




介绍
在现代数据世界中,Lakehouse 已成为构建数据平台的热门话题之一。企业已经慢慢开始将 Lakehouses 用于他们的数据生态系统,因为它们提供了数据湖的成本效益和仓库的性能。
这种 Lakehouses 背后的核心技术是开放表格式或存储框架,使它们能够拥有这些类似仓库的能力。企业和产品供应商正在使用三种主要的表格格式来提供 Lakehouse 功能。这些格式是
- Databricks 的 Delta Lake(也在 Linux 基金会下开源)
- 阿帕奇胡迪
- 阿帕奇冰山
在本文中,我们将探讨 Delta格式,它是最近引起很多兴趣的最流行的存储框架之一。我们将做一个简单的动手实验来了解 delta 格式的工作原理。
什么是Delta Lake?
Delta Lake 格式是一个开放的存储框架,可帮助您构建值得信赖的 Lakehouse 数据平台。它支持像 Amazon S3 或 Azure ADLS 这样的云对象存储,具有 ACID、时间旅行和模式演变等功能,这些功能对于实施 Lakehouse 至关重要。
我之前写过一篇博客,其中提供了有关 Delta Lake 格式的完整信息、它的好处以及它背后的驱动力。
Delta Lake 练习的实验室先决条件
我们将使用Databricks Notebooks进行实验,使用的语言将是Python和SQL。用户应具备以下技术/平台的基本知识。
- Python
- PySpark
- SQL
- 笔记本
即使您不了解 Databricks,也没关系。你可以按照分步过程来实施这个实验,你应该很好!
您应该设置您的实验室以执行此练习作为第一项活动。
实验室设置
您可以在本实验练习中使用“Databricks 社区版”。社区版可免费使用,并提供可用于学习目的的有限功能。
