
b. 同时树的兄弟节点之间的操作可以并行进行处理,因此火山模型也有着一定的并行处理能力。
这个操作抽象成的标准接口有三个方法:open()
、next()
、close()
:
a. open
:用于Operator的初始化操作,一般也会调用子节点的该方法初始化整棵树。
b. next
:具体Operator的计算逻辑实现。父节点调用子节点next方法,计算获取子节点的数据。
c. close
:关闭Operator的生命周期。
参考一个简单的SQL查询案例,来看火山模型是如何进行的:
SELECT name FROM student WHERE teacher = 'huldarchen';复制
其火山模型调用流程及伪代码如图。

由案例可以简单的了解火山模型的调用和实现思路,核心在于next()
方法,通过自上而下调用子节点next方法,数据自下而上传递,执行完整棵树。每次调用只处理一行数据(这个在当时是为了对内存使用的优化)。
1.2 火山模型缺点
从上述可以关注到,火山模型的Operator每次只处理一行数据,这种方式在当时是为了对内存使用的优化,那个年代内存资源较为昂贵,而相比CPU的执行效率,IO执行效率会更低,因此火山模型将内存资源更多的倾向IO优化上,而不是在CPU的优化执行上。
随着计算机的发展,内存资源变得不再那么昂贵,IO性能也极大提高。所以在当下的背景下每次处理一行数据,CPU的执行效率成了最短板。CPU执行效率低有两方面:
a.每次处理一行数据,CPU新特性(多核、向量化计算)等得不到利用,计算效率低;
b.一行数据处理就得调用多次next,就造成大量的虚函数的调用,CPU的利用率不高。
虚函数
虚函数是在面向对象程序设计中特有的概念。
虚函数的重要特性是可以被子类继承和覆盖,从而实现了面向对象的重要特征之一:多态。
C++中用virtual标记的函数;java中所有的方法默认都是"虚函数",只有以关键字 final 标记的方法才是非虚函数。
虚函数为什么会导致执行效率低,涉及的底层原理较多,有兴趣的可以自行研究。
1.3 优化方向
从火山模型的缺点出发,提出其优化方向,包括两个:
1. 减少虚函数的调用,自动代码生成替换虚函数 通过自动生成Operator中的计算逻辑代码,编译执行,执行完成后向上传递,将之前的自上而下的拉模式改成了自下而上的推模式。
2. 一次取一条数据优化成一次取一组(多条)数据 这样做可以将每次next带来的CPU开销被一组数据给分摊。同时在列存场景,输入的是同列的一组数据,面对的是相同的操作,可以利用CPU的向量化计算以及CPU cache,进一步提高执行效率。
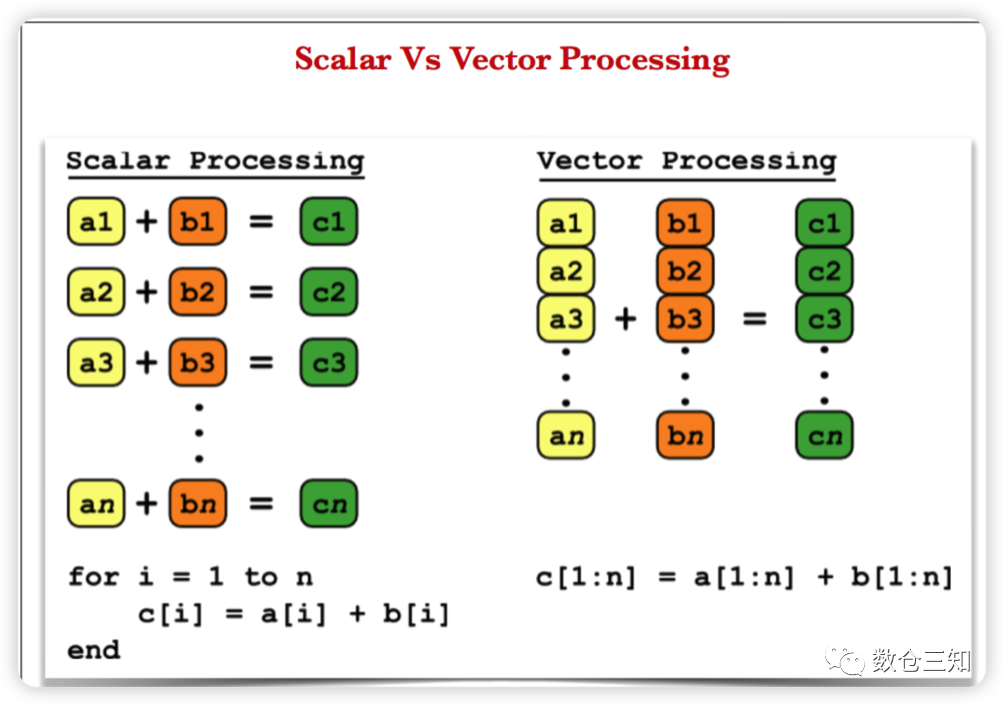
向量化:将多次for循环计算变成一次计算。如图,向量化计算就是将一个长度为N的array计算,由原来的loop每次处理一个数据共处理N次,转化成每次2(4或8)个数据,共处理N/2(N/4或者N/8)次。
有了优化方向,我们本次先探索一下spark的代码生成。
2 spark SQL codegen
2.1 全代码生成入口
sparkSQL的全代码生成的入口是CollapseCodegenStages
规则。在物理执行计划计划转化可执行计划时候即QueryExecution.prepareForExecution()
