




灾难恢复(DR)是企业级数据库的核心功能。数据库供应商一直在寻求改进灾难恢复,在过去10年中,他们进行了重大创新。
本文简要介绍了数据库灾难恢复的历史,重点介绍了基于云的分布式数据库中的灾难恢复和高可用性(HA)创新。
测量HA和DR
HA和DR的目标是保持系统在操作级别上正常运行。它们都试图消除系统中的单点故障,并自动执行故障转移或恢复过程。
高可用性通常以系统每年运行的时间百分比来衡量。灾难恢复的重点是在发生灾难后以最小的数据丢失使系统恢复服务。这由两个指标来衡量:恢复所需的时间或恢复时间目标(RTO)和数据量的丢失或恢复点目标(RPO)。RPO和RTO应尽可能降低。
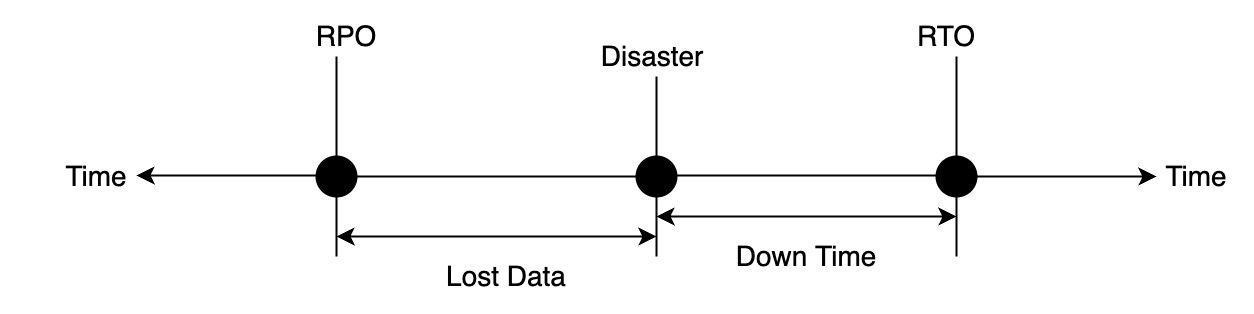
每个灾难都是唯一的,因此容错目标(FTT)描述了系统能够生存的最大灾难范围。常用的FTT是地区级别的,它表示灾难已经影响到像州或城市这样的地理区域。
DR简史
数据库灾难恢复技术经历了三个阶段:备份和恢复、主动-被动和多主动。
备份和恢复
