




目录
TLDR:DuckDB现在可以直接查询存储在PostgreSQL中的查询,并在不复制数据的情况下加快复杂的分析查询速度。
PostgreSQL是世界上最先进的开源数据库(自称). 从它的作为一个数据库管理系统的开端,在过去的30年里,它已经发展成为我们数字环境中的一个基本工作。
PostgreSQL是为传统的事务用例设计的,即“OLTP”,在这种情况下,表中的行可以同时创建、更新和删除。但是这种设计决策使得PostgreSQL远远不适合分析用例,即“OLAP”,即读取大块表来创建存储数据。然而,在许多用例中,事务用例和分析用例都很重要,例如,当试图获得对事务数据的最新业务智能分析的时候。
已经有人尝试构建在两种工作负载下都表现良好的数据库管理系统,“HTAP”,但通常在OLTP和OLAP系统之间的许多设计决策是艰难的权衡。系统通常是分开的,事务应用程序数据存在于一个专门构建的系统中,比如PostgreSQL,而数据的副本存储在一个完全不同的DBMS中。使用专门构建的分析系统可以将分析查询的速度提高几个数量级。
不幸的是,为分析目的维护数据的副本可能会有问题:当处理新的事务时,副本将立即过时,需要进行复杂而非简单的同步设置。存储数据库的两个副本也需要两倍的存储空间。例如,像PostgreSQL这样的OLTP系统传统上使用基于行的数据表示,而OLAP系统倾向于采用分块列的数据表示。如果不维护数据的副本,就不能同时拥有这两种数据,这将带来很多问题。此外,所使用的OLAP系统与Postgres之间的SQL语法可能有很大差异。
但设计空间并不像看起来的那样非黑即白。例如,在像DuckDB这样的系统中,OLAP性能不仅仅来自于分块柱状磁盘数据表示。DuckDB的大部分性能来自它的向量化查询处理引擎,该引擎是为分析查询定制的。如果DuckDB能够以某种方式读取存储在PostgreSQL中的数据呢?
为了实现对Postgres数据库的快速和一致的分析读取,我们设计并实现了“Postgres扫描仪”。这个扫描器利用了Postgres客户端-服务器协议的二进制传输模式(详见实现部分),允许我们在DuckDB中直接有效地转换和使用数据。
除此之外,DuckDB的设计与传统的数据管理系统不同,因为DuckDB的查询处理引擎可以在几乎任意的数据源上运行,而不需要将数据复制到自己的存储格式。例如,DuckDB目前可以直接在parquet文件、CSV文件、SQLite文件、Pandas、RandJuliadata帧以及apache Arrow源上运行查询。这个新的扩展增加了直接从DuckDB查询PostgreSQL表的能力。
常规方法
Postgres Scanner DuckDB扩展的源代码可以在GitHub上获得,但是它可以通过DuckDB新的二进制扩展安装机制直接安装。在安装方面,只需要运行以下SQL查询一次:
INSTALL postgres_scanner;
复制任何时候你想使用扩展,你需要首先加载它:
LOAD postgres_scanner;
复制要使一个Postgres数据库可以被DuckDB访问,使用postgres_attachment命令:
CALL postgres_attach('dbname=myshinydb');
复制postgres_attachment接受一个必需的字符串参数,即thelibpqconnection字符串。例如,你可以传递’dbname=myshinydb’来选择一个不同的数据库名称。在最简单的情况下,参数只是“。函数中还有三个额外的命名形参:
-
source_schemapostgres中获取表的非标准模式名。默认ispublic。
-
overwrite是否应该覆盖目标模式中的现有视图,默认值为false。
-
filter_pushdownwhether filter从查询派生的DuckDB应该转发到Postgres,默认为false。关于这个参数控制的内容,请参见下面的讨论。
数据库中的表在DuckDB中注册为视图,您可以用
PRAGMA show_tables;
复制然后可以使用SQL正常查询这些视图。同样,没有数据被复制,这只是Postgres数据库中表的虚拟视图。
如果你不喜欢附加所有的表,而只是查询一个表,可以直接使用postgres_scanandpostgres_scan_pushdowntable生成函数,例如:
SELECT * FROM postgres_scan('dbname=myshinydb', 'public', 'mytable');
SELECT * FROM postgres_scan_pushdown('dbname=myshinydb', 'public', 'mytable');
复制这两个函数都接受三个未命名的字符串参数:thelibpqconnection字符串(见上面)、一个Postgres模式名和一个表名。模式名通常是公共的。顾名思义,名称中带有“下推”的变量将执行如下所述的选择。
Postgres扫描器只能读取实际的表,不支持视图。但是,你当然可以在DuckDB中重新创建这样的视图,语法应该完全相同!
