




任何部署了 Postgres 或 EPAS 服务的人最终都必须做出艰难的决定:如何设置shared_buffers?更传统的观点建议使用 1/4 的 RAM,如有必要,可能在未来进行调整。这是PGConfig和PGTune实用程序在为多个配置设置提出建议时所遵循的确切建议。
然而,这真的是我们在现代系统上想要的吗?装备精良的 Postgres 服务器使用 1TB 的 RAM 并不少见,我们是否希望将 256GB 专用于 Postgres 共享缓冲区?这还是个好主意吗?或者这是曾经的好主意吗?
为了回答这些问题(以及其他问题),我们在 Postgres 14 上运行了一系列基准测试,将共享缓冲区从默认值一直更改为服务器 RAM 的一半。
进入过去式
译者注:这里应该是指“利用硬盘驱动器进行共享缓存”
Dave Page最近分享了EDBs Ansible 基准框架,我们的一个内部团队正在使用它来构建一个自动调整 Postgres 的系统。该测试的一部分包括在具有不同参数值的不同描述的硬件上进行多次执行,以调整和训练所有顾问和集成 AI 层。
这总是意味着对一种在 SSD 价格下跌的时代迅速接近完全弃用的技术进行基准测试:硬盘驱动器。久负盛名的 HDD 无疑在塑造多种技术方面发挥了至关重要的作用,Postgres 也不例外。为此,EDB 有四台服务器可用于探索 HDD 性能。每个都包含一个 HP Proliant DL360 服务器,配备双Xeon E5-2630 v4 CPU(40 个线程)、64GB RAM 和四个 2TB 容量的 2.5 英寸 7200 RPM HDD,配置为 RAID-10。
