




最初的实验变成了一系列关于FerretDB和CockroachDB的文章。由CockroachDB支持的FerretDB实现了许多未开发的机会;其中一些功能是具有二级索引、部分索引、约束、空间功能、JSONB运算符、多区域抽象以及正确性和一致性的计算列。今天,我们将讨论CockroachDB多区域功能,以及它们如何帮助MongoDB转换。
高级步骤
-
启动9节点多区域群集(CockroachDB专用)
-
启动FerretDB(Docker)
-
多区域
-
按表格列出的区域
-
全球的
-
追随者阅读
-
按世界其他地区划分的区域
-
-
注意事项
-
结论
逐步说明
启动9节点多区域群集(Cockroachdb专用)
我将使用上一篇文章中的相同CockroachDB专用集群。有关详细步骤,请参阅前一篇文章。您可以通过此链接获得为期30天的CockroachDB专用数据库试用版。
启动FerretDB(Docker)
我将使用上一篇文章中的相同合成文件,但是,由于我们将讨论多区域,我将对合成文件进行更改并突出显示它们。
多区域
我们的实验基于MongoDB网站上的sample_mflix数据集。我将使用上一篇文章中的用户集合作为教程的一部分,使用剧院集合作为另一部分。
如果尚未恢复集合,请执行以下操作:
mongorestore --archive=sampledata.archive --nsInclude=sample_mflix.users --numInsertionWorkersPerCollection=100 mongorestore --archive=sampledata.archive --nsInclude=sample_mflix.theaters --numInsertionWorkersPerCollection=100复制
用户集合中的每个文档都包含一个用户及其姓名、电子邮件和密码。
{ "_id": { "$oid": "59b99db4cfa9a34dcd7885b6" }, "name": "Ned Stark", "email": "sean_bean@gameofthron.es", "password": "$2b$12$UREFwsRUoyF0CRqGNK0LzO0HM/jLhgUCNNIJ9RJAqMUQ74crlJ1Vu" }复制
影院包含一个单独的影院及其字符串和GeoJSON格式的位置。
{ "_id": { "$oid": "59a47286cfa9a3a73e51e72c" }, "theaterId": { "$numberInt": "1000" }, "location": { "address": { "street1": "340 W Market", "city": "Bloomington", "state": "MN", "zipcode": "55425" }, "geo": { "type": "Point", "coordinates": [ { "$numberDouble": "-93.24565" }, { "$numberDouble": "44.85466" } ] } } }复制
今天我们将重点关注文本数据,稍后我们将重新访问GeoJSON。
使数据库多区域就绪包括四个步骤:
1.定义簇区域
2.定义数据库区域
3.定义生存目标
4.定义表位置
一旦CockroachDB部署到多个地区,第一步就要开始了。设置数据库区域只需运行以下命令即可:
ALTER DATABASE ferretdb PRIMARY REGION "aws-us-east-1"; ALTER DATABASE ferretdb ADD REGION "aws-us-east-2"; ALTER DATABASE ferretdb ADD REGION "aws-us-west-2";复制
数据库区域应与集群区域匹配。但是,单个集群中的集群区域可能比数据库区域多得多。这允许CockroachDB在工作负载需要时支持GDPR用例。
生存目标默认为区域生存能力。运行以上命令后,应该有一个具有以下行为的数据库ferretdb:
1.每个区域都有一个副本的数据库
2.抵御区域故障的能力
3.主区域的低延迟读写
查看数据库配置:
SHOW ZONE CONFIGURATION FOR DATABASE ferretdb;复制
DATABASE ferretdb | ALTER DATABASE ferretdb CONFIGURE ZONE USING | range_min_bytes = 134217728, | range_max_bytes = 536870912, | gc.ttlseconds = 90000, | num_replicas = 5, | num_voters = 3, | constraints = '{+region=aws-us-east-1: 1, +region=aws-us-east-2: 1, +region=aws-us-west-2: 1}', | voter_constraints = '[+region=aws-us-east-1]', | lease_preferences = '[[+region=aws-us-east-1]]'复制
我们拥有查看多区域抽象所需的一切。
按表列出的区域
sample_mflix.users_5e7cc513的架构表是:
CREATE TABLE sample_mflix.users_5e7cc513 ( _jsonb JSONB NULL, rowid INT8 NOT VISIBLE NOT NULL DEFAULT unique_rowid(), CONSTRAINT users_5e7cc513_pkey PRIMARY KEY (rowid ASC) ) LOCALITY REGIONAL BY TABLE IN PRIMARY REGION复制
请注意LOCALITY REGIONAL BY TABLE IN PRIMARY REGION子句。当应用程序需要从单个区域对整个表进行低延迟读写时,REGIONAL BY TABLE是很好的选择。它也是默认属性。
让我们看看对延迟的影响:
SELECT gateway_region(), "_jsonb"->'email' AS email_addr FROM sample_mflix.users_5e7cc513 LIMIT 1;复制
gateway_region | email_addr -----------------+----------------------------- aws-us-east-1 | "sean_bean@gameofthron.es" Time: 20ms total (execution 1ms / network 19ms)复制
这是可以接受的,如果我们从不同的地区访问,会产生什么影响?
