




介绍
在数据科学面试中,您可能会被问到有关各种主题的问题。这些包括统计、机器学习、概率、数据可视化、数据分析和行为问题。除此之外,你的编码能力也通过要求你解决一个问题来测试,你可能会被要求解决一个数据科学案例研究。虽然可以通过练习获得编码和解决案例研究所需的技能,但保持坚实的基础可以澄清理论概念。

数据科学面试针对数据科学家、数据分析师、机器学习工程师、数据可视化工程师等各种角色进行。尽管角色不同,但要通过这些角色中的任何一个角色进行面试所需的核心技能是相同的。
在本文中,我们将研究数据科学面试中的几个重要问题。
数据科学面试题
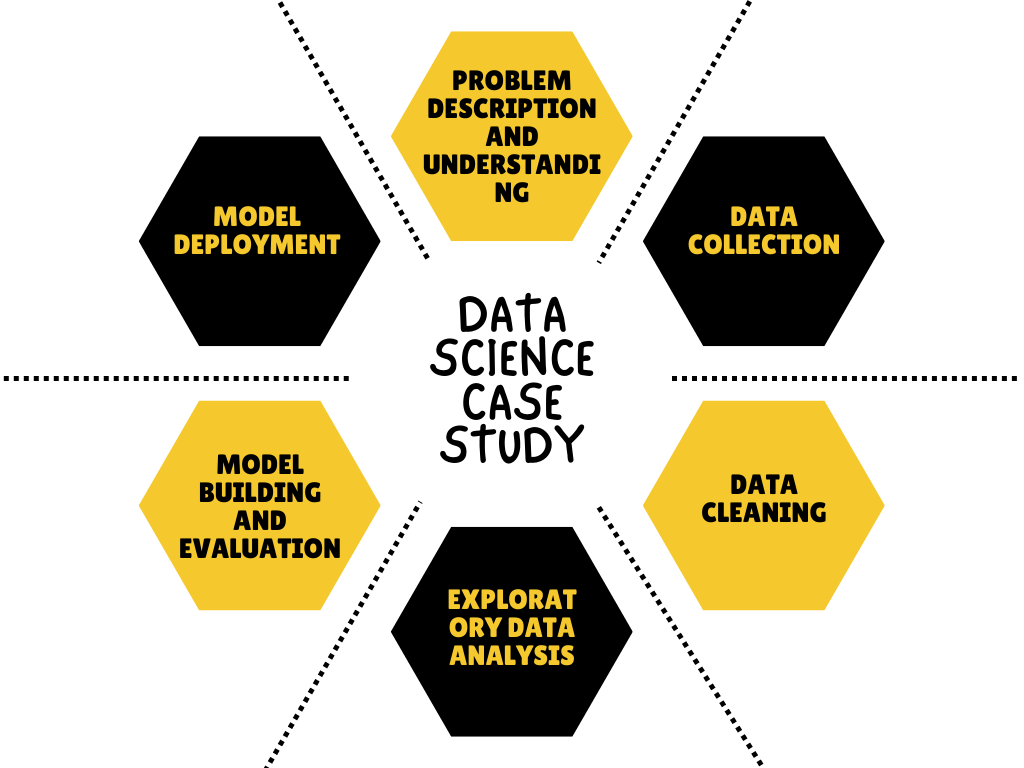
1. 描述数据科学案例研究的工作流程。
解决数据科学案例研究时涉及以下步骤。
- 问题描述与理解
- 数据采集
- 探索性数据分析(涉及数据探索、特征工程、异常值检测和处理,以及处理缺失数据)。
- 建筑模型
- 模型评估
- 模型部署
2.线性回归的假设是什么?
线性回归的假设是:
- 数据应具有线性关系。
- 应该有多元正态性。
- 没有或很少有多重共线性。
3. 什么是异常值,它们如何影响最终结果?
与其他观察结果显着不同的数据点被称为数据集中的异常值。异常值是与其余数据不同且不遵循通用数据模式的数据点。异常值可能会降低模型的准确性和效率,具体取决于其原因。它们会导致不利的数据分析问题并操纵整个过程,从而导致我们最终得到有偏见的结果。因此,重要的是检测数据中存在的任何异常值并对其进行处理。
数据异常值可以通过使用散点图、箱线图等可视化数据集来识别。
4. 假设检验中的 p 值是多少?
在假设检验中,p 值是指随机选择数据点出现的可能性。如果 p 值为 0.5 并且小于 alpha,我们可以得出结论,实验结果有 5% 的概率是偶然发生的,或者可以说,5% 的时间,我们可以偶然观察到这些结果.
5.什么是正态分布?