硬件本身与 2016 年时代的系统是同时代的,尽管存储可能在四个微不足道的旋转生锈纺锤纺锤上略显不足。尽管如此,服务器本身还是装备精良的,而共享缓冲区旨在克服缓慢的存储问题。那么结果如何呢?
最熟悉的基准测试工具:pgbench
与 Postgres 相关的最熟悉的基准工具之一可能是pgbench。给定一个初始的引导规模,它将不断地将数据库提交给如下所示的简单事务的冲击:
BEGIN;
UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
UPDATE pgbench_tellers SET tbalance = tbalance + :delta WHERE tid = :tid;
UPDATE pgbench_branches SET bbalance = bbalance + :delta WHERE bid = :bid;
INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
END;
这会在极大的帐户表上进行一次UPDATE ,从同一张表中进行一次SELECT,在柜员表和余额表上进行两次半琐碎的更新,以及一次历史插入。尽管都是微小的动作,但我们还要注意,ID 无处不在,没有 JOIN,所以这可能与真实应用程序生成的活动类型不对应。它可能不是基准测试的最佳示例,但它一直存在,并且没有一个生产中的 Postgres 服务器逃脱了它的审查。
在这个特殊的案例中,我们初始化了一个规模为 7,500 的 pgbench 数据库,数据库大小约为 110GB。该规模还用 7.5 亿行填充pgbench_account表。这比我们可以在 RAM 中容纳的数据多,因此这应该足以对存储层施加压力。我们的基准套件还在测试之间刷新文件系统缓存和缓冲区,因此结果应该相当稳定。我们对 225 个客户端运行了所有测试一小时,以使系统 CPU 线程正确饱和。
