




今天我们将讨论如何提高MySQL中的查询速度。为此,我们将使用一个演示数据库,该数据库提供具有以下结构的相同MySQL主页:
实体关系图
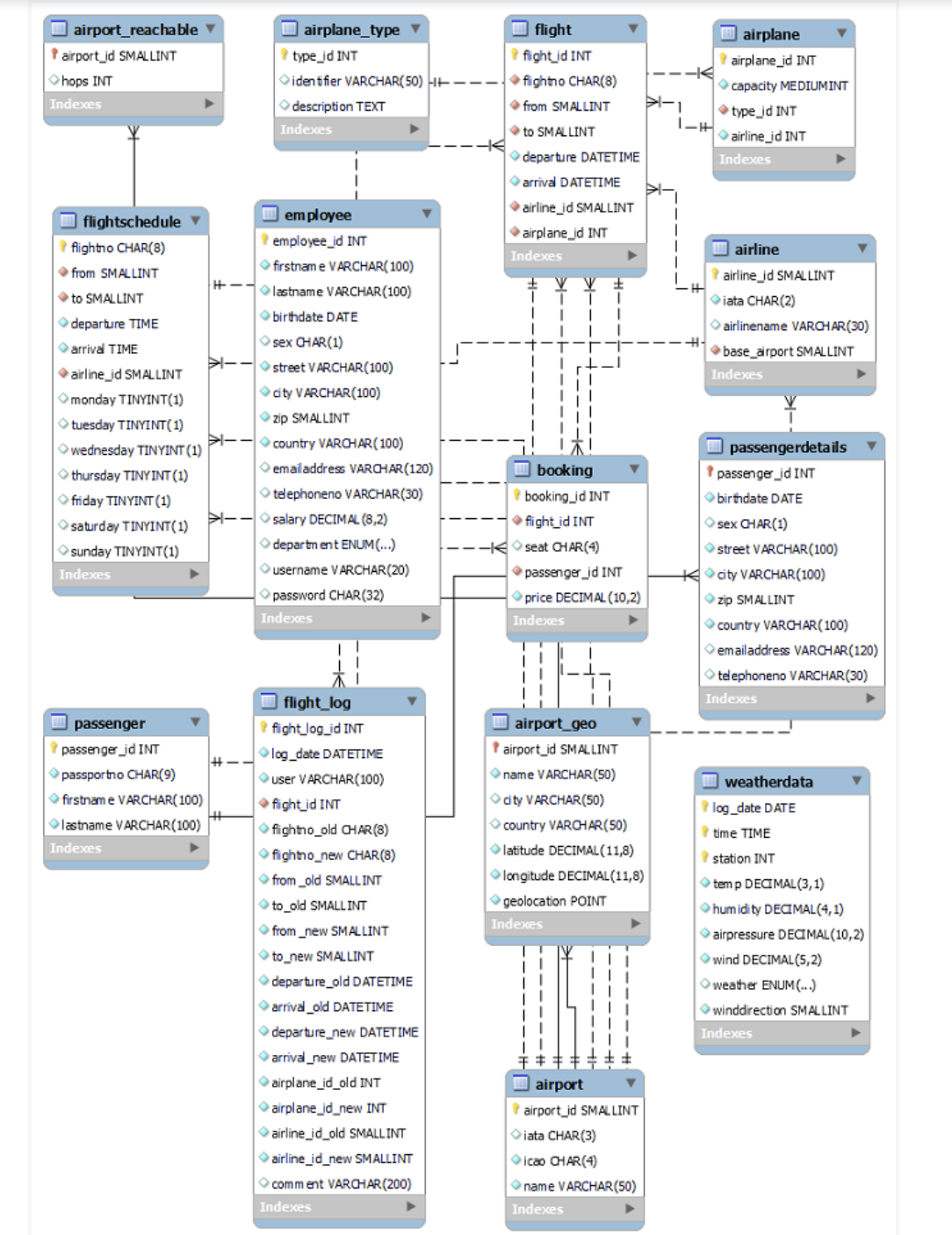
机场数据库是一个大型数据集,旨在与 MySQL 数据库系统一起使用。该数据库的大小约为 2GB,由 14 个表组成,总共包含 55,983,205 条记录。
airportdb表:
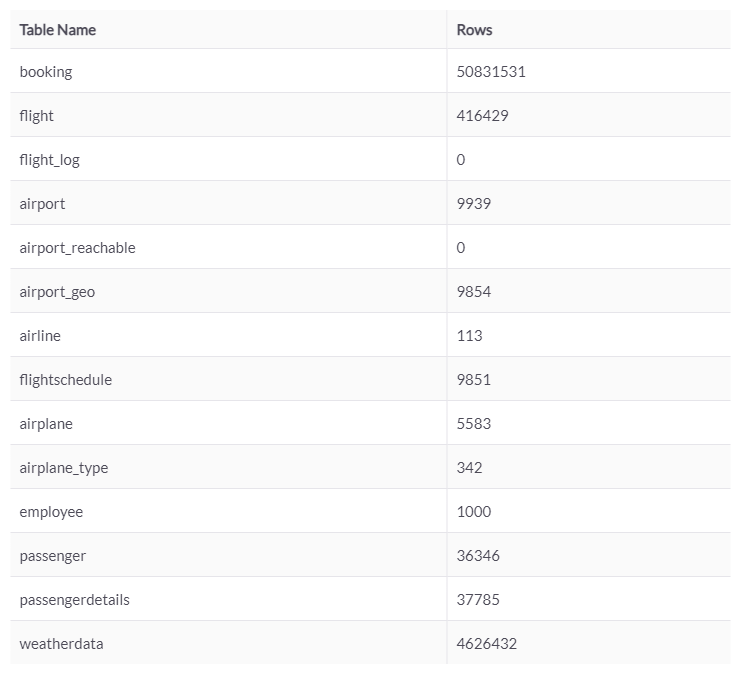
咨询诊断
必须对要优化的查询执行 EXPLAIN 命令。此命令可帮助我们验证数据库管理器如何处理查询,并阐明瓶颈所在,从而能够改进我们的查询。
作为使用 EXPLAIN 的结果,我们将关注的如下:
行的顺序。数据库查询表的顺序。
键列。指示用于访问该特定表的索引(如果有)
类型列。指示对表的访问类型。从最佳到最差的可能值是:
system
const
eq_ref
ref
Fulltext
ref_or_null
index_merge
unique_subquery
index_subquery
range
index
ALL
优化
避免完全扫描
EXPLAIN 命令可以告诉我们对表的访问是否键入 ALL。这告诉我们数据库管理器正在执行的过程是读取所述表的所有记录,而不进行任何类型的过滤。咨询必须根据需求和分析进行分析,如果可能的话,通过进行相关更改来验证如何改进咨询。
为此,您可以直接从基于其主键创建的表中使用索引,或者评估创建所述索引的可能性,以告诉处理程序根据创建的索引进行搜索。
SQL: EXPLAIN SELEC * FROM airline;.