在灾难恢复的早期阶段,数据库利用数据块和事务日志为完整和增量数据创建备份。如果发生灾难,将从备份和应用程序事务日志中恢复数据库。
近年来,公共云数据库服务将存储复制与传统数据库备份技术相结合,提供了基于快照的跨区域自动恢复备份。这种方法定期从源区域的数据库生成快照,并将快照文件复制到目标区域。如果源区域崩溃,则从目标区域恢复数据库,并且服务将继续。此解决方案的RTO和RPO可能长达数小时,因此最适合于没有严格可用性要求的应用程序。
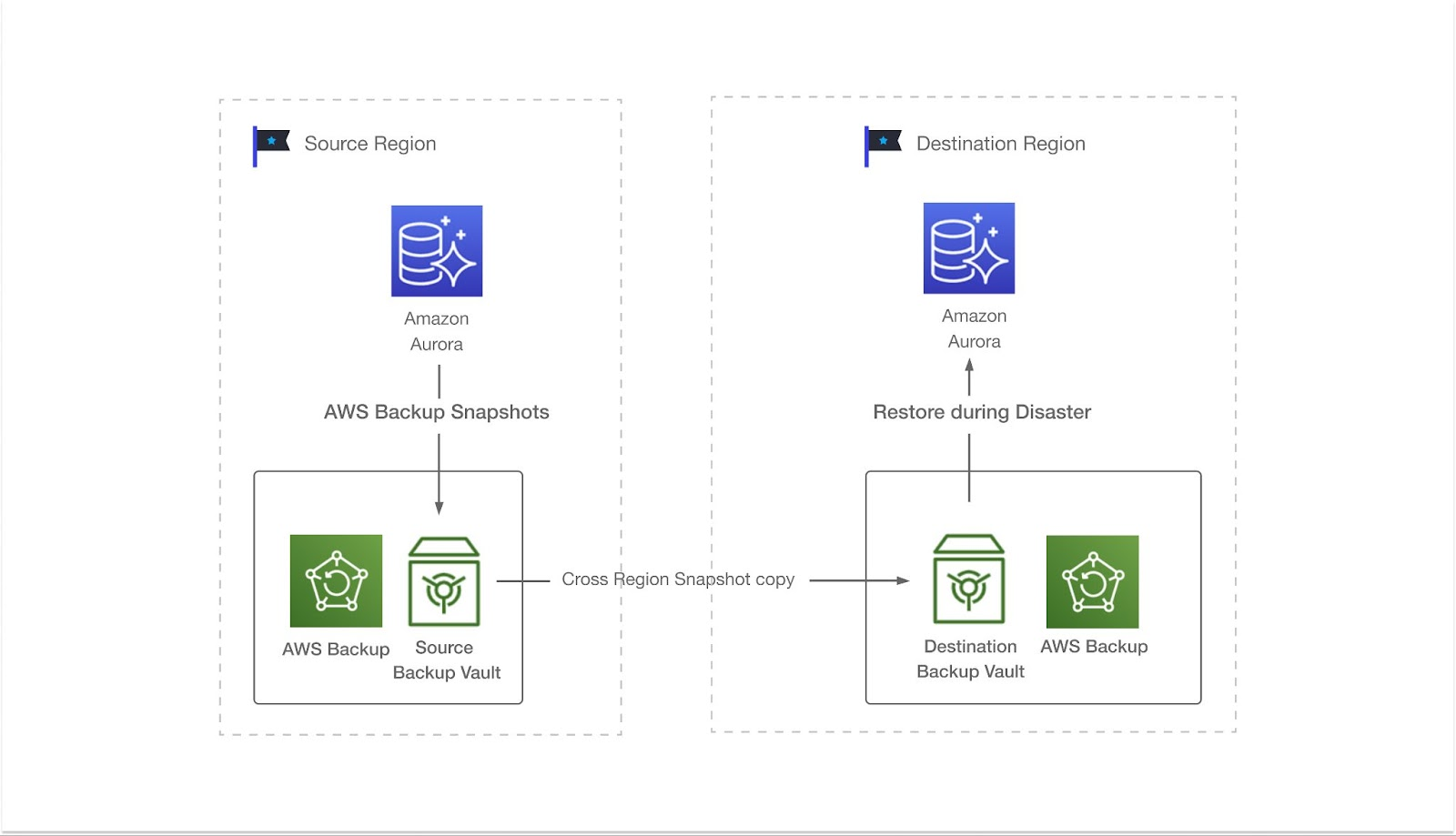
主动-被动DR
数据库集群标志着开发的第二阶段。在集群中,主节点读写数据。一个或多个备份节点接收事务日志并应用它们,从而提供具有一定延迟的读取功能。
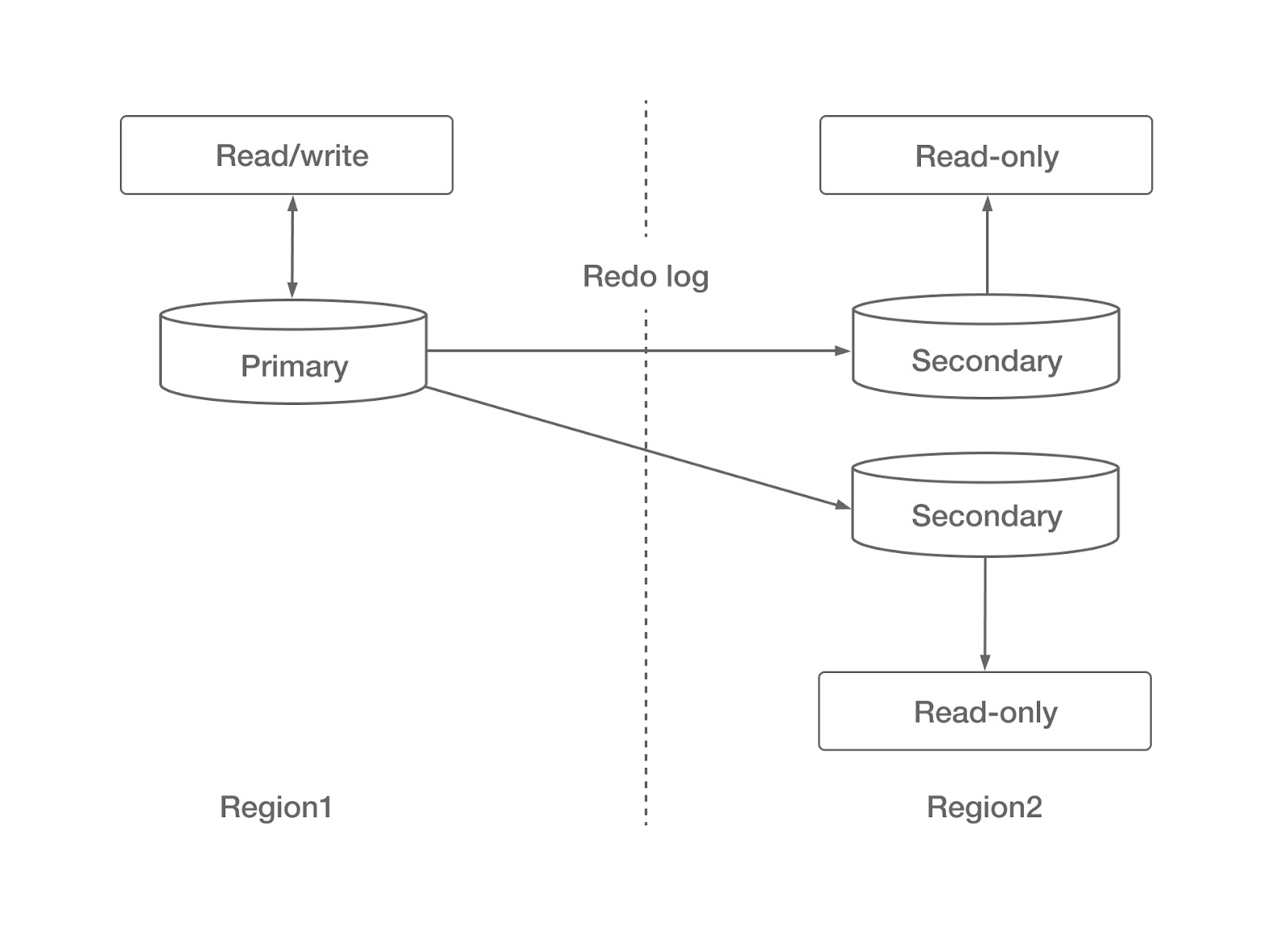
虽然这个解决方案涉及集群的概念,但它仍然基于一个单片数据库。可扩展性仅限于读操作;它不能缩放写入。当然,与上一代相比,RTO减少到几分钟,RPO减少到几秒钟。
amazonaurora使用跨区域读取副本的逻辑复制,是建立在该技术基础上的早期云数据库服务之一。