美国西部
gateway_region | email_addr -----------------+----------------------------- aws-us-west-2 | "sean_bean@gameofthron.es" Time: 144ms total (execution 66ms / network 79ms)复制
这不是最优的,这是下一个功能可以帮助的地方:
全球的
我们的用户表有185条记录。它将主要用于访问用户记录。由于此表很少更新,因此它是GLOBAL位置的理想候选。
全局表具有以下特征:
1.个区域的快速强一致读取
2.每个区域写入速度较慢
当应用程序有一个“主要读取”的参考数据表,该表很少更新,并且需要对所有区域可用时,请使用全局表。
我们将使用以下语法更改用户表的表位置
ALTER TABLE sample_mflix.users_5e7cc513 SET locality GLOBAL;复制
我们在以后可能会出现的任何其他集合上都没有外键关系。在全局表上引用外键关系可以加快查找查询的速度。
更改位置后,我们可以再次执行查询:
SELECT gateway_region(), "_jsonb"->'email' AS email_addr FROM sample_mflix.users_5e7cc513 LIMIT 1;复制
美国东部
gateway_region | email_addr ----------------+----------------------------- aws-us-east-1 | "sean_bean@gameofthron.es" Time: 20ms total (execution 1ms / network 19ms)复制
延迟是可以接受的,因为我离AWS-us-east-1区域很近。
美国西部
gateway_region | email_addr -----------------+----------------------------- aws-us-west-2 | "sean_bean@gameofthron.es" Time: 80ms total (execution 1ms / network 79ms)复制
网络延迟可以解释为从客户端到网关的往返时间。然而,执行时间显著减少。
数据库集合。latencyStats()方法未在FerretDB中实现,我无法演示使用mongosh客户端的性能优势:
sample_mflix> db.users.latencyStats() MongoServerError: `aggregate` command is not implemented yet复制
追随者阅读
CockroachDB中的以下功能允许在更早的时间戳查询数据,类似于时间旅行查询。跨区域延迟的代价是稍微陈旧的数据。Follower从本地副本读取,而不是从仲裁领导者读取,仲裁领导者可以物理地位于另一个区域。可以通过将AS OF SYSTEM TIME语法附加到SELECT查询的末尾来访问它。
SELECT gateway_region() AS region, "_jsonb"->'email' AS email_addr FROM sample_mflix.users_5e7cc513 AS OF SYSTEM TIME follower_read_timestamp() LIMIT 1;复制
美国东部
region | email_addr ----------------+----------------------------- aws-us-east-1 | "sean_bean@gameofthron.es" Time: 20ms total (execution 1ms / network 19ms)复制
美国西部
region | email_addr ----------------+----------------------------- aws-us-west-2 | "sean_bean@gameofthron.es" Time: 71ms total (execution 1ms / network 70ms)复制
再加上跨所有区域的可预测查询延迟,无需更改模式,与GLOBAL表相比,对写入没有影响。但也有缺点。在GLOBAL表提供强一致性读取的情况下,跟随器读取提供有界陈旧性读取。CockroachDB以串行隔离方式运行,但AOST类似于读提交隔离。追随者读取在CockroachDB中有许多应用程序,例如备份和恢复,因为它们不会影响前台流量,从而将错误和超时重试次数降至最低。函数follower_read_timestamp()不是唯一可以传递给AS OF SYSTEM TIME的时间间隔。它将接受从现在到gc之间的任何时间间隔。ttl窗口,默认为25小时。
SELECT gateway_region() AS region, "_jsonb"->'email' AS email_addr FROM sample_mflix.users_5e7cc513 AS OF SYSTEM TIME '-10m' LIMIT 1;复制
查询将返回10分钟前的值。
区域(按行)
REGIONAL BY ROW表格具有以下特点:
1.表经过优化,可从单个区域快速访问
2.区域是在行级别指定的
当应用程序需要在行级别进行低延迟读写时,请使用区域逐行表,其中单行主要是从单个区域访问的。例如,全局应用程序中的用户表可能需要将某些用户的数据保留在特定区域中,以获得更好的性能。
我们可以继续使用用户集合,但考虑到影院集合有与其相关的位置,我们将重点关注这一点。例如,我们想更新或返回附近剧院的信息。
SELECT DISTINCT("_jsonb"->'location'->'address'->>'state') FROM sample_mflix.theaters_cf846063 ORDER BY "_jsonb"->'location'->'address'->>'state';复制