步骤 #1 – 使用 Databrick 社区版开设一个帐户
https://community.cloud.databricks.com/login.html
步骤 #2 – 创建一个 Spark 集群来执行笔记本
登录到 Databricks 工作区后,您必须首先创建一个集群。这可以通过单击左侧窗格中的“计算”选项卡来完成。
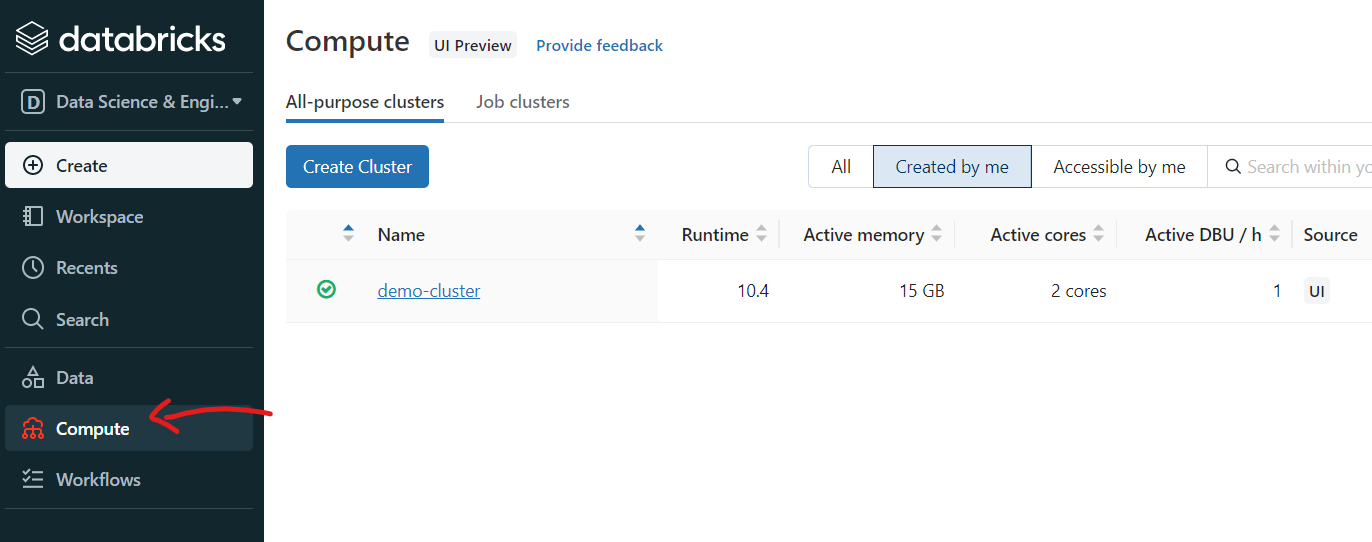
您只需提供集群名称,其余详细信息将自动填写。让它们保持原样。
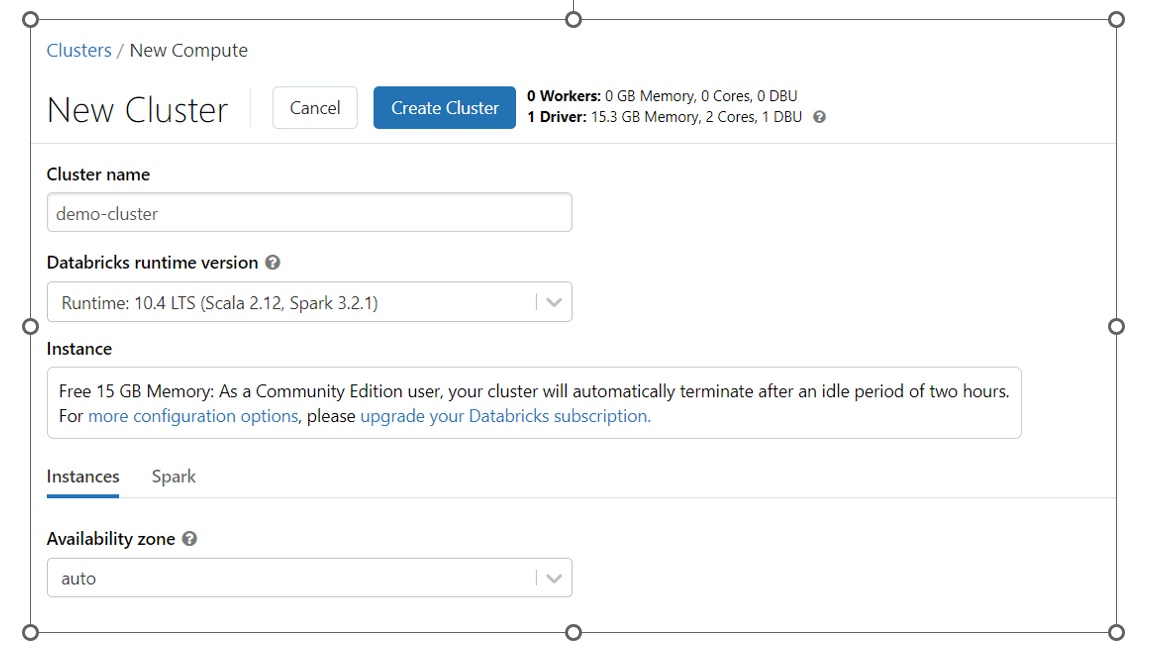
社区版提供15GB RAM的单节点集群,对于学习来说已经足够了。
步骤 #3 – 创建一个新笔记本
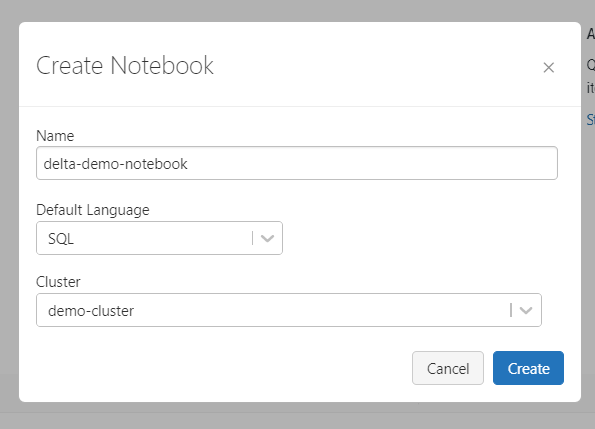
创建集群后(这可能需要几分钟),您可以使用左侧窗格中的“创建 >> 笔记本”选项创建一个新笔记本。
创建一个默认语言为 SQL 的新笔记本。在每个单元格中,我们可以根据需要将其更改为 Python 或其他支持的语言。
而已。可以了,好了!您已准备好进行实验室练习并探索 delta 格式。
让我们开始吧!
实验室练习
按照相同顺序执行这些步骤来探索和理解增量格式。每个步骤都有可以在笔记本中执行的笔记本命令。
步骤 #1 – 创建一个增量表
首先——让我们创建一个简单的 delta 表,这是任何 delta Lake 实现的起点。
如果不存在就创建表 (id int,角色字符串,名称字符串)复制
在 Databricks 中创建表时,通常将其创建为增量表。在上面的命令中,我们创建了一个托管/内部表,因为我们没有给出任何外部位置。
步骤 #2 – 检查底层文件
让我们描述一下表格以获得更多信息。
描述细节复仇者复制
它将给出类似于以下屏幕截图的结果