实现
从体系结构的角度来看,Postgres Scanner是作为DuckDB的插件扩展实现的,它在DuckDB中提供了所谓的表扫描函数(postgres_scan)。在DuckDB和扩展中有许多这样的函数,如Parquet和CSV读取器,Arrow读取器等。
Postgres Scanner使用standardlibpqlibrary,它静态链接到该库中。讽刺的是,这使得Postgres Scanner比其他Postgres客户端更容易安装。然而,Postgres的普通客户端-服务器协议非常慢,所以我们花了相当多的时间来优化它。需要注意的是,DuckDB的ssqlite scanner不会面临这个问题,因为SQLite也是一个进程内数据库。
我们实际上为Postgres的数据库文件实现了一个原型直接读取器,虽然性能很好,但存在一个问题,即已提交但还没有检查点的数据还没有存储在堆文件中。此外,如果检查点当前正在运行,我们的读取器将频繁地超过检查点,导致额外的不一致。我们放弃了这种方法,因为我们希望能够查询一个积极使用的Postgres数据库,并且相信一致性很重要。另一种架构选择是为类似于duckdb_fdws的Postgres实现一个DuckDB外部数据包装器(FDW),但是虽然这可以改善协议的情况,但在生产服务器上部署Postgres扩展是相当危险的,所以我们预计很少有人能够这样做。
相反,我们很少使用Postgres客户端-服务器协议的二进制传输模式。这种格式与Postgres数据文件的磁盘表示非常相似,并且避免了一些昂贵的从字符串和从字符串的转换。例如,要从协议消息中读取normalint32,我们所需要做的就是交换字节顺序(ntohl)。
Postgres扫描程序连接到PostgreSQL并使用二进制协议发出一个查询来读取特定的表。在最简单的情况下(参见下面的优化),要读取一个名为ledlineitem的表,我们在内部运行查询:
COPY (SELECT * FROM lineitem) TO STDOUT (FORMAT binary);
复制这个查询将开始读取lineitem的内容,并将它们以二进制格式直接写入协议流。
并发
DuckDB通过管道并行支持自动的内部查询并行化,因此我们还想并行化Postgres表上的扫描:我们的扫描操作符打开到Postgres表的多个连接,并从每个连接中读取表的子集。为了有效地分割读取表,我们使用Postgres相当晦涩的元组ID扫描(Tuple ID)操作符,它允许查询从表中外科般地读取指定范围的元组ID。Tuple id具有表单(page, Tuple)。我们基于以tid表示的数据库页面范围并行化对Postgres表的扫描。当前每个扫描任务读取1000页。例如,要读取一个由2500页组成的表,我们将启动三个扫描任务,TID范围为[(0,0),(999,0)],[(1000,0),(1999,0)]和[(2000,0),(UINT32_MAX,0)]。为最后一个范围设置开放边界非常重要,因为pg_classtable中的表中的页数(relpages)只是一个估计值。对于给定的页面范围(P_MIN, P_MAX),上面的查询被扩展为如下所示:
COPY (
SELECT
*
FROM lineitem
WHERE
ctid BETWEEN '(P_MIN,0)'::tid AND '(P_MAX,0)'::tid
) TO STDOUT (FORMAT binary);
复制通过这种方式,我们可以并行有效地扫描表,而不以任何方式依赖于模式。因为在Postgres中页面大小是固定的,这还有一个额外的好处,即读取页面子集的工作量与每行中的列数无关。
根据文档,元组ID是不稳定的,可能会被诸如vacuum ALL这样的操作所改变。如何使用它来同步并行扫描?QU确实存在这样的问题,但我们找到了一个解决方案:
事务同步
当然,当我们出于分析目的而运行表扫描时,像Postgres这样的事务数据库应该运行事务。因此,我们需要并行地处理对正在扫描的表的并发更改。我们首先在DuckDB的绑定阶段创建一个新的只读事务来解决这个问题,在这个阶段进行查询计划。我们让这个事务一直运行,直到完全读取表。我们使用另一个鲜为人知的Postgres特性pg_export_snapshot(),它允许我们在一个连接中获取当前事务上下文,然后使用ingset transaction SNAPSHOT …将其导入到并行读连接中这样,与单个表扫描相关的所有连接在整个可能很长的读取过程中看到的表状态都与扫描开始时完全相同。
映射和选择下推