这是我们发现的:
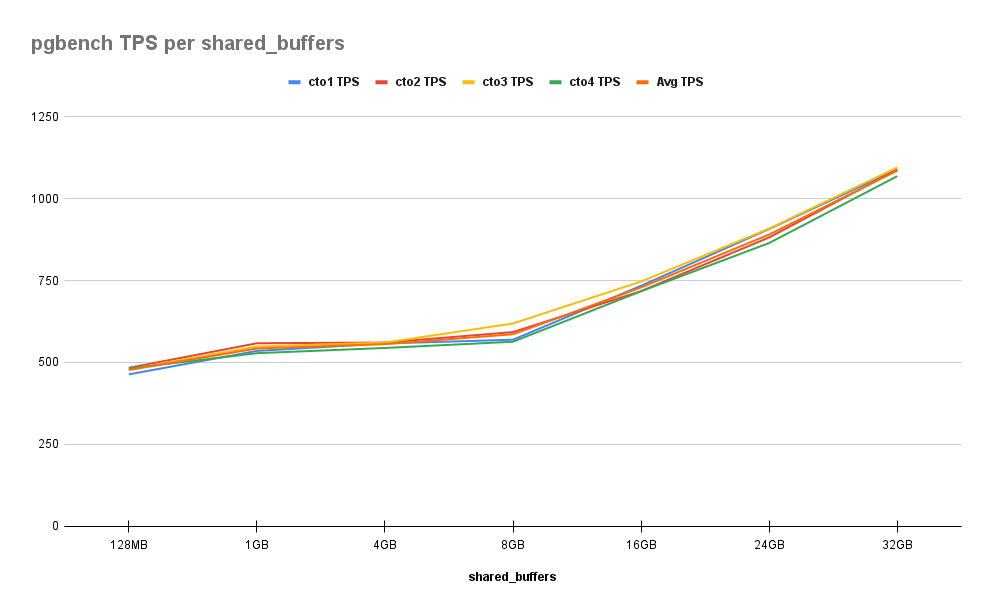
正如我们在这里所看到的,改进是相当一致的。从 128MB 增加到 1GB 给了我们 14% 的初始改进,但在 16GB 之前,图表仍然相对平坦,累积百分比为 53%。之后,每增加 8GB 步长,就会进一步增加 30%,到 32GB 时达到 128%。这是值得注意的,因为这是分配给这些服务器的 RAM 的一半。
我们应该指出,像 pgbench 这样的基准测试应该随着共享缓冲区中的数据量几乎线性增加。如果我们检查每个交易期间发布的语句,所有列出的值都是通过随机种子确定的。这意味着在基准测试期间可能会修改 10 亿行中的任何一行,因此性能将会提高,因为我们可以将更多这些行放入文件系统缓存或共享缓冲区的某种组合中。
大多数应用程序不适合这种访问模式,而是拥有更活跃的近期数据子集,或者按不同交易量的帐户分组。所以让我们尝试一些更具代表性的东西。
作为参考,这是我们在 cto1 服务器上达到 32GB 时在共享缓冲区中访问块的频率:
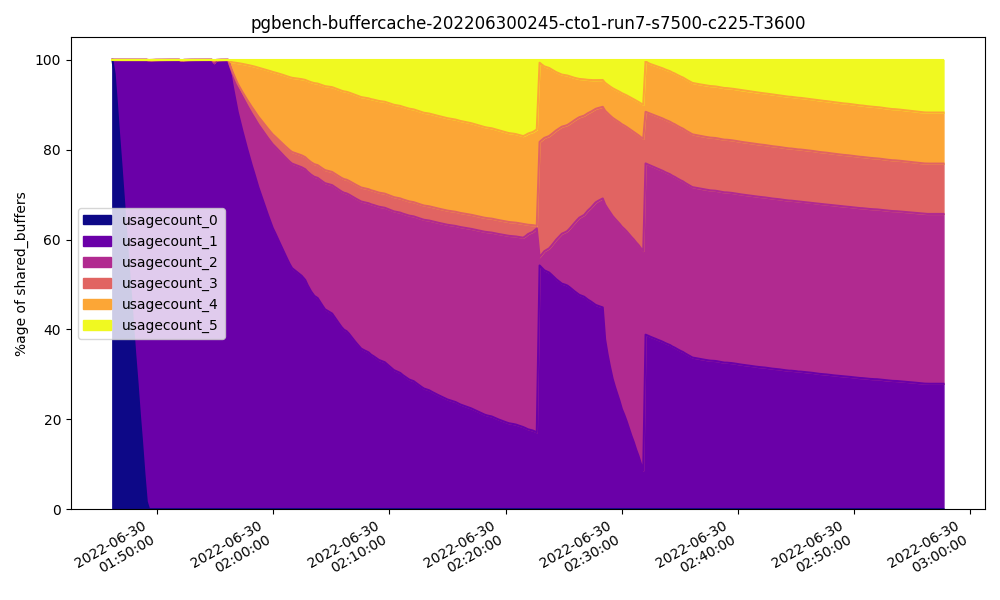
注意页面很少被访问五次或更多。
快速 HammerDB 攻击
最臭名昭著的数据库基准测试之一是TPC-C OLTP 测试。与 pgbench 不同,它尝试使用活动数据集模拟真实的业务应用程序,客户可以专注于特定的仓库。这为我们提供了一个更具代表性的观点,即当内存可用时应用程序可能实际执行的操作。