观察“格式”和“位置”列中的值。
- 格式:增量。[Databricks 中的默认格式是 delta]
- 位置:dbfs:/user/hive/warehouse/avengers。[这是托管表的默认位置,类似于基于Hadoop的生态系统中的Hive托管表]
步骤 #3 – 检查表位置
现在我们已经描述了表格,让我们看看在文件级别发生了什么。它是否创建了任何文件?有日志吗?
%Python 显示(dbutils.fs.ls(“dbfs:/用户/配置单元/仓库/复仇者”))复制
注意:在上述命令中,“%python”用于在此单元格中切换到 Python 语言。如果您还记得,我们使用“SQL”作为默认语言创建了这个笔记本。这在 Databricks 笔记本中称为魔术命令。

您会发现没有 parquet 文件,因为我们还没有向表中添加任何数据。但是,将创建 delta_log 文件夹。
这个 delta 文件夹是什么?它有任何文件吗?让我们在接下来的步骤中探索它。
步骤 #4 – 检查 delta 文件位置
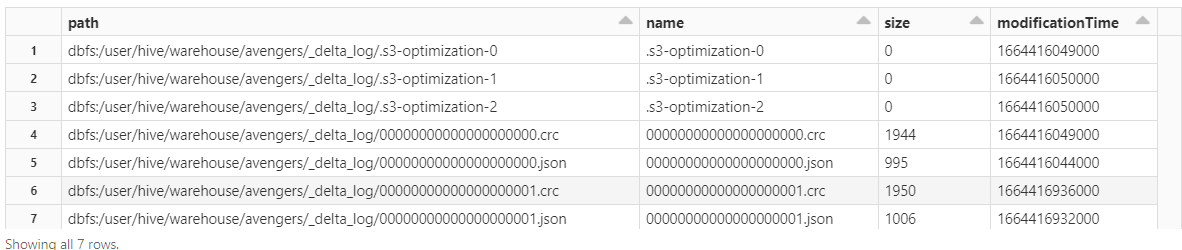
检查 delta 文件夹的内容——它有任何文件吗?
%Python 显示(dbutils.fs.ls(“dbfs:/user/hive/warehouse/avengers/_delta_log/”))复制
是的,它有!您将找到一个 JSON 文件和一个 CRC 文件,如下面的屏幕截图所示。

此 json 文件包含与提交日志相关的主要信息。这就是所有魔法发生的地方!
步骤 #5 – 从 delta 位置检查 JSON 文件
现在让我们探索 delta 日志中的 JSON 文件
%Python display(spark.sql(f"SELECT * FROM json.`/user/hive/warehouse/avengers/_delta_log/00000000000000000000.json`"))复制
注 – 您可以直接对 json 文件执行 spark SQL 查询
如果您使用上述命令检查 JSON 日志,您可以看到在“元数据”列中创建的表的 Schema。

步骤 #6 – 向表中添加新记录并检查表位置
现在让我们在增量表中插入一条新记录
插入复仇者联盟的价值观 (001,“美国队长”,“史蒂夫·罗杰斯”)复制
是时候检查桌子的位置了。
%Python 显示(dbutils.fs.ls(“dbfs:/用户/配置单元/仓库/复仇者”))复制