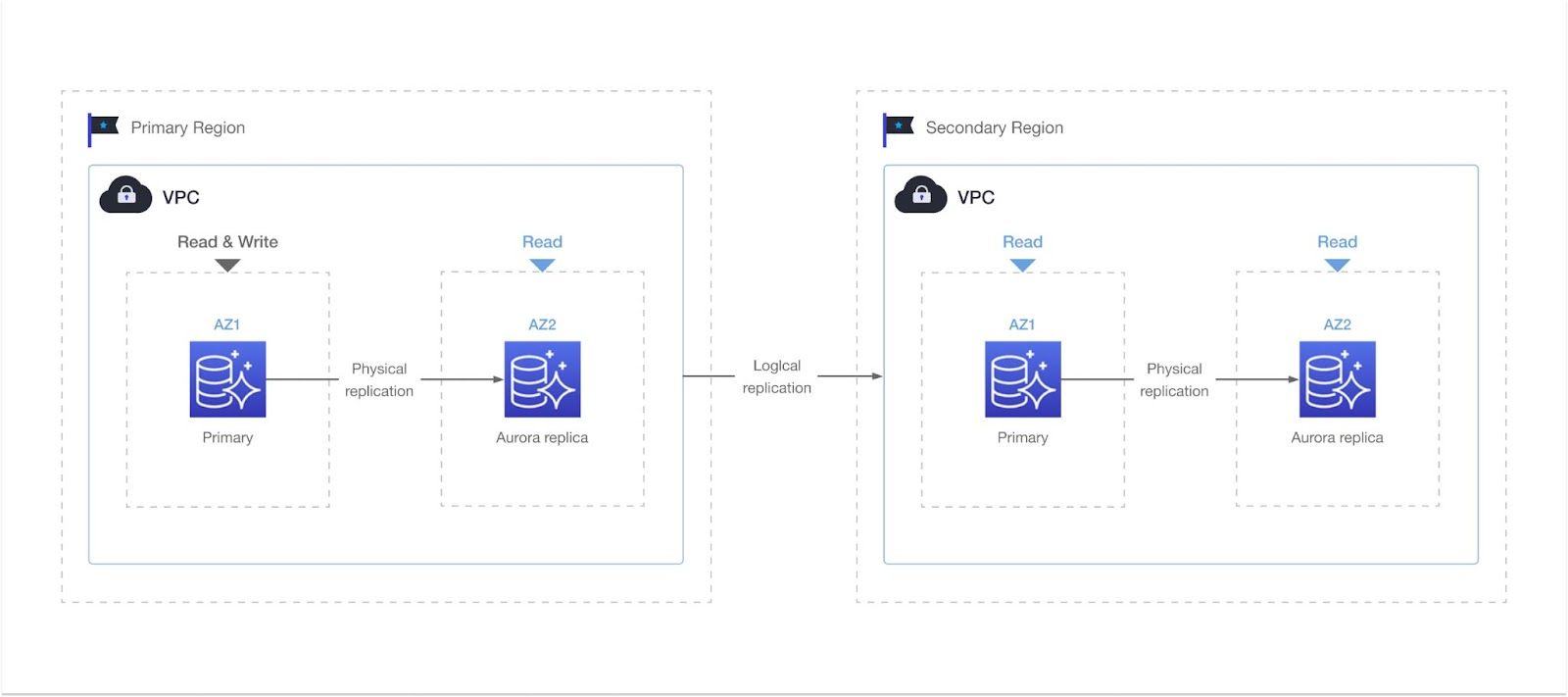
近年来,Aurora基于这一设计,提供全球数据库服务。此服务使用存储复制技术将数据从源区域异步复制到目标区域。如果源区域出现故障,服务可以立即故障转移到备份群集。RTO可以缩短到几分钟,RPO不到1秒。
高并发灾难恢复
在多活动灾难恢复中,一个数据库为同一个数据副本提供至少三个读写服务节点,并且数据库可以根据工作负载进行扩展或扩展。这种功能背后的需求来自于广泛的互联网规模的应用程序,它要求更高的性能、更低的延迟、更高的可用性、弹性的可伸缩性和数据库的弹性。
传统的基于一列或多列共享数据的分片数据库形成了多活动性。分片解决方案通过事务日志复制实现灾难恢复。例如,Google曾经维护过一个非常大的MySQL分片系统。此解决方案提供了一定程度的可扩展性,但无法随着碎片的增加而提高灾难恢复能力。性能将显著下降,维护成本将大幅上升。因此,分片是解决多活动性的过渡方案。