所有 TPC 实现在使用该名称之前都受到严格监管,即使遵循了所有规定的设计。幸运的是,HammerDB提供了一个他们指定为 TPROC -C的兼容实现,它模拟了所有必需的仓库、客户端、终端等。在我们的案例中,我们初始化了分布在 15 个模式用户上的 1125 个仓库,并使用 225 个客户端运行基准测试一小时。与 pgbench 数据库一样,数据库的总大小约为 110GB。
顺便说一句,这里的结果与我们在 pgbench 中找到的结果相似。首先是每分钟新订单 (NOPM) 结果:
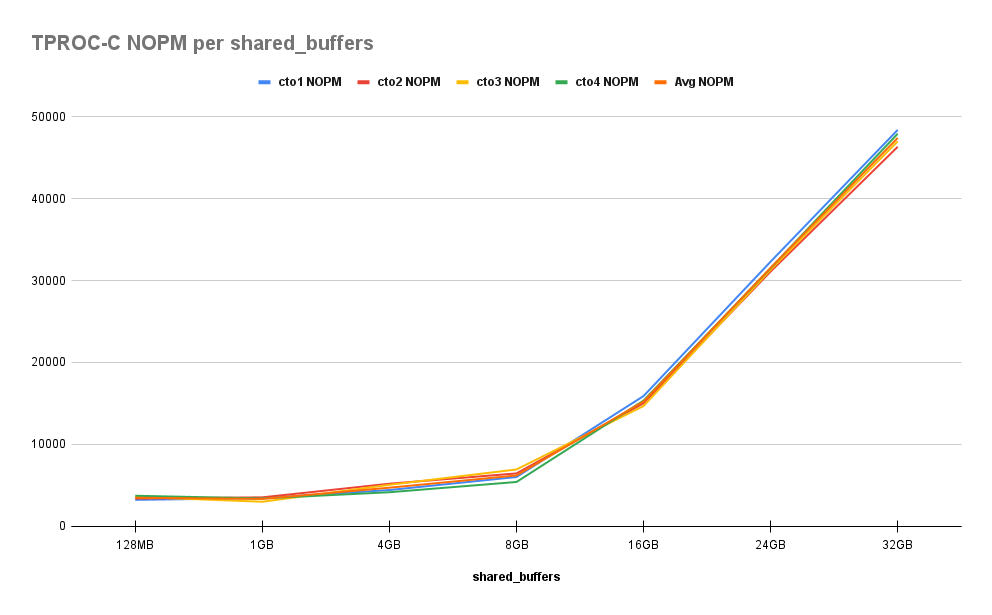
然后每分钟事务数 (TPM) 结果:
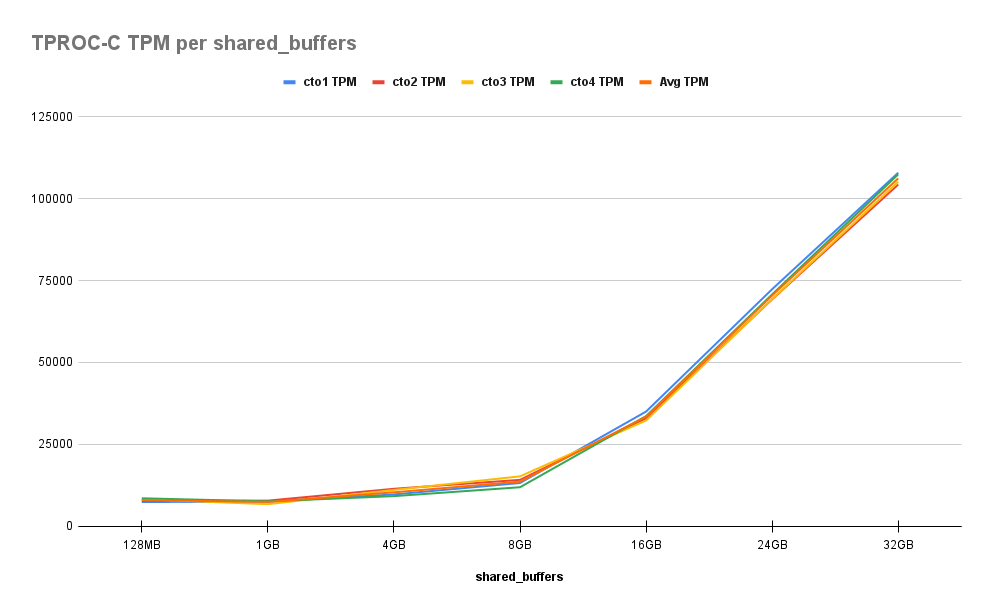
正如我们所看到的,这里的行为更加明显。即使有 225 个客户端,该基准也会在被操纵的数据中创建“热点”。当我们接近活动集的总大小时,我们将很快观察到性能提升。虽然当我们从 128MB 增加到 1GB 时几乎没有差异,但当我们达到一半系统 RAM 时,我们见证了 30%、70%、300%、800% 和最后 1200% 的基线改进。
这一次,32GB 的 Shared Buffer 使用模式与我们在 pgbench 中看到的完全不同:
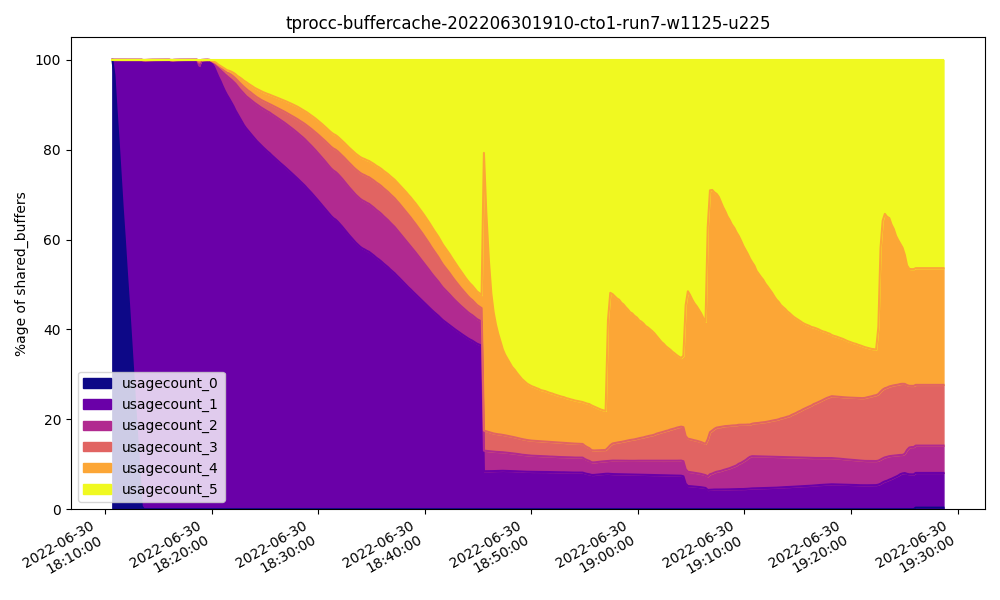
这一次很明显,大多数缓冲区都被频繁访问,这解释了近乎指数的性能曲线。如果我们将共享缓冲区的值替换为大致等于活动数据集的值,我们的曲线最终将达到平衡,进一步增加不会带来任何好处。
