




介绍
标准化是特征缩放技术之一,它以这样一种方式缩小数据,即依赖于距离和权重的算法(如 KNN、Logistic 回归等)不应受到不均匀缩放数据集的影响,因为如果发生这种情况,那么,模型精度不会很好(实际会证明这一点),另一方面,如果我们以数据点以均值为中心且分布的标准差为1的方式均匀缩放数据,则算法将平等对待权重,给出更相关和更准确的结果。
在本文中,我们不仅会看到如何使用 Python 在机器学习中进行标准缩放,还会看到缩放的效果。比较 分布(缩放前后),以便了解缩放如何影响样本空间,最后但并非最不重要的是,对异常值的影响将向我们展示标准缩放是否有助于消除异常值。
import numpy as np # 线性代数 import pandas as pd # 数据处理 将 matplotlib.pyplot 导入为 plt 将 seaborn 导入为 sns复制
我们正在导入一些必需的库,这将有助于实际实施标准化。
- Numpy:用于求解与线性代数相关的方程。
- Pandas:用于 DataFrame操作和预处理。
- Matplotlib 和 Seaborn:用于数据可视化和查看分布。
df = pd.read_csv('Social_Network_Ads.csv')
df=df.iloc[:,2:]
df.sample(5)复制点击运行查看输出
推论:为了实际实施标准化技术,我们使用社交网络广告代理数据集。请注意,这里我只保留必要的列,以便重点应该放在概念上,而不是理解数据集的复杂性。通过查看一组不同的样本来探索数据集。
训练测试拆分
从 sklearn.model_selection 导入 train_test_split
X_train, X_test, y_train, y_test = train_test_split(df.drop('Purchased', axis=1),
df['已购买'],
test_size=0.3,
随机状态=0)
X_train.shape,X_test.shape复制输出:
((280, 2), (120, 2))复制
推论:在进行标准缩放之前是否进行训练测试拆分总是存在争议,但在我看来,在标准化之前执行此步骤至关重要,就好像我们缩放整个数据一样,然后对于我们的算法,可能没有剩余的测试数据,最终会导致过度拟合。另一方面,如果我们只扩展我们的训练数据,那么我们仍然会有模型看不到的测试数据。
标准定标器
从 sklearn.preprocessing 导入 StandardScaler 缩放器 = 标准缩放器() # 将缩放器拟合到训练集,它将学习参数 scaler.fit(X_train) # 转换训练集和测试集 X_train_scaled = scaler.transform(X_train) X_test_scaled = scaler.transform(X_test)复制
代码分解:
- 在应用标准缩放之前,我们需要从SKLEARN.preprocessing导入StandardScaler模块并启动该对象的实例。
- 然后我们只使用fit函数来训练训练数据集。正如我们所讨论的,这很重要,为了避免过度拟合的情况,我们只使用训练数据集。
- 第三步,暗示标准缩放是转换训练和测试数据集。请注意,这里我们使用的是整个数据集,而不仅仅是训练数据集。
缩放器.mean_复制
输出:
数组([3.78642857e+01, 6.98071429e+04])复制
推论:上面的输出都是关于我们在标准化过程中以均值为中心后得到的两个特征的相应平均值。
X_train_scaled = pd.DataFrame(X_train_scaled, columns=X_train.columns) X_test_scaled = pd.DataFrame(X_test_scaled, columns=X_test.columns)复制