正态分布是一个概率函数,它描述了一个变量的值如何分布在所有可能的值上。
可以通过使用直方图或散点图绘制值来识别数据分布。如果表示分布的直方图有一个中心峰值,则它是正态分布的。均值和标准差是有助于识别数据正态分布的两个主要度量。
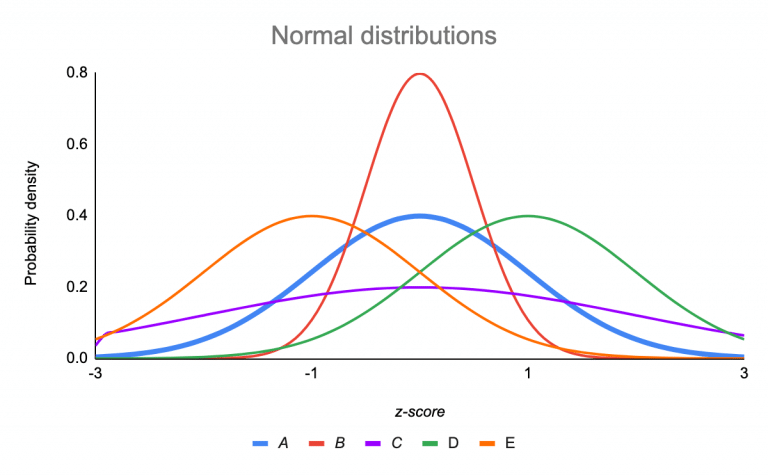
来源:https://www.scribbr.com/statistics/standard-normal-distribution/
在上图中,红线代表正态分布。
6. Python中如何计算数据的标准差?
标准偏差衡量数据点与数据中心点的偏差。它表示特定数据点与主要数据分布的距离。由于它测量了数据关于平均值的偏差,它显示了数据在平均值周围的分布。
它是使用 Numpy 方法“std”计算的。
例子:
a = np.array([[1, 2], [3, 4]]) np.std(a) >>> 1.1180339887498949
使用 np.std 方法,我们还可以计算特定轴上的标准偏差。也可以使用 Python 的统计模块中的 stdev() 方法。
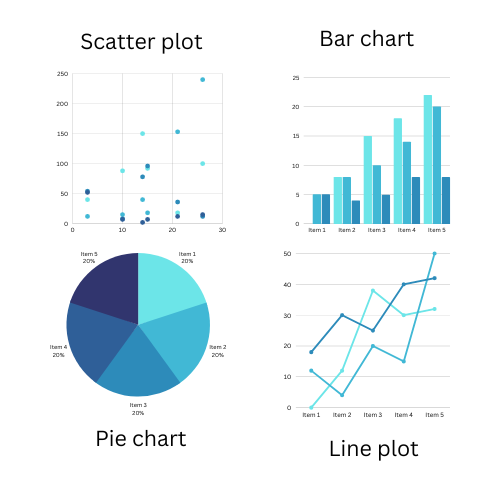
7. 数据可视化中有哪些不同类型的图?
地块可以根据用途分为以下几类:
- 相关图:它们为我们提供有关一个数据点相对于另一个数据点如何变化的信息。散点图、计数图、边际箱线图、热图和成对图是相关图的一些示例。
- 偏差图:此类图有助于识别数据中的变化量。偏差图的示例包括发散图和发散点图。
- 排名图:有时,我们可能需要知道数据的排名,如最大值、最小值、众数等。在这种情况下,排序图或点图等排名图就派上用场了。
- 分布图:分布图有助于了解数据的分布。连续和离散数据的直方图、密度图和箱线图是分布图的一些示例。
- 组成图:这些图告诉我们数据的组成。它们有助于了解某个数据点构成的整个数据集有多少。
- 变化图: 它们用于识别数据变量内的变化。时间序列图是变化图的一个突出例子。
8. 什么是偏差和方差?它们如何影响模型的性能?什么是偏差-方差权衡?
偏差是指实际值和预测值之间的差异。高偏差会导致欠拟合问题;因此低偏差是首选。
方差可以定义为模型对数据波动的响应。高方差会导致过度拟合问题,因此是不可取的。
偏差和方差都会影响模型在以高值存在时概括数据的能力。反过来,这会影响模型的准确性。因此,保持模型的偏差和方差之间的平衡很重要。必须选择正确的权衡点以提高模型的性能,同时确保模型的泛化能力不受影响。
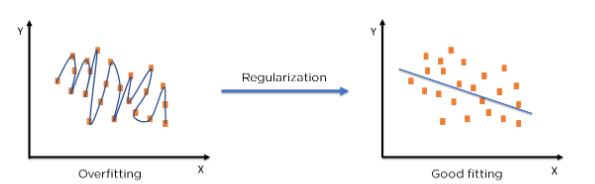
9. 定义正则化?
正则化是一种用于处理机器学习模型中过拟合问题的技术。在这里,我们保留特征数量并减小特征大小。它将系数的大小减小到零,从而避免了过拟合问题。正则化减少了特征的大小,同时允许我们保持所有的特征。
它有两种类型:Ridge 回归和 Lasso 回归。
10.机器学习在数据科学中扮演什么角色?
数据科学是一个需要其他学科(例如机器学习、深度学习和人工智能)输入来分析数据、构建解决方案和预测结果的领域。特别是,机器学习用于构建使用当前可用数据来预测结果的模型。在大多数情况下,数据科学案例研究解决方案是使用机器学习概念和方法构建的。有监督和无监督学习、探索性数据分析、特征工程、模型评估、超参数调优、epoch 等,是数据科学中广泛使用的一些机器学习概念。
结论
让我们回顾一下我们在本文中学到的知识。我们调查了
- 解决数据科学案例研究的不同步骤
- 用于表示数据的绘图类型
- 正则化如何帮助减少过拟合
- 我们了解了异常值对最终结果的影响
- 我们还快速浏览了许多机器学习概念,例如偏差、方差、标准偏差、线性回归 p 值等。
在参加数据科学面试之前,您必须了解以下几个重要问题。
除此之外,关于您从事的项目、您的工作经验、解决案例研究、SQL 查询、编码问题、机器学习的基本概念 和数据科学的问题也很常见。因此,您必须牢牢掌握所有上述概念和主题才能破解任何数据科学面试。
原文标题:10 Important Questions for Cracking a Data Science Interview
原文作者:Yamini Ane
原文地址:https://www.analyticsvidhya.com/blog/2022/10/10-important-questions-for-cracking-a-data-science-interview/