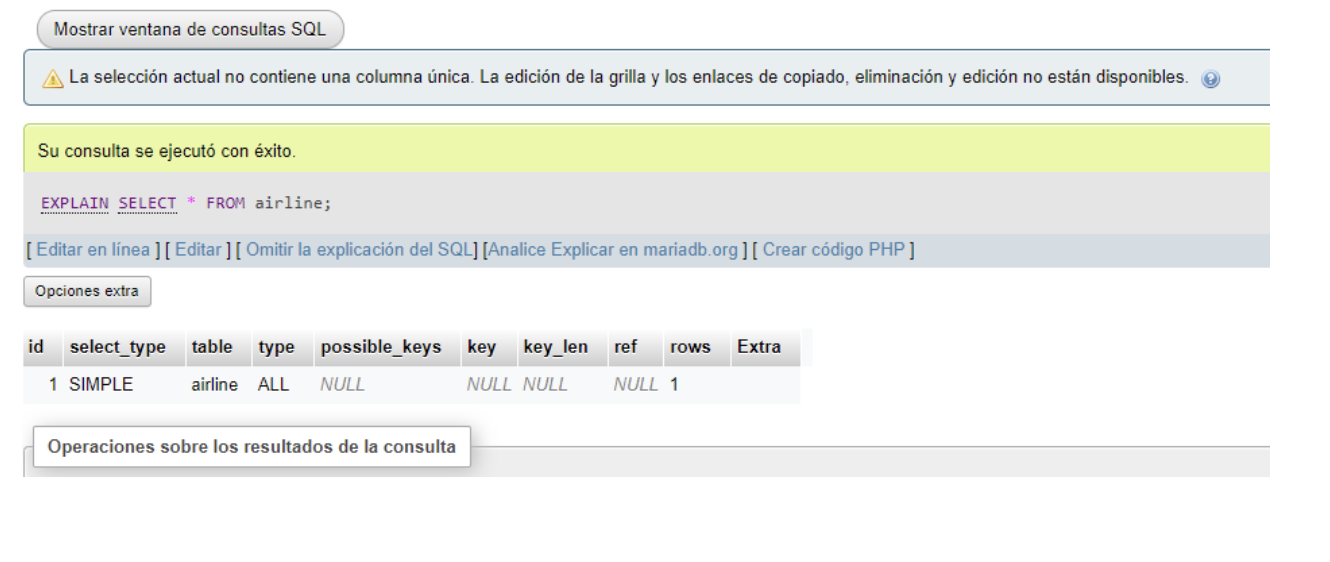
指标
索引是一种更快地执行查询的方法,因为我们向处理程序指示执行搜索的位置。如果我们想搜索“机场”的定义并搜索以“Aero”开头的单词,我们将做正确的事情。
但是,与使用索引和搜索以“port”结尾的单词的这种方式不同,我们将使数据库的处理程序完成对进行查询的表中所有记录的搜索。这将是“prefix_index%”这样的搜索的逻辑或最简单的解释,而另一个喜欢的“%suffix_index”则不是。
SQL:EXPLAIN SELECT * FROM airline where airlinename like ‘Hou%’;.
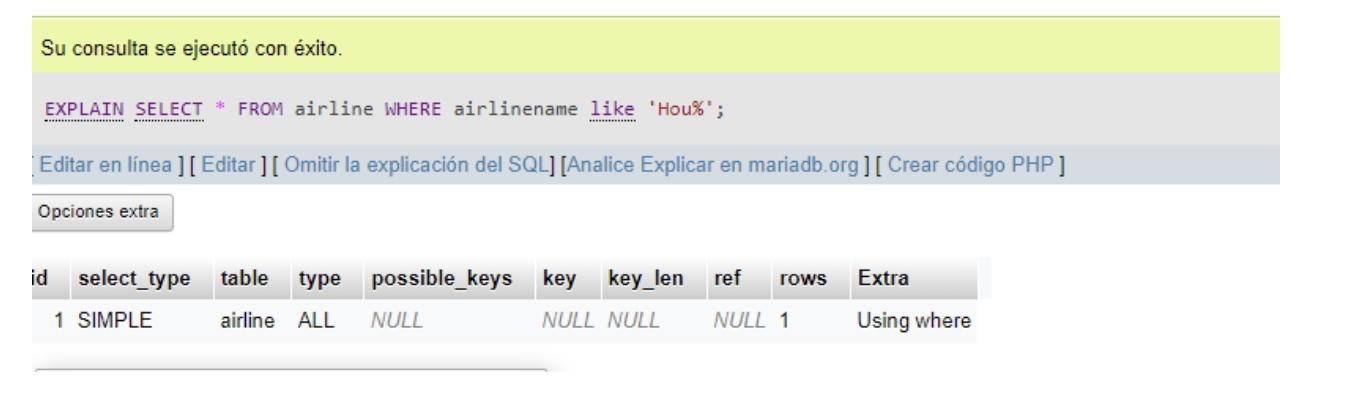
分组依据和排序依据
当我们想要优化搜索时,分组依据和排序依据的使用也非常重要,因为它允许我们执行以下操作:对查询将带给我们的记录进行分组将使查询返回分组数据,因此我们将拥有比基础必须处理的记录更少的记录。而且,“订购依据”使我们有可能对其进行订购,以便能够以流程所需的方式提供数据。
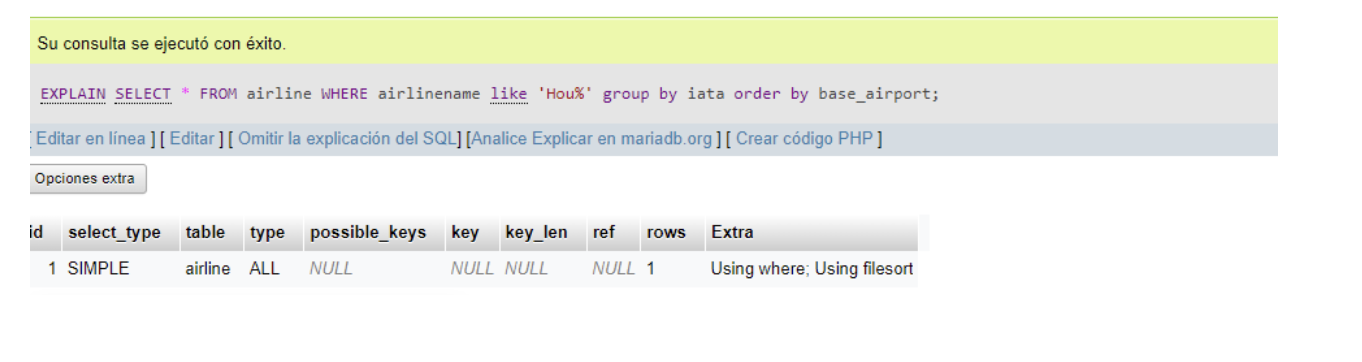
SQL:EXPLAIN SELECT * FROM airline where airlinename like ‘Hou%’;.
派生表和子查询
派生表是在父查询的 FROM 中执行的子查询,子查询是另一个 Select 语句中的 Select 语句。两者都以不同的方式通过数据库处理程序进行处理:派生表对数据库执行单个查询,并将信息存储在内存中的临时表中,并且对于父查询的每条记录访问该表一次。子查询与父查询一起执行,并针对父查询具有的每条记录进行检查。
