MySQL 5.7优化器的改进有更好地IN查询优化,sort buffer的内存优化,UNION ALL查询的优化,EXPLAIN正在执行的SQL语句支持等,另外可对代码进行重构。
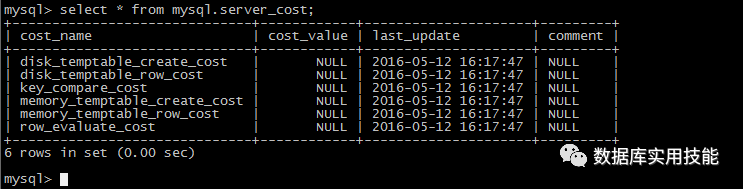
从5.7.5开始,优化器在执行计划的生成过程中有了额外的成本估算项可用。这些估算项存在在mysql系统库的server_cost和engine_cost表中,并且任何时候都可以通过修改表中的值来配置这些估算项。这些表存在的目的是,可以通过简单的调整这些表中的成本估算项来影响执行计划的生成,来达到调整执行计划的目的。
SQL优化器在以下几方面提升
• Generated columns and functional indexes
• New JSON datatype and functions
• New hint syntax and improved hint support
• Query rewrite plugin
• UNION ALL queries do not always use temporary tables
• Improved optimizations for queries with IN expressions
• Merging Derived Tables into Outer Query
• Explain on a running query
• 引入optmizer跟踪,Mysql 5.7以后引入了强大的optmizer跟踪
set optimizer_trace='enabled=on'
select * from information_schema.OPTIMIZER_TRACE
generated column生成列
generated column是MySQL 5.7引入的新特性,所谓generated column,就是数据库中这一列由其他列计算而得。
在MySQL 5.7中,支持两种generated column,即virtual generated column和stored generated colum. 一般情况下,都使用virtual generated column,这也是MySQL默认的方式,如果使用stored generated column,即多了一个stored关键字:
CREATE TABLE `tab1` (
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
`c` int(11) GENERATED ALWAYS AS ((`a` + `b`)) VIRTUAL,
`d` int(11) GENERATED ALWAYS AS (((`a` + `b`) + `c`)) STORED NOT NULL,
PRIMARY KEY (`d`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into tab1(a,b) values (1,2),(2,3),(3,4);
查询结果:
mysql> select * from tab1;
+------+------+------+----+
| a | b | c | d |
+------+------+------+----+
| 1 | 2 | 3 | 6 |
| 2 | 3 | 5 | 10 |
| 3 | 4 | 7 | 14 |
+------+------+------+----+
3 rows in set (0.00 sec)
virtual generated column与stored generated column的区别
Pros | Cons | |
STORED | • Fast retrieval | • Require table rebuild at creation • Update table data at INSERT/UPDATE • Require more storage space |
VIRTUAL | • Metadata change only, instant • Faster INSERT/UPDATE, no change to table | • Compute when read, slower retrival |
Indexing Generated Column: STORED vs VIRTUAL
Pros | Cons | |
STORED | • Primary & secondary index • B-TREE, Full text, R-TREE • Independent of SE • Online operation | • Duplication of data in base table and index |
VIRTUAL | • Less storage • Online operation | • Secondary index only • B-TREE only • Require SE support |
JSON Support
支持内建的JSON类型的数据存储,并提供一组JSON函数。使用也比较简单,直接将列类型定义为JSON。
对于JSON类型的数据,在插入或更改时,会进行格式检查,通过新的语法和函数,也可以更方便的操作JSON数据。
和Generated Column相结合,可以对json中的数据进行索引创建,从而索引json中的某个数据段。
Why JSON support in MySQL?
• Convenient object serialization format
• Need to effectively process JSON data
• Provide native support for JavaScript applications