再一次谈到共享缓冲区时似乎“越多越好”,即使我们远远超出了使用 ¼ 系统 RAM 的常见建议。在这种情况下,我们不太清楚活动数据集的大小,但我们将通过增加共享缓冲区继续受益,直到达到那个点。
快速摆动HammerDB
另一个来自 TPC 组的常见数据库基准测试是TPC-H。与 pgbench 和 TPC-C 不同,它专注于具有大量连接和聚合的大型查询,更适合 OLAP 上下文。这让我们可以测试大而慢的读取繁重的查询,这些查询将导致完全不同类型的存储访问模式。
与 TPROC-C 一样,HammerDB 为 TPC-H 提供了自己的等价物,它 - 足够恰当地 - 调用TPROC-H。这次我们使用三个虚拟用户以 30 的比例因子进行初始化,并使用 15 个线程运行所有基准测试。调整 TPROC-H 数据库的大小比其他基准测试要复杂一些,因此我们最终为这些测试使用了 62GB 的数据库。尽管如此,结果并不完全符合我们的预期:
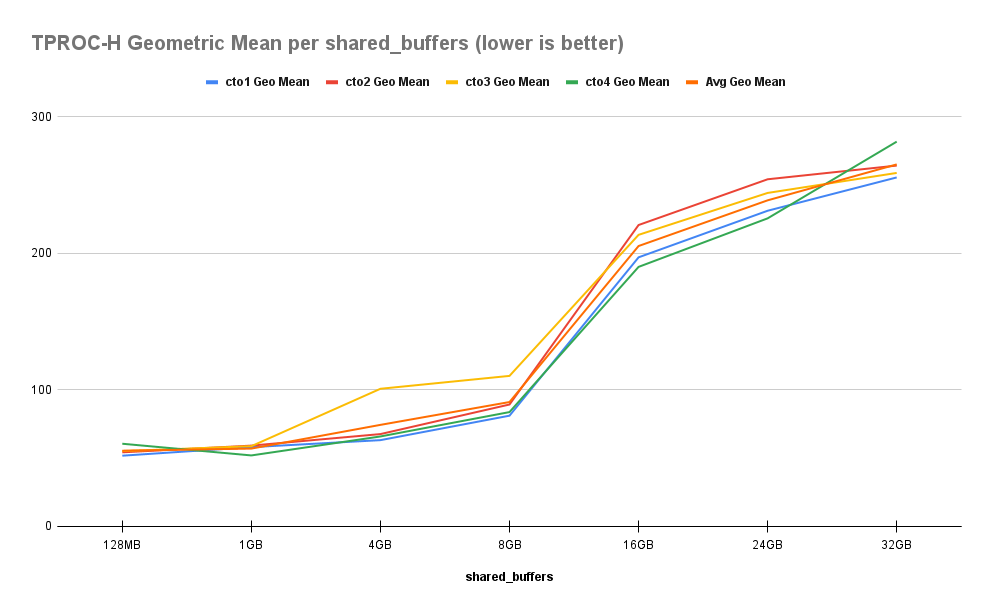
与测量纯吞吐量的其他测试不同,TPROC-H 实际上测量几何平均查询运行时间。随后,每次我们为这些 TPROC-H 基准测试增加共享缓冲区时,查询实际上都会变慢。尽管整个数据集理论上可以放入系统 RAM 中。当我们达到 32GB 的共享缓冲区时,查询速度比开始时慢 380%。
这怎么可能?让我们看一下 32GB 时的 Shared Buffer 使用模式:
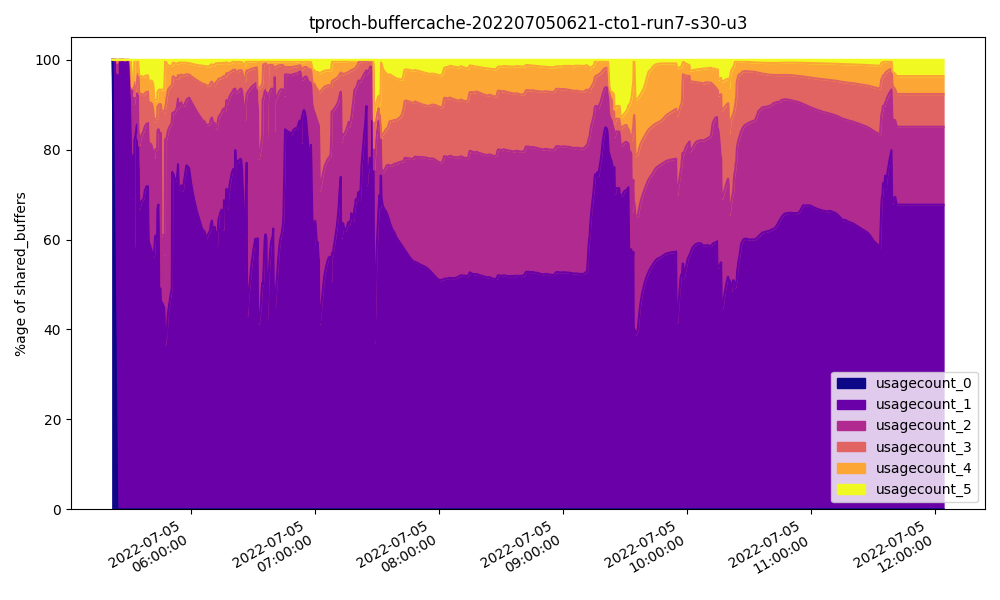
与其他两个基准测试不同,共享缓冲区中超过一半的页面只被访问过一次,即使是 32GB!此外,每个查询可能会利用大部分基础表,并且需要更多内存用于工作集。我们分配给共享缓冲区的内存越多,可用于这种临时使用的内存就越少。