方法中规则触发。CollapseCodegenStages
规则的作用是,将生成的物理执行计划中支持代码生成的节点生成的代码整合起来。通过添加WholeStageCodegenExec
节点和InputAdapter
节点来实现。
a. WholeStageCodegenExec
表示当前stage的代码生成根节点,当前stage从此处开始执行生成代码逻辑,整合一段代码(到InputAdaper节点);
b. InputAdapter
表示当前stage的代码生成的叶子节点,当前stage的代码生成到此结束。
CollapseCodegenStages
规则的执行逻辑是对物理执行计划树进行递归添加WholeStageCodegenExec和InputAdapter节点:
def apply(plan: SparkPlan): SparkPlan = {
if (conf.wholeStageEnabled) { // 如果开启全代码生成
insertWholeStageCodegen(plan)
} else {
plan
}
}
private def insertWholeStageCodegen(plan: SparkPlan): SparkPlan = {
plan match {
// For operators that will output domain object, do not insert WholeStageCodegen for it as
// domain object can not be written into unsafe row.
case plan if plan.output.length == 1 && plan.output.head.dataType.isInstanceOf[ObjectType] =>
plan.withNewChildren(plan.children.map(insertWholeStageCodegen))
case plan: LocalTableScanExec =>
// Do not make LogicalTableScanExec the root of WholeStageCodegen
// to support the fast driver-local collect/take paths.
plan
case plan: CommandResultExec =>
// Do not make CommandResultExec the root of WholeStageCodegen
// to support the fast driver-local collect/take paths.
plan
case plan: CodegenSupport if supportCodegen(plan) =>
// The whole-stage-codegen framework is row-based. If a plan supports columnar execution,
// it can't support whole-stage-codegen at the same time.
assert(!plan.supportsColumnar)