近年来,基于Raft或Paxos共识协议的零共享数据库发展迅速。它们解决了上面提到的可伸缩性和可用性难题。多活动时代的主要参与者包括TiDB和CockroachDB。他们的数据库以及灾难恢复技术使大多数遗留数据库和关系数据库服务(RDS)过时。
具有分布式数据库的多活动灾难恢复
让我们看看多活动灾难恢复在分布式数据库中的应用。例如,TiDB是一个开源和高可用性的分布式数据库。它将每个表或分区划分为更小的TiDB区域,并在这些TiDB区域中的不同TiKV节点上存储数据的多个副本。这称为数据冗余。TiDB采用Raft共识协议,因此当数据发生变化时,只有当事务日志与大多数数据副本同步时,才会返回事务提交。这大大提高了数据库RPO。实际上,在大多数情况下,RPO是0。这可以确保数据的一致性。此外,TiDB的架构将其存储和计算引擎分开。这允许用户根据工作负载的变化扩展TiDB节点和TiKV存储节点。
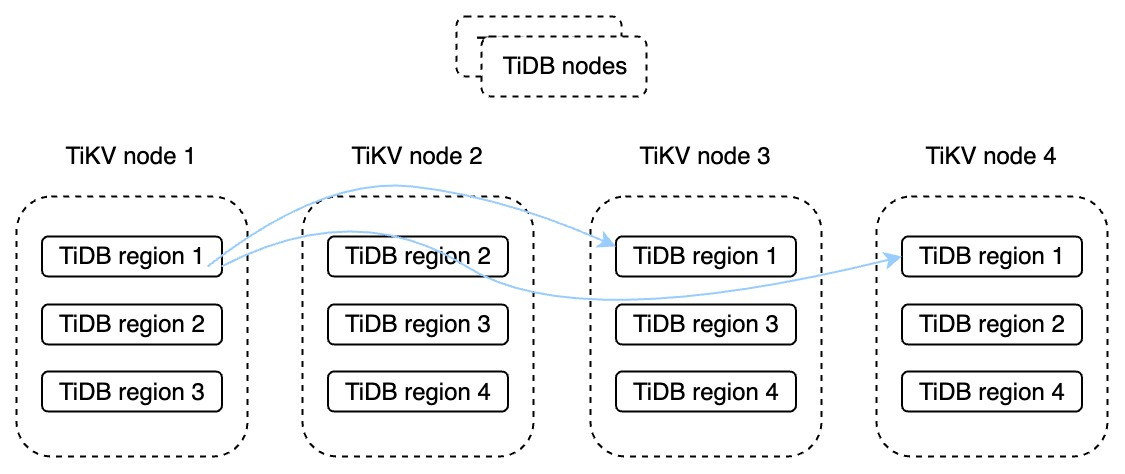
典型的多区域灾难恢复解决方案
下图显示了TiDB如何提供典型的多区域灾难恢复解决方案。
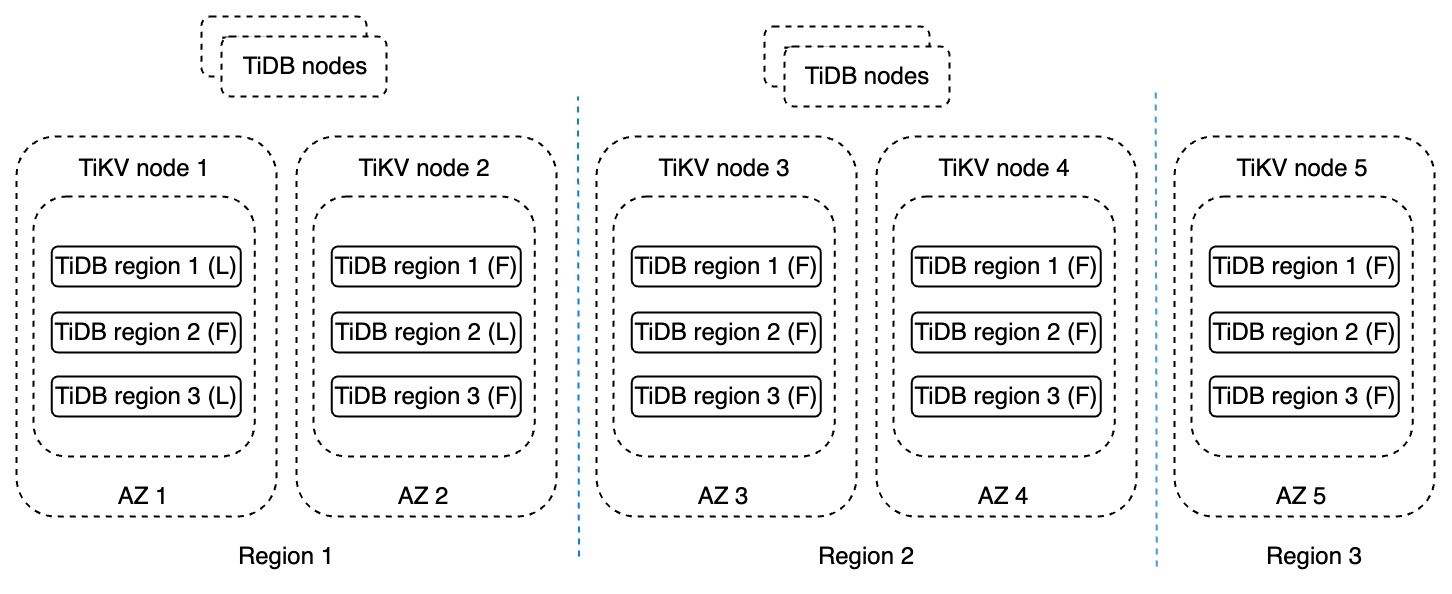