• Seemless integration of relational and schema-less data
• Leverage existing database infrastructure for new applications
New JSON datatype: Supported Types
• ALL native JSON types –Numbers, strings, bool –Objects, arrays
• Extended –Date, time, datetime, timestamp –Other
Indexing JSON data
• Use Functional Indexes, Luke
• STORED and VIRTUAL types are supported
Indexing JSON data: STORED vs VIRTUAL
STORED | VIRTUAL |
–Primary & secondary –BTREE, FTS, GIS –Mixed with fields –Req. table rebuild –Not online | –Secondary only –BTREE only –Mix with virtual column only –No table rebuild –Instant ALTER (Coming soon!) –Faster INSERT |
New functions to handle JSON data
Info | Modify | Create | Get data | Helper |
– JSON_VALID() –JSON_TYPE() –JSON_KEYS() – JSON_LENGTH() – JSON_DEPTH() – JSON_CONTAINS_PATH() – JSON_CONTAINS() | – JSON_REMOVE() – JSON_ARRAY_APPEND() – JSON_SET() – JSON_INSERT() – JSON_ARRAY_INSERT() – JSON_REPLACE() | – JSON_MERGE() – JSON_ARRAY() – JSON_OBJECT() | – JSON_EXTRACT() – JSON_SEARCH() | – JSON_QUOTE() – JSON_UNQUOTE() |
MySQL 5.7.7版本开始InnoDB存储引擎支持JSON格式,原生的JSON格式支持有以下的优势:
• JSON数据有效性检查:BLOB类型无法在数据库层做这样的约束性检查。
• 查询性能的提升:查询不需要遍历所有字符串才能找到数据
• 支持索引:通过虚拟列的功能可以对JSON中的部分数据进行索引
CREATE TABLE `user` (
`uid` int(11) NOT NULL AUTO_INCREMENT,
`data` json DEFAULT NULL,
PRIMARY KEY (`uid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
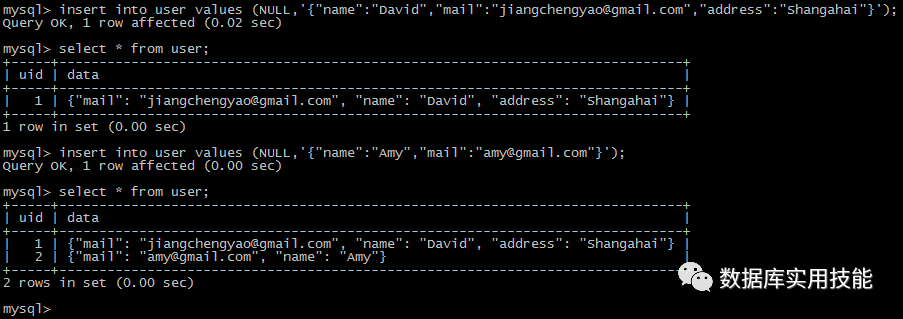
MySQL 5.7的虚拟列功能,通过传统的B+树索引即可实现对JSON格式部分属性的快速查询。使用方法是首先创建该虚拟列,然后在该虚拟列上创建索引
mysql> ALTER TABLE user ADD user_name varchar(128) GENERATED ALWAYS AS (jsn_extract(data,'$.name')) VIRTUAL;
mysql> alter table user add index idx_username (user_name);
mysql> explain select * from user where user_name='"Amy"'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user
partitions: NULL
type: ref
possible_keys: idx_username
key: idx_username
key_len: 131
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
Improved HINTs
在插叙中使用 + …/ 来开启一些优化器或者其他选项,例如BKA, BNL, MRR, ICP, SEMIJOIN, SUBQUERY,MAX_EXECUTION_TIME等等常用HINT
• Introduced new hint syntax *+ ...*/
– Flexibility over optimizer switch, effect individual statement only
– Hints within one statement take precedence over optimizer switch
– Hints apply at different scope levels: global, query block, table, index
• Extended hint support
– BKA, BNL, MRR, ICP, SEMIJOIN, SUBQUERY,MAX_EXECUTION_TIME++
– Disabling prevents optimizer to use it
– Enabling means optimizer is free to use it, but is not forced to use it
Will gradually replace the old hint syntax in upcoming releases


