




介绍
数据模型 l是我们用来创建、捕获和存储用户应用程序需要的数据库中的数据的真实世界事件的抽象,省略了不必要的细节。如前所述,在确定需求时,我们会收集有关不同业务流程的信息以及每个流程所需的数据。在这个过程中,数据库设计者更有可能收集大量信息——并非所有信息都是最初用于建模数据的。我们需要将业务对象和理解业务对象的信息分开。
.png)
数据抽象
当我们从数据模型的一个级别(高级概念化到低级实现)移动到另一个级别时,这就是如何向业务对象添加更多细节。当我们从用户级别的数据请求转移到数据库中数据的物理表示时,我们将遵循数据抽象的级别。我们称之为三层数据库设计架构。
为了方便用户与数据库的交互,开发人员对用户隐藏了内部非必要的细节。这种向用户隐藏不相关细节的过程称为数据抽象。这里使用的与用户相关的术语“不相关”并不意味着隐藏数据与整个数据库无关。这只是意味着用户对这些数据不感兴趣。
例如:当您预订火车票时,您不关心点击“订票”时后面的数据是如何处理的;当您进行在线支付时会发生哪些流程?您只关心成功预订机票时出现的消息。这并不意味着后面正在进行的过程不相关,这意味着您作为用户,对数据库中发生的事情不感兴趣。
三级数据抽象
• 外部层面
• 概念层面
• 内在层次
数据库的物理实现在选定的数据库管理软件中,选定的硬件系统遵循这三个层次,如下图一所示。
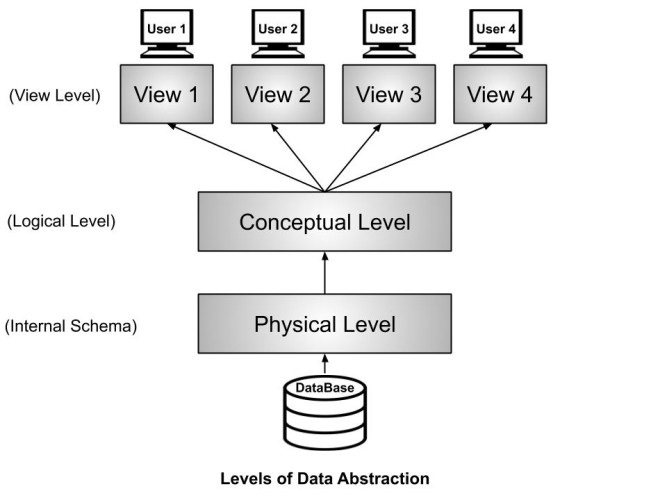
外层
这个级别也被称为外部视图。识别每个用户组的数据需求包括识别用户对数据的看法。首先,我们介绍每个用户组需要哪些数据,以及将哪些数据存储在底层数据库中。数据库设计满足整个组织的数据需求。
因此,用户组是组织的一个部门或部门。这样一个部门或部门的数据需求可能只是满足其功能需求所需的一小部分数据。因此,每个部门或部门可能需要一个可能不同的数据集;但是,可能与其他相关部门或部门有一些重叠。
考虑一所假设的大学,您所在地区的学习大学,我们要为其设计一个数据库。我们识别用户组如下:
- HRD 视图 — HRD 需要有关员工的数据,即支持和学术人员、有关员工福利的信息等。
- Enrollment View – 注册办公室,需要有关学生注册和学生考试结果的信息。
- 帐户视图 - 需要有关经济援助、奖学金和学生费用支付信息的学生帐户(商务办公室)。
- 学生生活视图——学生生活,需要关于住在宿舍的学生的数据
- Athletic View - 一个体育部门,需要有关学生参加一项或多项运动的数据,这些运动代表大学参加地区、州和国家体育赛事。
- 员工表将包含有关员工的信息;工作台将包含特价数据。
- 教授表的特征将包含学术人员的数据。
- 职位表将包含不同的职位。
- 计划表将包含有关各种健康和人寿保险计划的信息。
- 福利表将包含员工选择的福利数据。
HRD外观:
请注意,我们在这里仅确定了大学内的少数用户组,但可能还有更多的用户组未包含在我们的讨论中。我们想设计一个数据库,将共同满足上述所有组的数据需求。
因此,我们需要了解我们设计的数据库可以满足的数据需求。每个用户组只会看他们需要什么,而不管其他用户组。每个用户组都可以认为我们只是为他们设计数据库,因此是他们对数据的看法。因此,数据的每个用户视图代表一个外部视图。当我们结合所有外部视图时,最终的设计必须满足所有用户群体的数据需求。
HRD 需要员工数据。由于从支持人员那里收集的信息与从学术人员那里收集的信息不同,RLZ 建议我们将有关学术人员和非学术人员的一些不同信息存储在单独的表格中。只有一组通用信息存储在一个 Employee 表中。
这些只是设计标准,并不是必须拥有三个表 Employee、Employees 和 Professor。稍后我们将详细讨论表设计,解释如何决定如何在不同的表中存储信息。有了这个注释,我们就有了以下 HRD 模型。