WholeStageCodegenExec(insertInputAdapter(plan))(codegenStageCounter.incrementAndGet())
case other =>
other.withNewChildren(other.children.map(insertWholeStageCodegen))
}
}复制
以SQL为例,图解规则的执行:
select a, count (b) from testdata2 group by a复制
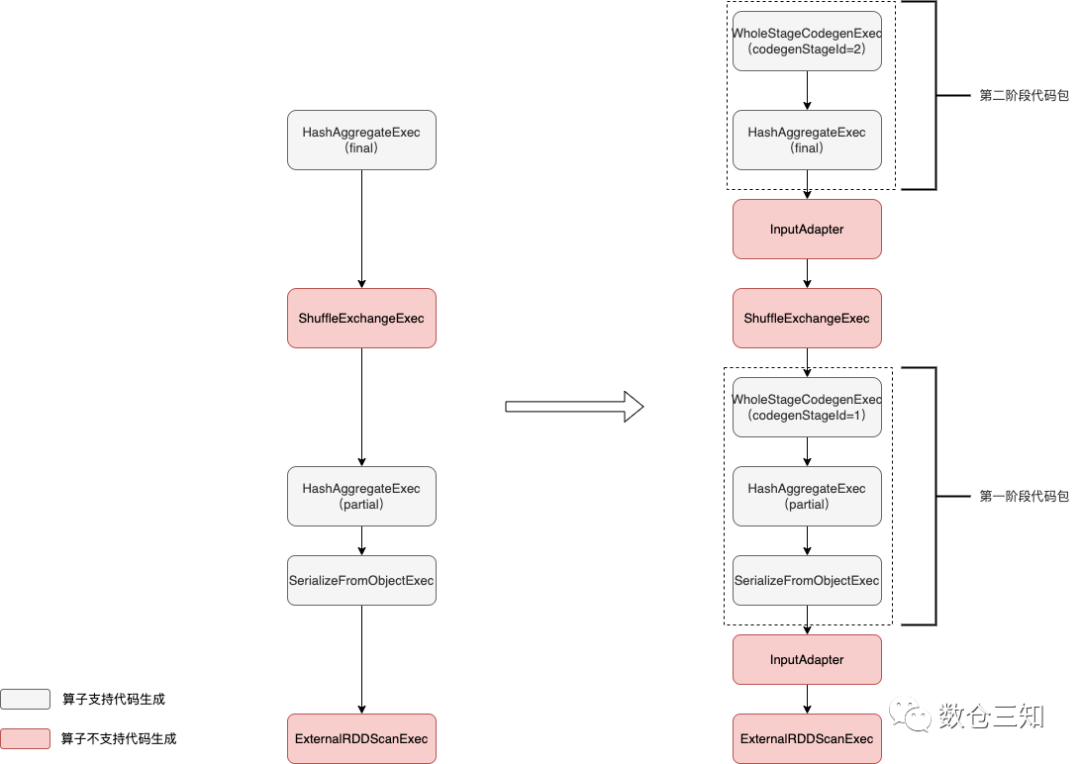
可以看出InputAdapter节点作为对应WholeStageCodegenExec所包含的子树的叶子节点,起到InternalRow的数据输入作用。
2.2 CodegenSupport
CodegenSupport
特质代表支持代码生成的物理节点,其本身继承了SparkPlan
,提供了公共方法有12个(3.3版本)和1个变量。其中,唯一的变量,代表的是支持代码生成的父节点,默认值为null;比较重要的方法有三个produce
/doProduce
、consume
/doConsume
及inputRDDs
。

a. produce
/doProduce
与consume
/doConsume
consume
/doConsume
是用来消费,返回的是该节点处理数据核心计算逻辑对应生成的代码;
produce
/doProduce
则是用来生产,返回该节点及其子节点所生成的计算逻辑代码。
在具体实现上,consume
和produce
都是final类型,子类重写doConsume
和doProduce
方法来实现具体的逻辑。两个在调用链路上存在区别,produce
方法调用的是当前节点的doProduce
方法,而consume
调用的是父节点的doConsume
方法。
b. inputRDDs
此方法用来获得产生输入数据的,从返回值类型Seq[RDD[InternalRow]]
,是多行数据。
2.3 代码生成流程
从上述可以了解代码生成是从WholeStageCodegenExec
节点开始,由于其也是SparkPlan,所以主逻辑在execute()
方法中。具体可以分为两步:代码生成和数据获取。还是以上述SQL为例用图解生成流程。(对于具体内部代码生成细节暂时不做深入探索)。
select a, count (b) from testdata2 group by a复制
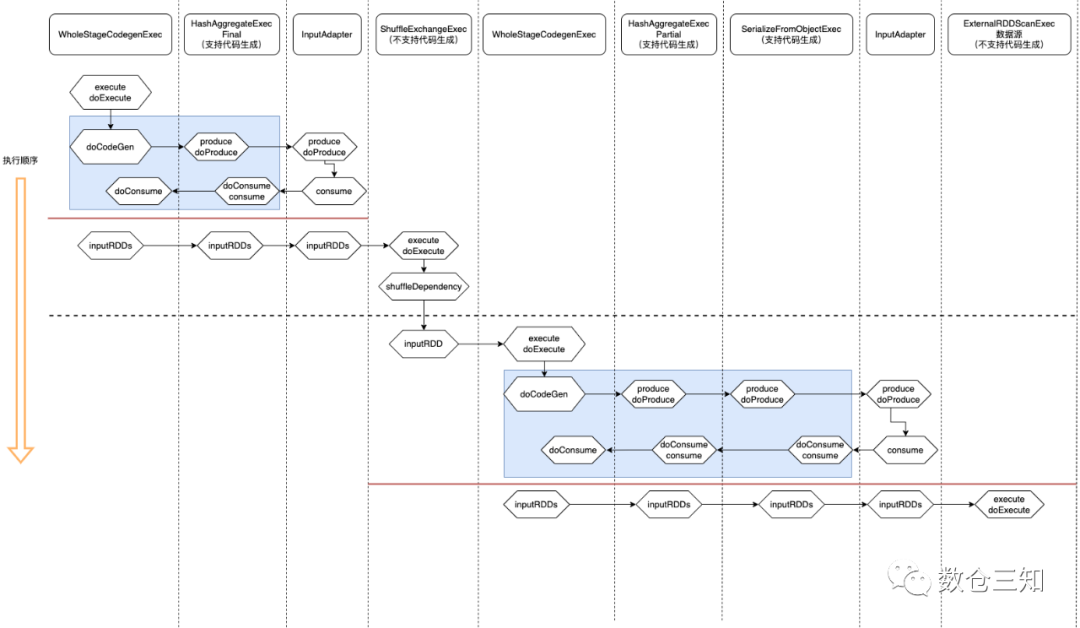
从图中可以看出:
1. 数据获取比较直接,在代码生成之后递归调用
inputRDDs
得到整段代码的输入数据。2. 代码生成较为复杂,可以看作是两个相反方向的递归过程:代码的整体框架由
produce
/doProduce
方法负责,父节点调用子节点;代码具体处理逻辑由consume
/doConsume
方法负责,由子节点调用父节点。
同时也可以看出,WholeStageCodegenExec
执行过程是一个整体。整个物理算子树的执行过程被InputAdapter
分隔开。
本次先了解代码生成整体流程,具体的代码生成过程,待下次分享。
最后,祝大家中秋节快乐!!!