另一种说法是:如果我们为共享缓冲区分配 32GB,则只剩下 32GB 用于文件系统缓存和用于排序、连接和聚合的空闲 RAM。由于大部分共享缓冲区只使用一次,其余页面由文件系统缓存提供。我们制作的共享缓冲区越大,文件系统缓存就越小。本质上共享缓冲区有益于经常使用的页面;否则,性能可能会下降。
事实证明,大型数据仓库在共享缓冲区分配较少的情况下工作得更好,因为大多数页面只会被使用一次。将这些页面保存在缓冲区中的工作显然比让操作系统处理它更大。
第 2 部分即将推出
这些基准似乎表明 OLTP 使用模式最适用于大小合理且完全适合共享缓冲区的活动数据集,而 OLAP 系统则相反。这是 Postgres 专家在为共享缓冲区提出真正建议时会说“好吧,这取决于”的原因之一。
事实证明,当我们将测试扩展到具有更大 RAM 和改进存储的更现代硬件时,情况变得更加复杂。基于 NVMe 的存储硬件确实是一种颠覆性技术,其方式超出您的预期。当我们最终汇总结果时,我们发现自己既惊讶又兴奋。
加入我们,参加本系列的第 2 部分,我们将展示更多可用的 RAM 和 NVMe 设备如何颠覆整个讨论!
原文标题:Harnessing Shared Buffers (and Reaping the Performance Benefits) - Part 1
原文作者:Shaun Thomas
原文地址:https://www.enterprisedb.com/blog/harnessing-shared-buffers-and-reaping-performance-benefits-part-1