AK AL AR AZ CA CO CT DC DE FL GA (52 rows)复制
我们将按州将数据集划分为三个AWS区域。我按字母顺序对状态进行排序,然后盲目地将它们放入三个桶中,每个桶对应一个区域。
ALTER TABLE sample_mflix.theaters_cf846063 ADD COLUMN region crdb_internal_region NOT NULL AS ( CASE WHEN ("_jsonb"->'location'->'address'->>'state') IN ('AK','AL','AR','AZ','CA','CO','CT','DC','DE','FL','GA','HI','IA','ID','IL','IN','KS','KY','LA') THEN 'aws-us-west-2' WHEN ("_jsonb"->'location'->'address'->>'state') IN ('MA','MD','ME','MI','MN','MO','MS','MT','NC','ND','NE','NH','NJ','NM','NV','NY') THEN 'aws-us-east-1' WHEN ("_jsonb"->'location'->'address'->>'state') IN ('OH','OK','OR','PA','PR','RI','SC','SD','TN','TX','UT','VA','VT','WA','WI','WV','WY') THEN 'aws-us-east-2' END ) STORED;复制
如果出现以下错误
ERROR: null value in column "region" violates not-null constraint SQLSTATE: 23502复制
这意味着表中有一个状态字段的行没有反映在分区逻辑中。
我们可以再次检查模式
CREATE TABLE sample_mflix.theaters_cf846063 ( _jsonb JSONB NULL, rowid INT8 NOT VISIBLE NOT NULL DEFAULT unique_rowid(), region public.crdb_internal_region NOT NULL AS (CASE WHEN (((_jsonb->'location':::STRING)->'address':::STRING)->>'state':::STRING) IN ('AK':::STRING, 'AL':::STRING, 'AR':::STRING, 'AZ':::STRING, 'CA':::STRING, 'CO':::STRING, 'CT':::STRING, 'DC':::STRING, 'DE':::STRING, 'FL':::STRING, 'GA':::STRING, 'HI':::STRING, 'IA':::STRING, 'ID':::STRING, 'IL':::STRING, 'IN':::STRING, 'KS':::STRING, 'KY':::STRING, 'LA':::STRING) THEN 'aws-us-west-2':::public.crdb_internal_region WHEN (((_jsonb->'location':::STRING)->'address':::STRING)->>'state':::STRING) IN ('MA':::STRING, 'MD':::STRING, 'ME':::STRING, 'MI':::STRING, 'MN':::STRING, 'MO':::STRING, 'MS':::STRING, 'MT':::STRING, 'NC':::STRING, 'ND':::STRING, 'NE':::STRING, 'NH':::STRING, 'NJ':::STRING, 'NM':::STRING, 'NV':::STRING, 'NY':::STRING) THEN 'aws-us-east-1':::public.crdb_internal_region WHEN (((_jsonb->'location':::STRING)->'address':::STRING)->>'state':::STRING) IN ('OH':::STRING, 'OK':::STRING, 'OR':::STRING, 'PA':::STRING, 'PR':::STRING, 'RI':::STRING, 'SC':::STRING, 'SD':::STRING, 'TN':::STRING, 'TX':::STRING, 'UT':::STRING, 'VA':::STRING, 'VT':::STRING, 'WA':::STRING, 'WI':::STRING, 'WV':::STRING, 'WY':::STRING) THEN 'aws-us-east-2':::public.crdb_internal_region END) STORED, CONSTRAINT theaters_cf846063_pkey PRIMARY KEY (rowid ASC) ) LOCALITY REGIONAL BY TABLE IN PRIMARY REGION复制
查看数据:
SELECT DISTINCT("_jsonb"->'location'->'address'->>'state') AS state, region FROM sample_mflix复制