Query Rewrite Plugin
一种新的插件类型,主要解决的问题是在不修改应用的情况下,更改其SQL的行为,例如如果优化器总是为这个SQL选择错误的执行计划,就可以为其加上hint做强制索引选择.
Query rewrite插件支持两种重写方式,一种是在语法解析之前,直接修改SQL字符串,一种是在语法解析之后,通过操控语法解析树来进行重写。
Query Rewrite Plugin
• New pre and post parse query rewrite APIs
– Users can write their own plug-ins
• Provides a post-parse query plugin
– Rewrite problematic queries without the need to make application changes
• Add hints
• Modify join order
• Rewrite rules are defined in a table
• Improve problematic queries from ORMs, third party apps, etc
安装query rewrite plugin:

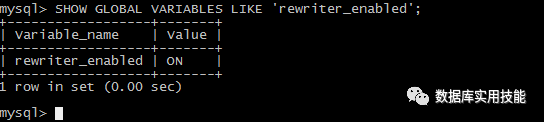
怎么转换:
Pattern is: Replacement is:
SELECT k, id from select k, id from sbtest1 force
sbtest1 where k = ?; Index(primary) where k = ?;
使用plugin前添加rules:

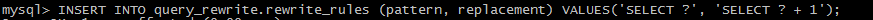
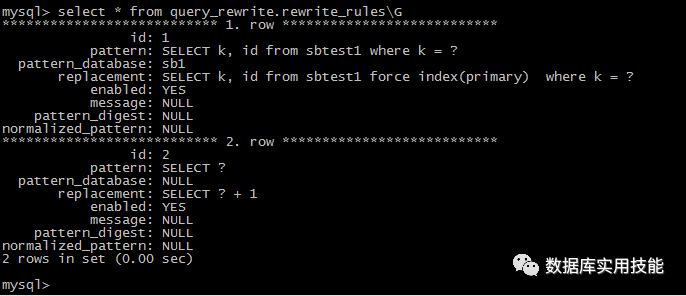
调用存储过程

该存储过程先提交当前的会话的事务(如果有未提交的事务的话),Reset Query Cache.然后调用一个UDF函数load_rewrite_rules将规则加载到插件的内存中。

Rewriter插件已经实现了比较完备的重写功能。
UNION ALL优化
UNION ALL 不再创建临时表,减少磁盘空间和磁盘IO的操作。
Mysql 5.7 | Mysql 5.6 | Mysql 5.5 |
◆Do not materialize in temporary tables unless used for sorting, rows are sent directly to client ◆ Client will receive the first row faster, no need to wait until the last query block is finished ◆ Less memory and disk consumption | ◆ Always materialize results of UNION ALL in temporary tables | ◆ Always materialize results of UNION ALL in temporary tables |
SQL_TEXT:
select count(*) from dubhe01.cpcidea_del_0104 t where t.checkstatus in (1, 2) and t.type in (1,2,3) union all select count(*) from dubhe01.cpcidea_del_0104 t where t.checkstatus in (1, 2) and t.type in (1,2,3) and t.showstatus = '00000001';
5.7 EXPLAIN:

OPTIMIZER_TRACE: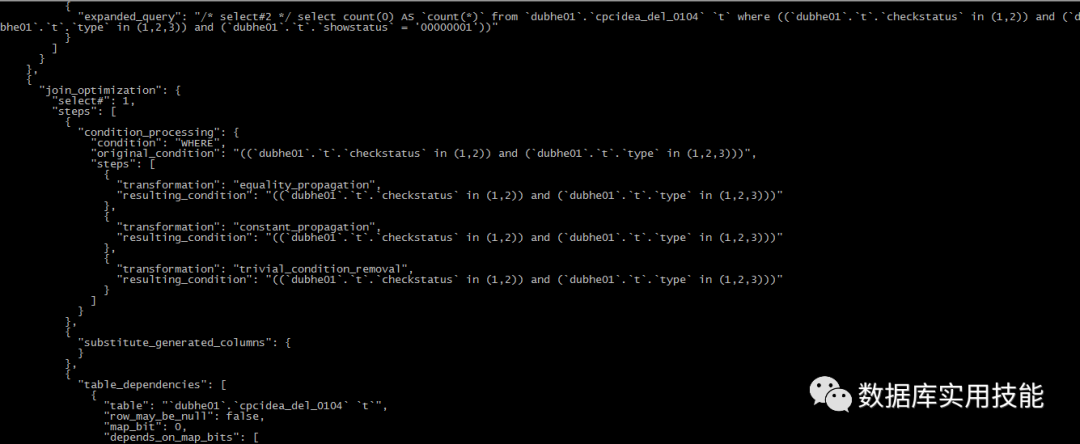
从optimizer_trace中可看出UNION ALL 不再创建临时表,性能明显提升,从而减少磁盘空间和磁盘IO的操作。
Optimizations for IN 优化
使用范围扫描替换“IN queries”使用行值表达式。删除了以前将 WHERE 条件重写进等效 AND/OR 形式的前置条件。
IN表达式优化,在之前的版本中,对于这样的表达式WHERE (a, b) IN ((0, 0), (1, 1)),即时(a,b)上存在索引,也无法使用IN表达式中的值去查询索引,在5.7解决了这个问题,可以使用索引做range scan。
CREATE TABLE t1 (a INT, b INT, c INT, KEY x(a, b));
SELECT a, b FROM t1 WHERE (a, b) IN ((0, 0), (1, 1));
Mysql 5.7 | Mysql 5.6 |
◆IN queries with row value expressions executed using range scans. ◆Explain output: Index/table scans change to range scans | ◆ Certain queries with IN predicates can’t use index scans or range scans even though all the columns in the query are indexed. ◆ Range optimizer ignores lists of rows ◆ Needs to rewrite to de-normalized form |