以下是TiDB DR体系结构的关键术语:
-
TiDB区域:TiDB的调度和存储单元
-
地区:两个地点或城市。
-
可用区(AZ):一个独立的HA区域。在大多数情况下,AZ是一个地区内两个彼此距离较近的数据中心或城市。
-
L: Raft组的Leader副本
-
F: Raft组中的Follower副本
在上图中,每个区域包含两个数据副本。它们位于不同的AZ,整个星团跨越三个区域。区域1通常处理读写请求。区域2用于在区域1中发生灾难后进行故障转移,它还可以处理一些对延迟不敏感的读取负载。区域3是一个复制品,它保证即使在区域1完成后仍能达成共识。这种典型配置被称为“2-2-1”体系结构。这种体系结构不仅保证了灾难恢复,而且为业务提供了多活动能力。在这种架构中:
-
最大的容错目标可以是区域级的
-
可扩展写入能力
-
RPO为0
-
RTO可以设置为一分钟甚至更短。
许多分布式数据库供应商经常向其用户推荐此体系结构作为灾难恢复解决方案。例如,CockroachDB推荐其3-3-3配置,以实现区域级灾难恢复;扳手为多区域部署提供2-2-1配置。但是,当区域1和区域2同时不可用时,此解决方案不能保证高可用性。一旦区域1完全关闭,如果区域2上的任何存储节点出现问题,系统可能会出现性能下降甚至数据丢失。如果您需要多区域级别的FTT或严格的系统响应时间,则仍然需要将此解决方案与事务日志复制技术相结合。
增强型多区域灾难恢复,可捕获变化数据
TiCDC是TiDB的增量数据复制工具。它获取TiKV节点上的数据更改并将其与下游系统同步。TiCDC具有与事务日志复制系统类似的体系结构,但它具有更高的可伸缩性,并且在灾难恢复场景中与TiDB配合良好。
下面的配置包含两个TiDB集群。区域1和区域2一起形成集群1,这是一个5副本集群。区域1包含两个用于执行读写操作的副本,区域2包含两个副本,用于在区域1中发生灾难时进行快速故障转移。区域3包含一个副本,用于到达Raft组中的仲裁。区域3中的集群2充当灾难恢复集群。它包含三个副本,以便在区域1和区域2发生灾难时提供快速故障转移。TiCDC处理两个群集之间的数据更改同步。这种增强的体系结构可以称为2-2-1:1。