state | region --------+---------------- MI | aws-us-east-1 MN | aws-us-east-1 MD | aws-us-east-1 CA | aws-us-west-2 AL | aws-us-west-2 AZ | aws-us-west-2 WI | aws-us-east-2 IN | aws-us-west-2 NV | aws-us-east-1复制
我们还有一个步骤要完成,我们尚未定义RBR位置:
ALTER TABLE sample_mflix.theaters_cf846063 SET LOCALITY REGIONAL BY ROW AS "region";复制
让我们在aws-us-east-1中从NJ获取记录
SELECT gateway_region(), "_jsonb" FROM sample_mflix.theaters_cf846063 WHERE "_jsonb"->'location'->'address' @> '{"state":"NJ"}' LIMIT 1;复制
美国东部
gateway_region | _jsonb aws-us-east-1 | {"$k": ["_id", "theaterId", "location"], "_id": {"$o": "59a47287cfa9a3a73e51ed21"}, "location": {"$k": ["address", "geo"], "address": {"$k": ["street1", "city", "state", "zipcode"], "city": "Paramus", "state": "NJ", "street1": "1 Garden State Plaza", "zipcode": "07652"}, "geo": {"$k": ["type", "coordinates"], "coordinates": [{"$f": -74.074898}, {"$f": 40.915257}], "type": "Point"}}, "theaterId": 887} Time: 26ms total (execution 6ms / network 20ms)复制
让我们从美国西部地区查询加利福尼亚剧院
aws-us-west-2 | {"$k": ["_id", "theaterId", "location"], "_id": {"$o": "59a47287cfa9a3a73e51ed27"}, "location": {"$k": ["address", "geo"], "address": {"$k": ["street1", "city", "state", "zipcode"], "city": "Gilroy", "state": "CA", "street1": "7011 Camino Arroyo", "zipcode": "95020"}, "geo": {"$k": ["type", "coordinates"], "coordinates": [{"$f": -121.55201}, {"$f": 37.006283}], "type": "Point"}}, "theaterId": 884} Time: 554ms total (execution 476ms / network 78ms)复制
让我们看看执行计划
info ---------------------------------------------------------------------------------------------------- distribution: local vectorized: true • render │ estimated row count: 1 │ └── • limit │ estimated row count: 1 │ count: 1 │ └── • filter │ estimated row count: 174 │ filter: ((_jsonb->'location')->'address') @> '{"state": "NY"}' │ └── • scan estimated row count: 9 - 1,564 (100% of the table; stats collected 41 minutes ago) table: theaters_cf846063@theaters_cf846063_pkey spans: [/'aws-us-east-1' - /'aws-us-east-1'] [/'aws-us-east-2' - /'aws-us-west复制
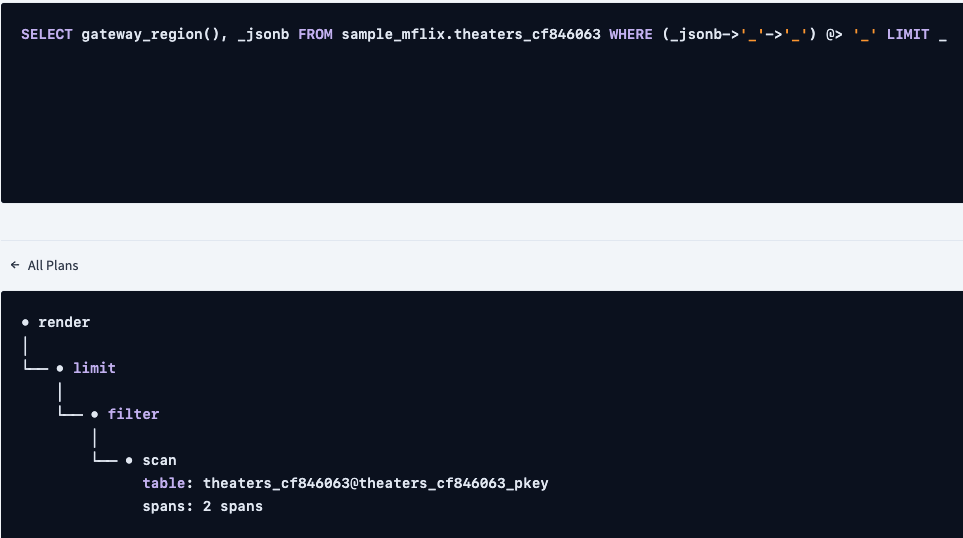
我们看到一个扫描表上有大量行。CockroachDB能够使用反向索引索引JSONB列,让我们添加一个索引,看看是否有任何变化
CREATE INDEX ON sample_mflix.theaters_cf846063 USING GIN(_jsonb);复制
在索引之后,计划如下:
info ---------------------------------------------------------------------------------------------------- distribution: local vectorized: true • render │ estimated row count: 1 │ └── • index join │ estimated row count: 1 │ table: theaters_cf846063@theaters_cf846063_pkey │ └── • union all │ estimated row count: 1 │ limit: 1 │ ├── • scan │ estimated row count: 1 (0.06% of the table; stats collected 45 minutes ago) │ table: theaters_cf846063@theaters_cf846063__jsonb_idx │ spans: [/'aws-us-east-1' - /'aws-us-east-1'] │ limit: 1 │ └── • scan estimated row count: 1 (0.06% of the table; stats collected 45 minutes ago) table: theaters_cf846063@theaters_cf846063__jsonb_idx spans: [/'aws-us-east-2' - /'aws-us-east-2'] [/'aws-us-west-2' - /'aws-us-west-2'] limit: 1复制
不幸的是,位置优化搜索中存在一个bug,它会影响具有反向索引的查询。修复程序已经合并,但没有加入我在集群中使用的版本。延迟将得到改善,但在补丁发布之前,我无法证明这一点。然而,我们还有另一个选择。
在继续下一步之前,我将删除上一步中的反向索引。
DROP INDEX sample_mflix.theaters_cf846063@theaters_cf846063__jsonb_idx;复制
如果我们运行以下查询,查询计划会是什么样子
db.theaters.find({"location.address.state": { $in: ['AZ']}})复制
令人惊讶的是,它仍然显示了全表扫描

查询在子句中使用,我们需要在SQL中使用等效查询。我们还需要在state元素上创建一个计算列,并避免使用JSONB运算符,如“_JSONB”->“location”->“address”,这样就不需要依赖反向索引。
ALTER TABLE sample_mflix.theaters_cf846063 ADD COLUMN state STRING NOT NULL AS (_jsonb->'location'->'address'->>'state') VIRTUAL;复制
选择查询语法可以简化:
SELECT gateway_region(), state FROM sample_mflix.theaters_cf846063 WHERE state IN ('NY') LIMIT 1;复制
美国东部
gateway_region | state -----------------+-------- aws-us-east-1 | NY Time: 254ms total (execution 234ms / network 20ms)复制
美国西部
gateway_region | state -----------------+-------- aws-us-west-2 | CA Time: 557ms total (execution 478ms / network 79ms)复制
这大大降低了性能,幸运的是,我们可以通过在计算列上添加常规索引来提高性能
CREATE INDEX ON sample_mflix.theaters_cf846063 (state);复制
美国东部
gateway_region | state -----------------+-------- aws-us-east-1 | NY Time: 29ms total (execution 4ms / network 20ms)复制
美国西部
gateway_region | state -----------------+-------- aws-us-west-2 | CA Time: 71ms total (execution 2ms / network 69ms)复制
解释的计划看起来更好
distribution: local vectorized: true • render │ estimated row count: 1 │ └── • index join │ estimated row count: 1 │ table: theaters_cf846063@theaters_cf846063_pkey │ └── • union all │ estimated row count: 1 │ limit: 1 │ ├── • scan │ estimated row count: 1 (0.06% of the table; stats collected 36 seconds ago) │ table: theaters_cf846063@theaters_cf846063_state_idx │ spans: [/'aws-us-east-1'/'NY' - /'aws-us-east-1'/'NY'] │ limit: 1 │ └── • scan estimated row count: 1 (0.06% of the table; stats collected 36 seconds ago) table: theaters_cf846063@theaters_cf846063_state_idx spans: [/'aws-us-east-2'/'NY' - /'aws-us-east-2'/'NY'] [/'aws-us-west-2'/'NY' - /'aws-us-west-2'/'NY'] limit: 1复制
我们正在计算列上使用新索引,但仍有一个索引联接需要删除。我们需要首先将计算列从VIRTUAL更改为STORED。
SET sql_safe_updates = false; ALTER TABLE sample_mflix.theaters_cf846063 DROP COLUMN state; SET sql_safe_updates = true;复制