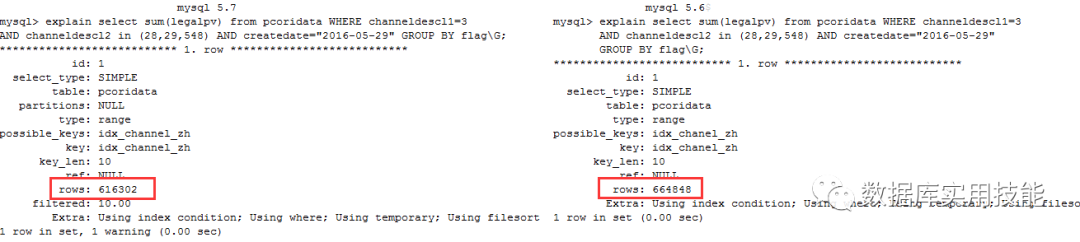
Merging Derived Tables into Outer Query 优化
CREATE VIEW v1 AS (SELECT * FROM t1);
SELECT * FROM v1 JOIN t2 USING (a);
SELECT * FROM (SELECT * FROM t1) AS dt1 JOIN t2 USING (a);
Mysql 5.7 | Mysql 5.6 |
◆Merged into outer query or materialized ◆ Derived table optimized as part of outer query: – Faster queries ◆Derived tables and views are now optimized the same way | ◆ Derived table (subquery in FROM clause) always materialized in temporary table |
Optimizer Refactoring 优化器重构
Mysql 5.7把optimizer阶段的一些工作,提前到了prepare阶段。在分析,优化,和执行的阶段清晰的分离,对优化器代码进行重构,并开发新的面向成本的优化器以支持新的硬件架构,使优化器变得非常快。
另外, FROM 中的子查询(派生表)已经完全物化,而从相同查询表达式创建的视图则有时物化,有时合并到外部查询。
SQL_TEXT:
select t3.* from (select t1.*,t2.gname from students t1 inner join grade t2 on t1.sid=t2.f_sid) t3 where t3.sid > 10005;
5.5,5.6执行计划:

可以看到优化器并没有如想象中的方式去改写语句,在join的准备阶段,优化器把这个SQL解析成为了两个部分,最外层的查询:select #1,和内层的查询select #2,在join的优化阶段,优化器没有下推t3.sid > 10005的条件,而是作为了临时表t3的查询条件保留了下来,5.7执行计划:

从执行计划来看,在MySQL-5.7中,优化器对这种语句进行了改写,如下 trace跟踪内容在最开始的join的准备阶段,优化器合并了t3
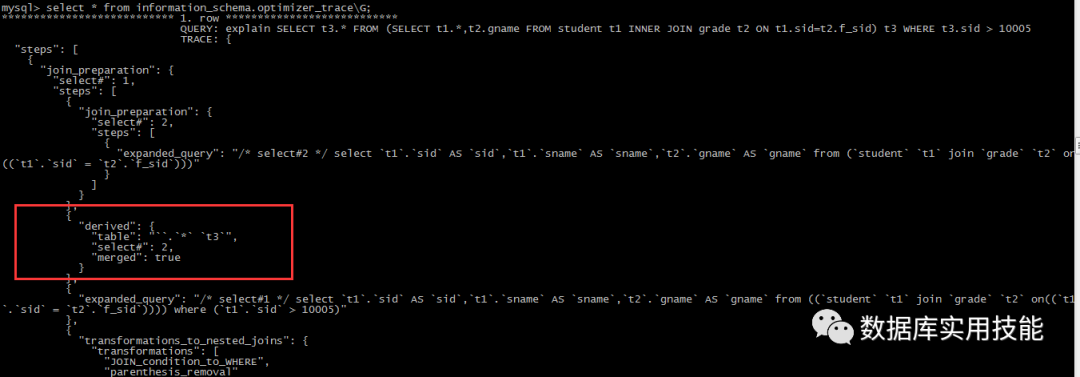
在join的优化阶段,最外围的t3条件已经下推到了t1表中
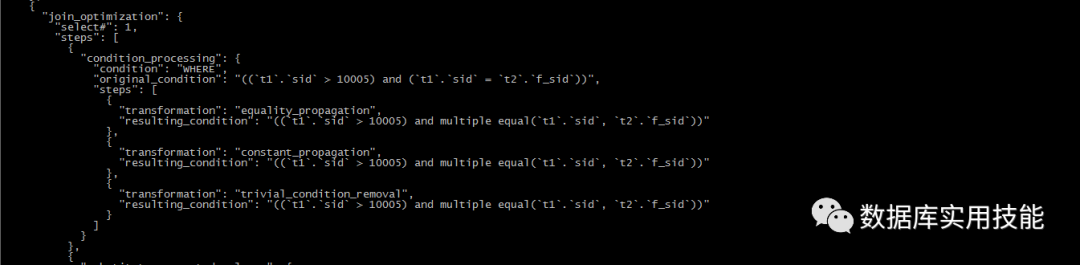
结论:在使用5.5或者5.6之前的版本时,优化器并不会去改写这种类型语句,需要DBA或者开发自行改写。5.7优化器大有改进。
Parser Refactoring 分析器重构
重构 SQL 分析器阶段。由于旧的分析器的复杂语法和自上而下的分析方式而导致缺乏可维护性和可扩展性,因此它已经不能满足要求。
重构 SELECT 声明, SET 声明,INSERT/REPLACE 声明,DELETE 声明 和 UPDATE 声明。
EXPLAIN 改进
可以执行 EXPLAIN FOR CONNECTION 来查看执行中Query得情况,起到运行时profile的作用。比如 EXPLAIN FOR CONNECTION 1024。格式:EXPLAIN [FORMAT=(JSON|TRADITIONAL)] FOR CONNECTION <id>;
在MySQL的5.7.3版本之前,可以使用EXPLAIN EXTENDED语句来获取额外的执行计划信息。从MySQL的5.7.3版本开始,扩展输出是默认启用的,不需要再使用EXTENDED关键字
在MySQL的5.7.3版本之前,EXPLAIN PARTITIONS语句可用于检查涉及分区表的查询。从MySQL的5.7.3版本开始,分区信息是默认启用的,不需要再使用PARTITIONS关键字。
JSON EXPLAIN可以打印整个查询消耗,每张表的消耗,和数据处理数量的方式增强了JSON EXPLAIN输出。可以更容易看出好的执行计划和坏的执行计划。
Work towards a New Cost Model
在 5.7 上为了“条件过滤”(part1 和 part2)和“准确的 InnoDB 统计”,改进 DBT-3 的性能。 使用不同的消耗常量来计算获取在内存中的数据和需要从磁盘中读取的数据的消耗。
优化器主要还是基于 cost model 层面和给用户更多自主优化。
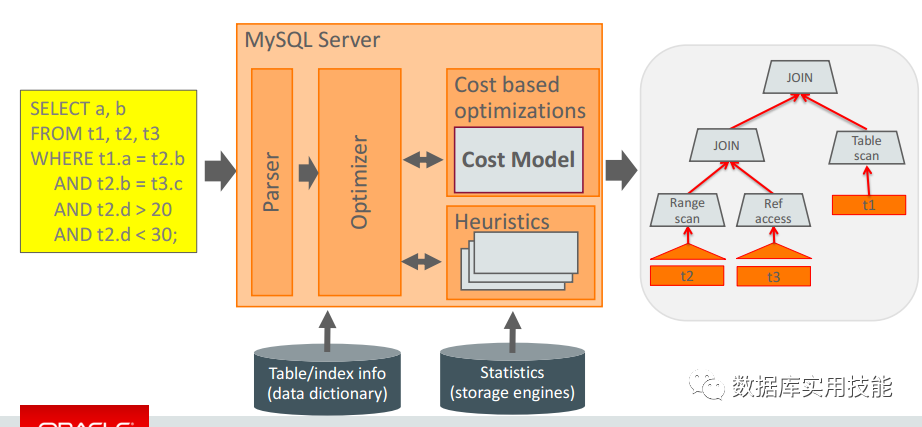
可配置 cost based optimizer,mysql.server_cost 和 mysql.engine_cost。