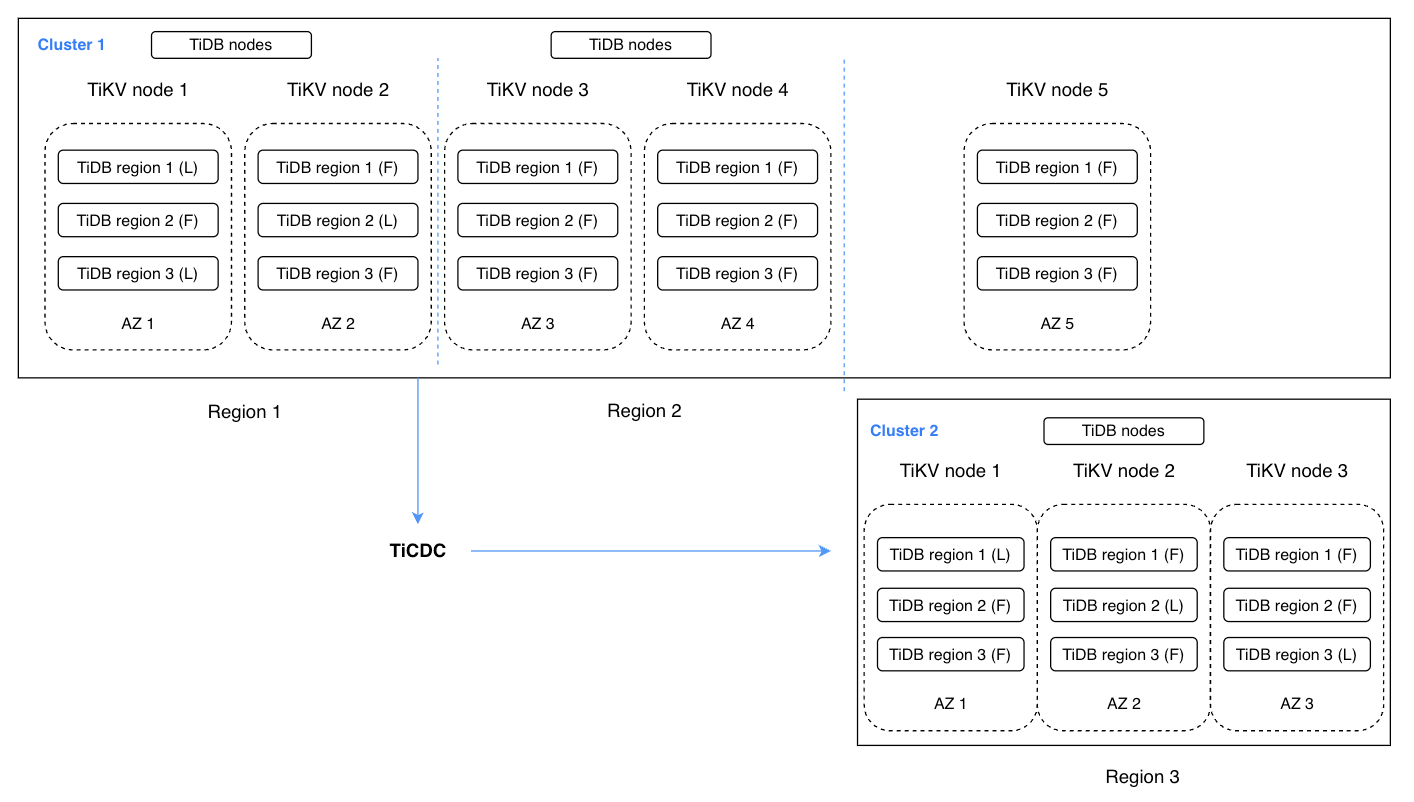
这种看似复杂的配置实际上具有更高的可用性。它可以在多区域级别实现最大的容错目标,RPO数秒,RTO数分钟。对于单个区域,在完全不可用的情况下,RPO为0。
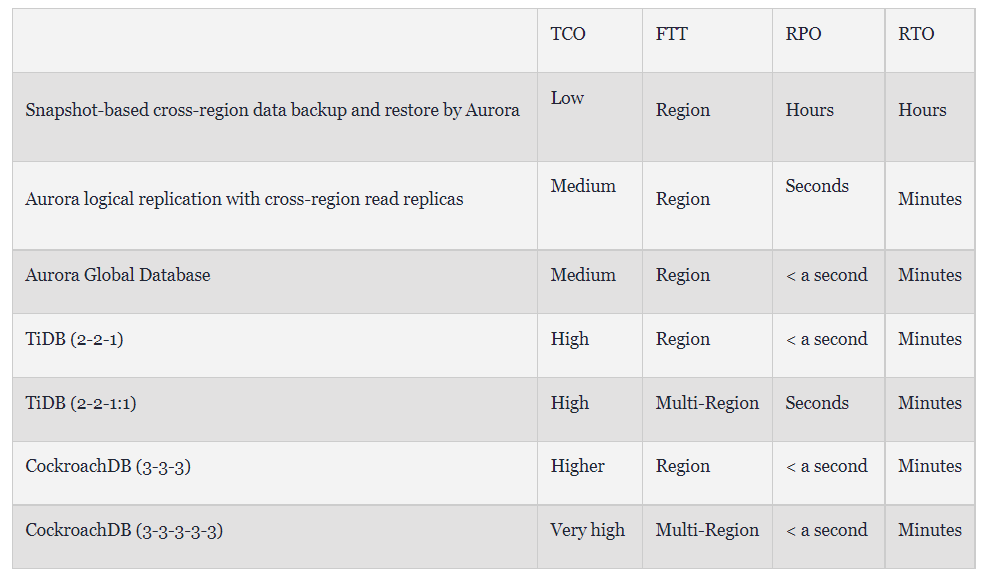
比较灾难恢复解决方案
在下表中,我们比较了本文中提到的灾难恢复解决方案:
总结
经过30多年的发展,DR技术已进入多活跃阶段。
像TiDB这样的分布式数据库使用无共享的体系结构,将多副本技术和日志复制工具结合起来,将数据库灾难恢复带入多区域时代。
原文标题:How Disaster Recovery Solutions for Cloud Databases Have Evolved Over the Years
原文作者:Allen Gao
原文地址:https://dzone.com/articles/how-the-disaster-recovery-solutions-for-cloud-data