HRD 的外观在 ERD 中以 Chen 的符号表示如下:
注册员的外部视图:注册员需要有关学生的信息,每个学期的学生注册情况,考试成绩和成绩。学生表将包含关于学生信息、学生注册记录表、课程表和课程表中的课程表的数据。注册办公室的外观在 ERD 的陈氏符号中。
学生帐户的外部视图:
学生账户部是商务办公室的一部分,负责处理学生费用、奖学金和经济援助。学生帐户需要有关学生、每学期注册学生、评估费用以及授予奖学金和经济援助的信息。学生的外部视图
该帐户在 ERD 中的 Chens Notations 中显示如下:
正如您从上述场景中注意到的那样,不同用户组之间的信息重叠。数据库设计者必须在创建最终数据库之前组合来自所有用户的数据请求。
概念层
此抽象级别满足组织数据要求。我们经常使用“概念化”这个词来表示给定情况的整体情况。一旦概念化,很容易想象。在数据库设计中,概念层代表数据的组织视图,它将外部视图组合或集成到单个视图中。
正如高级管理人员所见,它是组织范围内的数据表示。在该级别,我们识别主要数据对象并以最少的细节描述它们。这是我们根据它们之间可能存在的关系来查看数据的地方。
为了更好地概述数据表示,我们使用最常用的概念模型:实体关系模型(ERM)。使用 ERM,我们创建了用于设计数据库的概念图。下图显示了使用 ERM 创建概念图。这种方法的优点是将所有外部视图结合到组织的数据需求中,并显示数据之间的关系。
当我们使用 ERM 创建概念图时,应该注意 ER 模型独立于我们可以用来创建数据库的数据库软件。它独立于我们实现模型的硬件。因此,ER 模型独立于软件和硬件平台。这为我们在概念级别建模提供了灵活性,因为数据库管理硬件或软件的任何更改都不会影响概念级别。
内层
内部模型特定于 DBMS 的选择。我们将概念模型实施到这个特定的DBMS修改中。本质上,我们将概念模型映射到所选模型的特征和限制上。这意味着内部模型依赖于 DBMS。因此,DBMS 软件的更改可能需要更改 ER 模型映射以满足 DBMS 要求。概念模型不受影响。这称为逻辑独立性。
假设我们决定使用关系 DBMS;然后,我们的概念模型将映射到 RDBMS 内部模型。这样,我们的实体将被映射到表。但是,我们选择安装DBMS的硬件平台并不重要,这使得内部模型独立于硬件,因为它不受我们选择安装软件的计算机的选择影响。
结论
这些系统由复杂的数据结构组成;每次用户与系统交互时,开发人员通常会向用户隐藏内部非必要的细节。隐藏不相关细节的过程称为数据抽象。抽象通常是从某事物中删除元素以减少基本元素集的过程。它通常是数据库设计的第一步。在不首先创建一个简化结构的完整数据库的情况下创建一个系统要复杂得多。这些允许开发人员从基本要素(数据抽象)开始,并添加递减的数据细节以创建最终系统
- 识别每个用户组的数据需求包括识别用户对数据的看法。首先,我们介绍每个用户组需要哪些数据,以及将哪些数据存储在底层数据库中。
- 因此,ER 模型独立于软件和硬件平台。这为我们在概念级别建模提供了灵活性,因为数据库管理硬件或软件的任何更改都不会影响概念级别。
- 使用 ERM,我们创建了用于设计数据库的概念图。下图显示了使用 ERM 创建概念图。这种方法的优点是将所有外部视图结合到组织的数据需求中,并显示数据之间存在的关系。
原文标题:Data Abstraction for Data Engineering with its Different Levels
原文作者:Gitesh Dhore
原文链接:https://www.analyticsvidhya.com/blog/2022/10/data-abstraction-for-data-engineering-with-its-different-levels/