您将观察到终于添加了一个新的 parquet 文件!这个 parquet 文件代表我们刚刚添加到表中的数据。
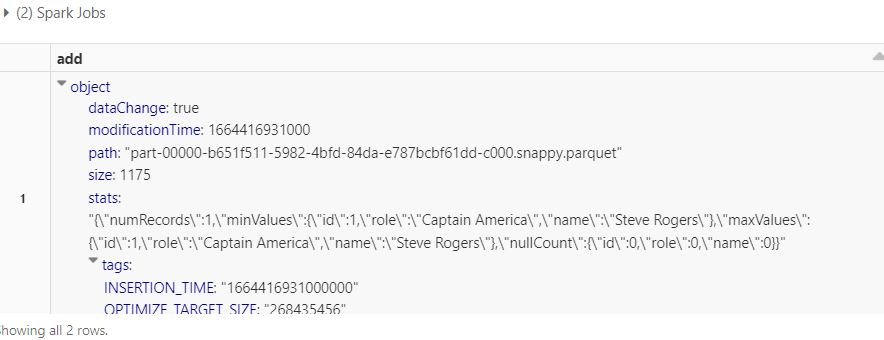
另外,检查 delta_log 文件夹,你会看到另外两个文件添加了 'xxx01.json' 和 'xxx01.crc'
如果您观察 delta 日志中的 'xxx01.json' 文件,您将看到插入在“添加”列中的记录的详细信息。
display(spark.sql(f"SELECT * FROM json.`/user/hive/warehouse/avengers/_delta_log/00000000000000000001.json`"))复制
步骤 #7 – 删除记录并检查表格
和Insert一样,让我们对delta表做更多的操作。让我们删除一条记录,然后检查表内容。
从 id=001 的复仇者联盟中删除复制
从复仇者中选择*;复制
您将观察到表中没有记录。
步骤 #8 – 使用版本号进行时间旅行
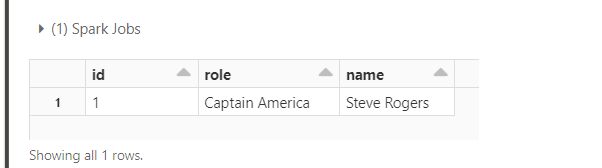
现在使用版本号尝试相同的查询
SELECT * FROM avengers VERSION AS OF 1;复制
您将观察到此查询确实获取了记录。
这显示了 Delta 格式的时间旅行能力。您可以通过指定正确的版本号来访问旧版本的记录。
步骤 #9 – 使用时间戳进行时间旅行
同样,您也可以使用时间戳进行时间旅行。但首先,让我们获取插入记录时的时间戳。这可以通过检查表历史记录来观察。
描述历史复仇者;复制
表历史记录存储在增量表上完成的所有操作以及时间戳。D

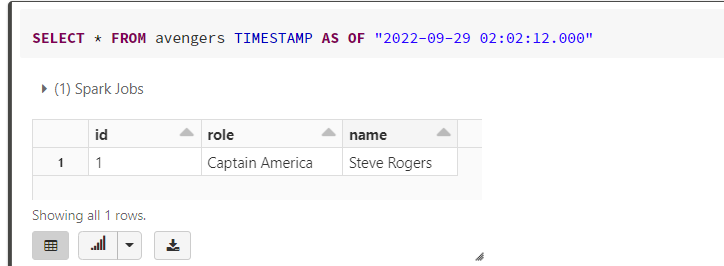
在选择查询中使用此时间戳来访问旧数据。您将能够看到在此时间戳插入的一条记录。
SELECT * FROM avengers TIMESTAMP AS OF "2022-09-29 02:02:12.000"复制
这将我们带到了实验室的尽头。但是不要忘记通过删除您创建的增量表来清理数据,如下一步所示。
步骤 #10 – 删除表格
掉落表复仇者;复制
这将删除元数据和数据文件,因为这是一个托管表。
恭喜,您现在是 delta 用户,了解 delta 的工作原理以及如何使用其时间旅行功能!如果您想深入了解,我建议您阅读 Databricks 下面的博客。
https://www.databricks.com
结论
在本教程中,我们学习了如何创建增量表、读取底层增量日志以及使用时间旅行等功能。
以下是要记住的关键点
- Delta Lake 是一种用于实施 Lakehouse 解决方案的开放存储格式。
- Databricks 可用于使用增量格式创建表
- 每个增量表都会创建一个称为增量日志的事务日志。
- Delta 日志可用于向数据湖添加 ACID 功能。
- Delta 还通过使用版本号或时间戳来支持时间旅行功能。
原文标题:Delta Lake in Action – Quick Hands-on Tutorial for Beginners
原文作者:GT Thalpati
原文链接:https://www.analyticsvidhya.com/blog/2022/10/delta-lake-in-action-quick-hands-on-tutorial-for-beginners/