此命令还将删除关联的索引,让我们将列添加回STORED
ALTER TABLE sample_mflix.theaters_cf846063 ADD COLUMN state STRING NOT NULL AS (_jsonb->'location'->'address'->>'state') STORED;复制
让我们把索引加回来
CREATE INDEX ON sample_mflix.theaters_cf846063 (state);复制
解释的计划不再具有索引联接
distribution: local vectorized: true • render │ estimated row count: 1 │ └── • union all │ estimated row count: 1 │ limit: 1 │ ├── • scan │ estimated row count: 1 (0.06% of the table; stats collected 2 minutes ago) │ table: theaters_cf846063@theaters_cf846063_state_idx │ spans: [/'aws-us-east-1'/'NY' - /'aws-us-east-1'/'NY'] │ limit: 1 │ └── • scan estimated row count: 1 (0.06% of the table; stats collected 2 minutes ago) table: theaters_cf846063@theaters_cf846063_state_idx spans: [/'aws-us-east-2'/'NY' - /'aws-us-east-2'/'NY'] [/'aws-us-west-2'/'NY' - /'aws-us-west-2'/'NY'] limit: 1复制
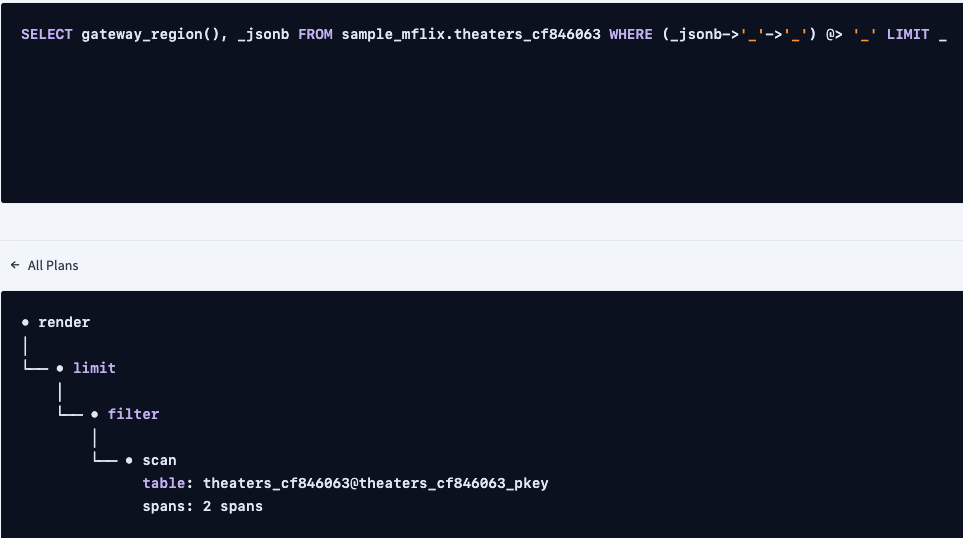
我们看到一个扫描表上有大量行。CockroachDB能够使用反向索引索引JSONB列,让我们添加一个索引,看看是否有任何变化
CREATE INDEX ON sample_mflix.theaters_cf846063 USING GIN(_jsonb);复制
在索引之后,计划如下:
info ---------------------------------------------------------------------------------------------------- distribution: local vectorized: true • render │ estimated row count: 1 │ └── • index join │ estimated row count: 1 │ table: theaters_cf846063@theaters_cf846063_pkey │ └── • union all │ estimated row count: 1 │ limit: 1 │ ├── • scan │ estimated row count: 1 (0.06% of the table; stats collected 45 minutes ago) │ table: theaters_cf846063@theaters_cf846063__jsonb_idx │ spans: [/'aws-us-east-1' - /'aws-us-east-1'] │ limit: 1 │ └── • scan estimated row count: 1 (0.06% of the table; stats collected 45 minutes ago) table: theaters_cf846063@theaters_cf846063__jsonb_idx spans: [/'aws-us-east-2' - /'aws-us-east-2'] [/'aws-us-west-2' - /'aws-us-west-2'] limit: 1复制
不幸的是,位置优化搜索中存在一个bug,它会影响具有反向索引的查询。修复程序已经合并,但没有加入我在集群中使用的版本。延迟将得到改善,但在补丁发布之前,我无法证明这一点。然而,我们还有另一个选择。
在继续下一步之前,我将删除上一步中的反向索引。
DROP INDEX sample_mflix.theaters_cf846063@theaters_cf846063__jsonb_idx;复制
如果我们运行以下查询,查询计划会是什么样子
db.theaters.find({"location.address.state": { $in: ['AZ']}})复制
令人惊讶的是,它仍然显示了全表扫描

查询在子句中使用,我们需要在SQL中使用等效查询。我们还需要在state元素上创建一个计算列,并避免使用JSONB运算符,如“_JSONB”->“location”->“address”,这样就不需要依赖反向索引。
ALTER TABLE sample_mflix.theaters_cf846063 ADD COLUMN state STRING NOT NULL AS (_jsonb->'location'->'address'->>'state') VIRTUAL;复制
选择查询语法可以简化:
SELECT gateway_region(), state FROM sample_mflix.theaters_cf846063 WHERE state IN ('NY') LIMIT 1;复制
美国东部
gateway_region | state -----------------+-------- aws-us-east-1 | NY Time: 254ms total (execution 234ms / network 20ms)复制