DuckDB的查询优化器将查询计划中的选择(对行进行筛选)和投影(删除未使用的列)移动到尽可能低的位置(下推),甚至指示最下方的扫描操作符在支持这些操作的情况下执行这些操作。对于Postgres扫描器,我们实现了两个下推变量。投影相当简单——我们可以立即指示Postgres只检索查询正在使用的列。当然,这也减少了需要传输的字节数,从而加快了查询速度。对于选择,我们从下推的过滤器构造一个SQL过滤器表达式。例如,如果我们通过Postgres扫描器运行一个像eselect l_returnflag, l_linestatus FROM lineitem WHERE l_shipdate < '1998-09-02’这样的查询,它将运行以下查询:
COPY (
SELECT
"l_returnflag",
"l_linestatus"
FROM "public"."lineitem"
WHERE
ctid BETWEEN '(0,0)'::tid AND '(1000,0)'::tid AND
("l_shipdate" < '1998-09-02' AND "l_shipdate" IS NOT NULL)
) TO STDOUT (FORMAT binary);
-- and so on
复制可以看到,投影和选择下推相应地扩展了针对Postgres运行的查询。使用选择下推是可选的。在某些情况下,在Postgres中运行过滤器实际上比在DuckDB中传输数据和运行过滤器要慢,例如当过滤器的选择性不是很强(许多行匹配)时。
性能
为了研究Postgres Scanner的性能,我们在使用其内部存储格式的DuckDB上运行了著名的TPC-H基准测试,在Postgres上也使用其内部存储格式,并使用新的Postgres Scanner从Postgres读取DuckDB。我们使用了DuckDB 0.5.1和Postgres 14.5,所有的实验都在配备M1 Max CPU的MacBook Pro上运行。实验脚本是可用的。我们运行TPCH的“规模因子”1,创建一个约1gb的数据集,最大的表lineitem中有约6m行。22个TPC-H基准测试查询中的每一个都运行5次,我们以秒为单位报告运行时间的中位数。具体时间见下表。
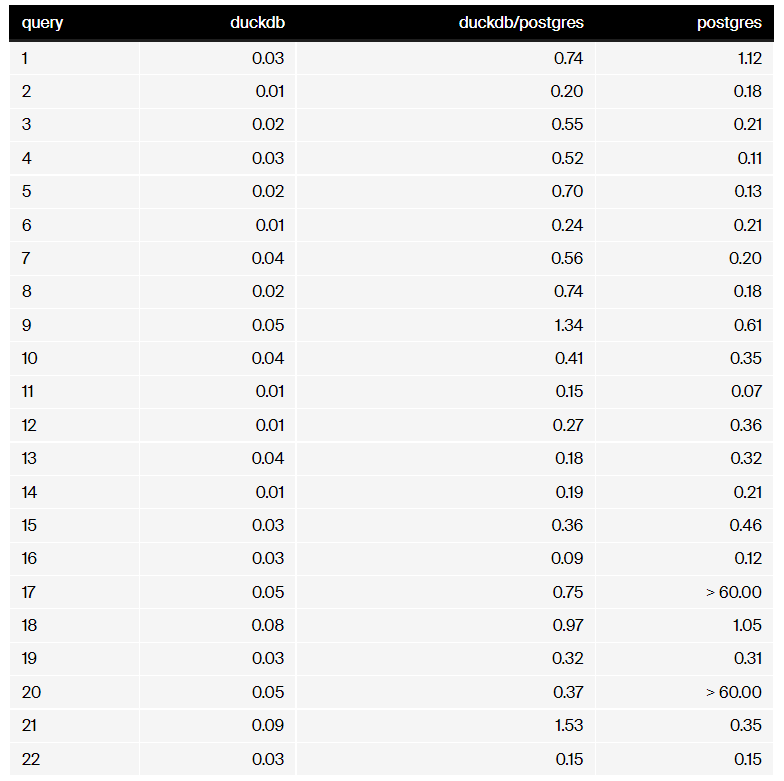
Stock Postgres无法在一分钟超时时间内完成查询17和20,因为相关的子查询包含行项表上的查询。对于其他的查询,我们可以看到,带有Postgres Scanner的DuckDB不仅完成了所有的查询,而且在其中大约一半的查询上,它的速度比普通的Postgres快,这是令人惊讶的,因为DuckDB必须通过上面描述的客户端/服务器协议从Postgres读取输入数据。当然,使用自己的存储,存量DuckDB仍然要快10倍,但正如本文开头所讨论的那样,这需要首先将数据导入那里。
其他案例
Postgres Scanner还可以用创造性的方式将实时Postgres数据与预缓存数据结合起来。这在处理仅附加表时特别有效,但如果存在修改后的日期列,也可以使用这种方法。考虑下面的SQL模板:
INSERT INTO my_table_duckdb_cache
SELECT * FROM postgres_scan('dbname=myshinydb', 'public', 'my_table')
WHERE incrementing_id_column > (SELECT MAX(incrementing_id_column) FROM my_table_duckdb_cache);
SELECT * FROM my_table_duckdb_cache;
复制提供了更快的查询性能和完全最新的查询结果。同时避免了复杂的数据复制。
DuckDB内置支持将查询结果写入Parquet文件。Postgres扫描器提供了一种将Postgres表写入Parquet文件的相当简单的方法,如果需要,它甚至可以直接写入S3。例如,
COPY(SELECT * FROM postgres_scan('dbname=myshinydb', 'public', 'lineitem')) TO 'lineitem.parquet' (FORMAT PARQUET);
复制结论
DuckDB的新Postgres Scanner扩展可以在PostgreSQL运行时读取PostgreSQL的表,并计算复杂OLAP SQL查询的答案,通常比PostgreSQL本身更快,而不需要复制数据。Postgres扫描仪目前正在预览中,如果您发现Postgres扫描器有任何问题,可以上传相关报告。
原文标题:Querying Postgres Tables Directly From DuckDB
原文作者:Hannes Mühleisen
原文地址:https://duckdb.org/2022/09/30/postgres-scanner.html
