




在数据管理和数据处理领域,Hadoop大数据系统带来了革命性的进展,目前已经成为企业数据平台的新常态。GoldenGate是一款经过时间检验和客户证明的用于实时数据集成和异构数据库复制的产品,可以在不影响源系统性能的情况下将交易数据实时传入Hadoop 大数据系统,帮助企业提供业务洞察的质量和实时性。然后Hadoop组件的一些天生特性,导致在使用GoldenGate同步数据到这些组件与同步到传统关系型数据库有很大差异,本文主要谈谈GoldenGate在Hive、Hbase、Kafka集成时一些值得关注的问题。选择这三个组件来介绍,是因为它们在企业里面使用率高。
当需要GoldenGate把数据实时同步到Hadoop大数据系统时, 通常要先回答一些框架性的问题,这些问题会帮助我们进行技术的决策。
为什么使用GoldenGate进行数据同步
源端是什么操作系统,什么版本的数据库
目标端是什么组件:Hive、HBase、Kafka
数据采用什么存储格式,是否有结构变更
当数据同步到目标端后,下游如何使用数据
下面针对这几个问题 进行一一分析。
是否有数据时效性的要求,需要数据实时采集,快速决策;是否以前批量的数据同步工具sqoop等对源端的DB的资源消耗太大;是否以前批量的数据同步工具sqoop不支持update,delete等增量数据同步等。了解需求驱动力可以明确关注重点,方便技术选型。
了解源端的操作系统和数据库版本,明确GoldenGate是否支持该源端,以及采用远程抽取方式还是经典抽取方式。
不同的Hadoop组件有不同的技术特性, GoldenGate在和他们集成时会受限于这些技术特性。
OGG与Hive的集成:由于Hive的数据存储在HDFS上,所以OGG与Hive的集成是通过和HDFS集成实现的。在Hive集成时要注意一下几点:
1. Hive不支持UPDATE和DELETE,所以和Hive集成,UPDATE和DELETE增量数据以记录的方式保存到Hive表中,使用数据时需要进行预加工, 当数据量非常大时,这部分加工会比较耗时,如果数据可以冷热分区,那么会减少一部分加工时长。
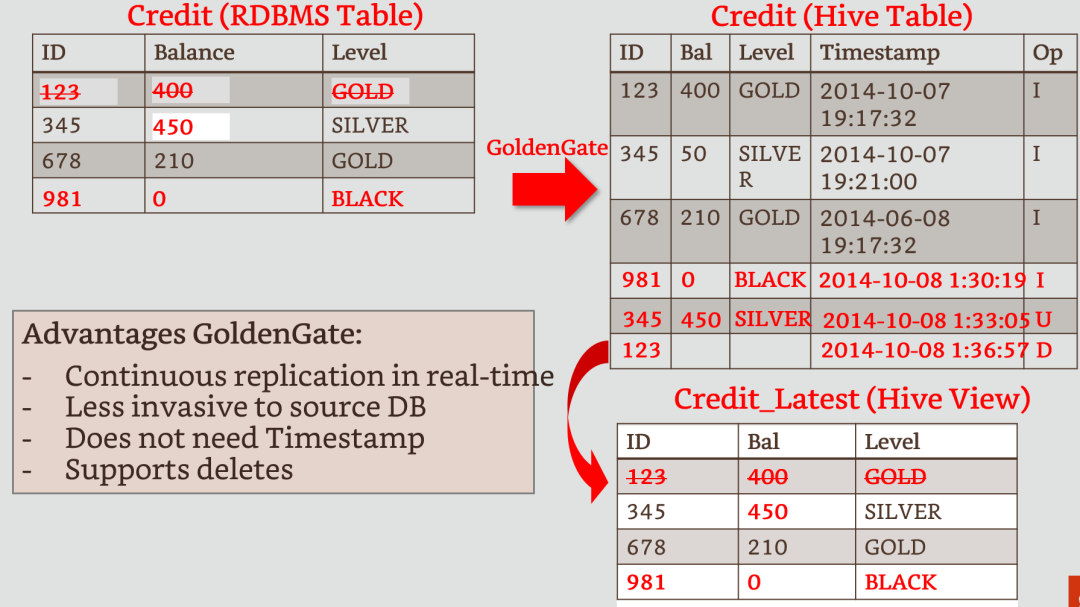
2. OGG到Hive不支持DDL同步, 当源端表结构发生变化时,需要手动修改Hive的表结构, 由于默认情况下Hive的数据和shema是分开存储的,当Hive的表结构修改后,还能否处理修改前的数据。这个时候可以考虑使用parquet这类存储shema信息的文件格式存储数据,OGG和Hive集成支持多钟文件格式。
3. OGG到Hive的数据读取是有延迟的,这是由于Hive无法读取当前正在写入的HDFS数据文件,可配置按时间和大小生成新的HDFS数据文件
OGG与Hbase的集成:由于Hbase支持UPDATE和DELETE, 如果同步的表有频繁的UPDATE和DELETE时,一般建议数据的目标端选择HBase. 然后在HBase上创建Hive表。但是世上没有十全十美的事情,当数据存储到Hbase上,会有数据膨胀,以前1T的数据,可能在HBase上会生成2T-4T的数据,HBase是以key-value方式存储数据,rowid和column名等都是Key值,所以膨胀量和rowid和column名等的大小有直接关系。笔者试过同一份数据分别存储在HDFS和HBase中, 使用Spark执行相同的SQL, HDFS的效率是HBase的4倍。
OGG与Kafka的集成:OGG保证到Kafka的数据至少投递一次,所以在消费数据时需要保证同一个数据消费多次对结果没有影响;由于Kafka的topic支持多partition, OGG按事务的顺序把数据写到Topic中, 消费时获取的数据顺序和事务的顺序不一致,如果要求事务顺序严格一致,那么建议设置为单Partition。
存储格式的选择涉及多个维度,根据使用的需求,企业内部规范,快速分析需求,结构变更的需求,以及选择的目标组件等。Hive中支持多种存储格式,可分为行存和列存,以及是否需要进行压缩,HBase只能以Hfile的格式存储数据 ;Kafka的消息也支持多种格式,也支持消息压缩。 目前如果有数据变更的需求,Hive中选择Parquet文件格式,或者选择使用HBase, Kafka中选择JSON都是不错的选择方案。下面文本,JSON格式的数据。


数据的使用场景在技术选型中起着非常关键的作用:
如果需要进行数据流式分析,那么Kafka是唯一的选择,这个时候考虑的是消息使用什么存储格式,是否需要多parttition,消息消费是否有幂等处理等。
如果同步过去的数据需要进行实时的查询,那么Hbase是一个很好的方案, 请设计好你的rowid, 当然Hbase还有很多成熟的二级索引方案。
如果需要进行数据处理分析时,理论上Hive是个非常好的方案,但是请注意HIVE不支持UPDATE和DELETE,如果数据变更比较多, 数据预处理的时间损耗和HBase膨胀带来的时间损耗就要去做取色,当然如是是DW项目时,需要保留数据的状态变化,那么HIVE是一个很好的选择。
在数据集成过程中,需要结合业务场景和技术特性进行综合考虑,希望这些框架性问题能对使用GoldenGate和Hadoop大数据系统集成时有帮助。

作者简介
高胜杰,甲骨文云平台数据集成高级咨询顾问,专注于甲骨文数据集成相关产品及解决方案。具有7+年的大数据、数据处理经验,熟悉甲骨文相关集成产品,方案和项目实施经验。您可以通过joy.gao@oracle.com与他联系。
扫描二维码或点击阅读原文
快速预约精选云解决方案演示