美国西部
gateway_region | state -----------------+-------- aws-us-west-2 | CA Time: 557ms total (execution 478ms / network 79ms)复制
这大大降低了性能,幸运的是,我们可以通过在计算列上添加常规索引来提高性能这大大降低了性能,幸运的是,我们可以通过在计算列上添加常规索引来提高性能
CREATE INDEX ON sample_mflix.theaters_cf846063 (state);复制
美国东部
gateway_region | state -----------------+-------- aws-us-east-1 | NY Time: 29ms total (execution 4ms / network 20ms)复制
美国西部
gateway_region | state -----------------+-------- aws-us-west-2 | CA Time: 71ms total (execution 2ms / network 69ms)复制
explained的计划看起来更好
distribution: local vectorized: true • render │ estimated row count: 1 │ └── • index join │ estimated row count: 1 │ table: theaters_cf846063@theaters_cf846063_pkey │ └── • union all │ estimated row count: 1 │ limit: 1 │ ├── • scan │ estimated row count: 1 (0.06% of the table; stats collected 36 seconds ago) │ table: theaters_cf846063@theaters_cf846063_state_idx │ spans: [/'aws-us-east-1'/'NY' - /'aws-us-east-1'/'NY'] │ limit: 1 │ └── • scan estimated row count: 1 (0.06% of the table; stats collected 36 seconds ago) table: theaters_cf846063@theaters_cf846063_state_idx spans: [/'aws-us-east-2'/'NY' - /'aws-us-east-2'/'NY'] [/'aws-us-west-2'/'NY' - /'aws-us-west-2'/'NY'] limit: 1复制
我们正在计算列上使用新索引,但仍有一个索引联接需要删除。我们需要首先将计算列从VIRTUAL更改为STORED。
SET sql_safe_updates = false; ALTER TABLE sample_mflix.theaters_cf846063 DROP COLUMN state; SET sql_safe_updates = true;复制
此命令还将删除关联的索引,让我们将列添加回STORED
ALTER TABLE sample_mflix.theaters_cf846063 ADD COLUMN state STRING NOT NULL AS (_jsonb->'location'->'address'->>'state') STORED;复制
让我们把索引加回来
CREATE INDEX ON sample_mflix.theaters_cf846063 (state);复制
解释的计划不再具有索引联接
distribution: local vectorized: true • render │ estimated row count: 1 │ └── • union all │ estimated row count: 1 │ limit: 1 │ ├── • scan │ estimated row count: 1 (0.06% of the table; stats collected 2 minutes ago) │ table: theaters_cf846063@theaters_cf846063_state_idx │ spans: [/'aws-us-east-1'/'NY' - /'aws-us-east-1'/'NY'] │ limit: 1 │ └── • scan estimated row count: 1 (0.06% of the table; stats collected 2 minutes ago) table: theaters_cf846063@theaters_cf846063_state_idx spans: [/'aws-us-east-2'/'NY' - /'aws-us-east-2'/'NY'] [/'aws-us-west-2'/'NY' - /'aws-us-west-2'/'NY'] limit: 1复制
美国东部
gateway_region | state -----------------+-------- aws-us-east-1 | NY Time: 23ms total (execution 3ms / network 19ms)复制
美国西部
gateway_region | state -----------------+-------- aws-us-west-2 | CA Time: 71ms total (execution 2ms / network 69ms)复制
请注意,查询执行时间相当于东部地区的查询执行时间。远程用户无论身在何处,都可以从本地延迟中受益!