SQL:EXPLAIN SELECT * FROM airline where airlinename like ‘Hou%’ group by iata order by base_airport;.
Summary
因此,我们有以下内容:要优化数据库中的查询,使用 EXPLAIN 命令非常重要,该命令支持我们验证数据库如何执行查询。为了防止我们的查询对此执行完全扫描,我们使用索引。此外,使用分组依据和排序依据非常重要,因为我们的查询带来了较少的处理记录,并且还考虑到使用派生表比子查询更优化 - 因为数据库处理程序处理派生表的方式比子查询更快。
SingleStoreDB数据库
SingleStoreDB 是一个实时的分布式 SQL 数据库,它将事务和分析统一到单个引擎中,以推动对大型数据集的低延迟访问,从而简化快速、现代企业应用程序的开发。
SingleStoreDB 专为开发人员和架构师而构建,可针对复杂查询提供 10-100 毫秒的性能,同时确保您的业务能够轻松扩展。
单存储数据库与MySQL线兼容,并提供熟悉的SQL语法,但基于现代底层技术,与MySQL相比,速度和规模无限高。这是单一商店成为信任空间中排名第一的关系数据库的众多原因之一。
原文标题:Speed Up Database Queries MySQL
原文作者:SingleStore
原文地址:https://www.singlestore.com/blog/speed-up-database-queries/