遗憾的是,当我运行以下命令时,FerretDB没有选择索引
db.theaters.find({"location.address.state": { $in: ['AZ']}})复制

我们将不得不等待FerretDB解决其未决问题的长尾问题。
我们可以再进行一次优化,以完全避免局部优化搜索。我们需要将计算列转换为常规列。
作为第一步,我们需要通过将表的位置更改为RBR以外的任何值来重置表。
ALTER TABLE sample_mflix.theaters_cf846063 SET LOCALITY REGIONAL BY TABLE;复制
SET sql_safe_updates = false; ALTER TABLE sample_mflix.theaters_cf846063 DROP COLUMN region; SET sql_safe_updates = true;复制
将计算列转换为标准列,否则,如果尝试对表进行分区,将得到以下错误
ERROR: computed column expression cannot reference computed columns SQLSTATE: 42P16复制
ALTER TABLE sample_mflix.theaters_cf846063 ALTER COLUMN state DROP STORED;复制
最后,通过一个常规列对表进行分区
ALTER TABLE sample_mflix.theaters_cf846063 ADD COLUMN region crdb_internal_region NOT NULL AS ( CASE WHEN state IN ('AK','AL','AR','AZ','CA','CO','CT','DC','DE','FL','GA','HI','IA','ID','IL','IN','KS','KY','LA') THEN 'aws-us-west-2' WHEN state IN ('MA','MD','ME','MI','MN','MO','MS','MT','NC','ND','NE','NH','NJ','NM','NV','NY') THEN 'aws-us-east-1' WHEN state IN ('OH','OK','OR','PA','PR','RI','SC','SD','TN','TX','UT','VA','VT','WA','WI','WV','WY') THEN 'aws-us-east-2' END ) STORED;复制
将表格更改为RBR
ALTER TABLE sample_mflix.theaters_cf846063 SET LOCALITY REGIONAL BY ROW AS "region";复制
美国东部
gateway_region | state -----------------+-------- aws-us-east-1 | NY Time: 22ms total (execution 3ms / network 20ms)复制
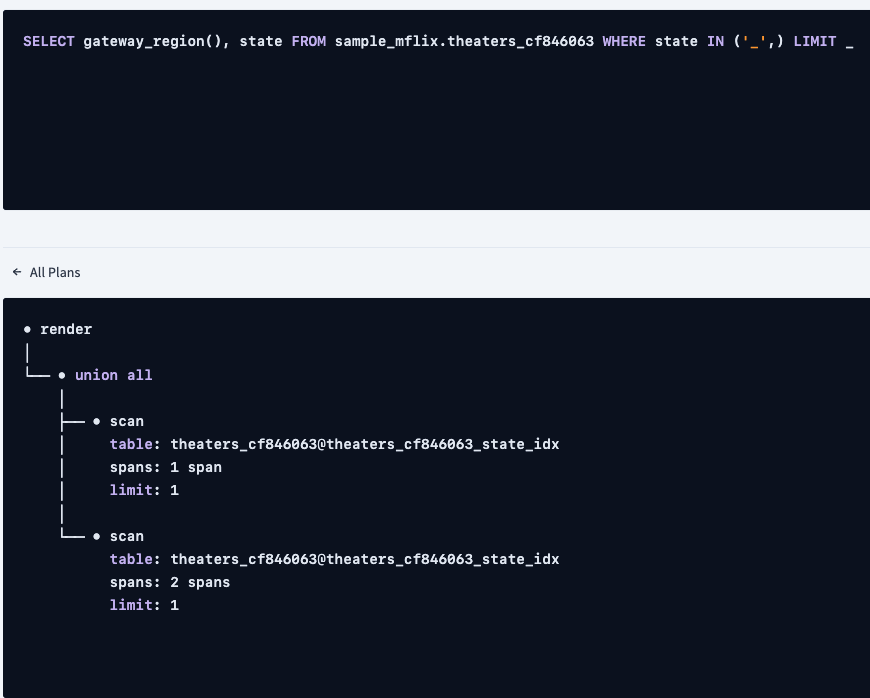
查询的explained计划现在看起来是这样的
distribution: local vectorized: true • render │ estimated row count: 1 │ └── • scan estimated row count: 1 (0.06% of the table; stats collected 3 minutes ago) table: theaters_cf846063@theaters_cf846063_state_idx spans: [/'aws-us-east-1'/'NY' - /'aws-us-east-1'/'NY'] limit: 1复制
我们不再需要利用基于位置的搜索,因为状态过滤器,即state='NY’指定要查找的分区。
美国西部
gateway_region | state -----------------+-------- aws-us-west-2 | CA Time: 70ms total (execution 2ms / network 69ms)复制
注意事项
REGIONAL BY ROW表格有很多潜力,我花了很多努力才达到最终目标,但我们确实涵盖了很多角落案例。总结一下我们的努力,我们的步骤是:
1.在JSONB负载中的state元素上创建计算列
2.将计算列转换为常规列
3.为状态列编制索引
4.按状态列对表进行分区
5.创建RBR表
在撰写本文之前,我不知道能够用一个命令将计算列转换为常规列。
结论
这就结束了我们在CockroachDB中的多区域抽象之旅。还有一些我们在本文中没有讨论的其他功能,但我希望能够演示远程区域的用户如何获得与本地数据库用户相同的用户体验。
原文标题:CockroachDB Multiregion Abstractions for MongoDB Developers With Ferretdb
原文作者:Artem Ervits
原文链接:https://dzone.com/articles/cockroachdb-multiregion-abstractions-for-mongodb-d