推论:虽然我们仍然有DataFrame形式的 X_train和X_test,但当我们看到X_train_scaled和X_test_scaled时,它会返回 NumPy 数组结构,因为我们首先将其转换为 DataFrame。
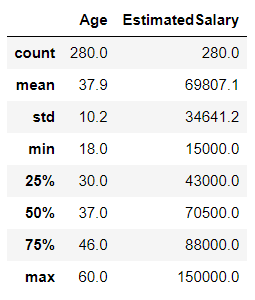
np.round(X_train.describe(), 1)复制
输出:
np.round(X_train_scaled.describe(), 1)复制
输出:
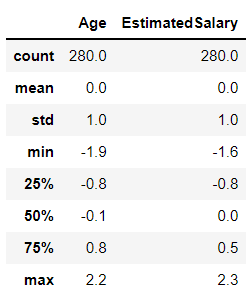
推论:以上两个输出仅用于记录两种情况的平均值(Scaled 和 Pre-Scaled数据)。其中 Pre-Scaled 数据集有一些平均值和标准偏差,而另一方面 Scaled 数据有0 mean和1 standard deviation,如果符合此条件,则意味着我们已成功缩放数据集。
缩放效果
在本文的这一部分中,我们将看到标准化对模型准确性的可能影响,以及这些技术对哪些类型的算法有用。让我们跳进去做一些可视化。
无花果, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12, 5))
ax1.scatter(X_train['Age'], X_train['EstimatedSalary'])
ax1.set_title("缩放前")
ax2.scatter(X_train_scaled['Age'], X_train_scaled['EstimatedSalary'],color='red')
ax2.set_title("缩放后")
plt.show()复制输出:
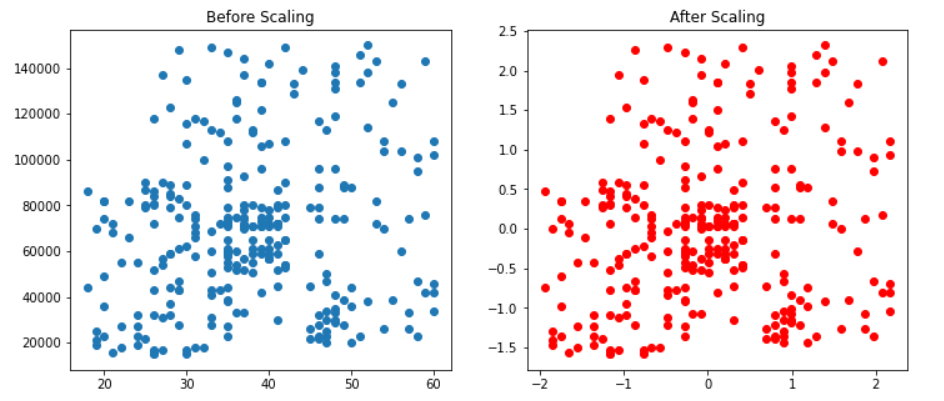
推论: 不要在上面的图中选择红点和蓝点, 因为它们是相同的。真正的区别在于X 和 Y尺度;缩放后,我们可以看到均值发生了变化,现在它处于原点(标准缩放的条件)。
无花果, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12, 5))
# 缩放前
ax1.set_title('缩放前')
sns.kdeplot(X_train['Age'], ax=ax1)
sns.kdeplot(X_train['EstimatedSalary'], ax=ax1)
# 缩放后
ax2.set_title('标准缩放后')
sns.kdeplot(X_train_scaled['Age'], ax=ax2)
sns.kdeplot(X_train_scaled['EstimatedSalary'], ax=ax2)
plt.show()复制输出:
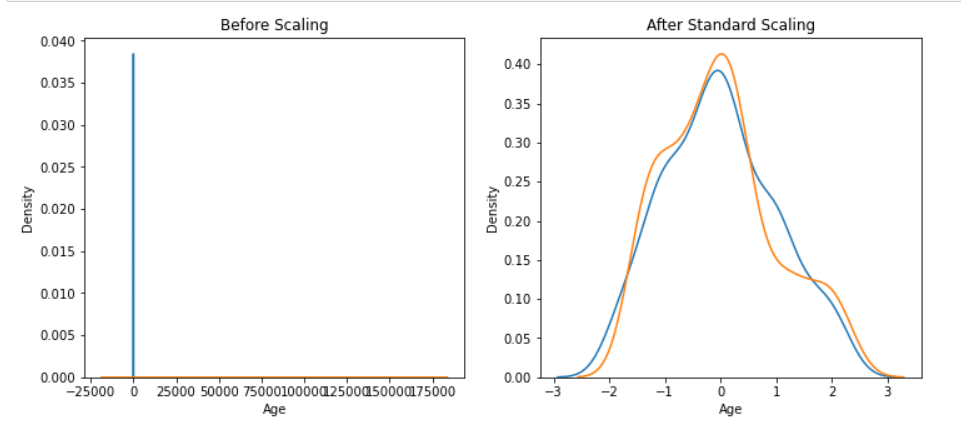
推论:现在查看使用KDE 图对缩放和非缩放数据的概率密度函数。在非缩放数据的情况下,我们只能在 Y 轴上看到 Age,在 X 轴上看到 Estimated Salary 这是因为数据不是均匀缩放的,而是在缩放完成时然后,这两个特征都在样本空间中很好地流动。
分布比较
在这里,我们将比较Age和Estimated Salary分布的分布图,看看标准化过程之后是否会对数据集的分布产生任何影响。
无花果, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12, 5))
# 缩放前
ax1.set_title('缩放前的年龄分布')
sns.kdeplot(X_train['Age'], ax=ax1)
# 缩放后
ax2.set_title('标准缩放后的年龄分布')
sns.kdeplot(X_train_scaled['Age'], ax=ax2)
plt.show()复制输出:
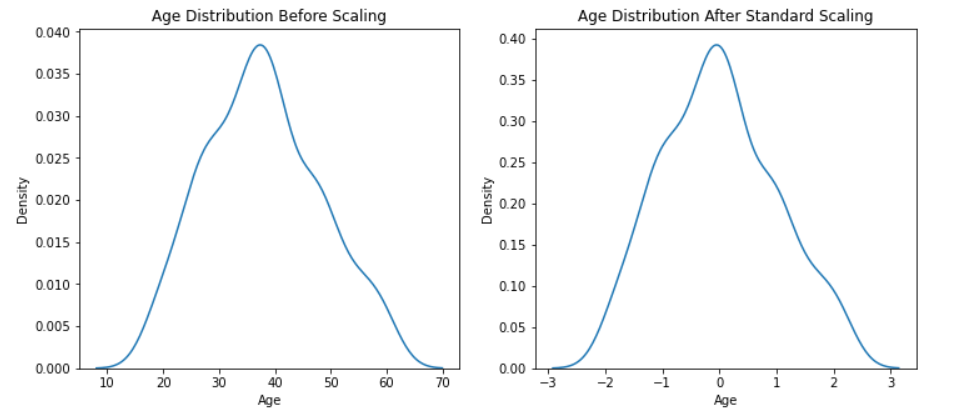
无花果, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12, 5))
# 缩放前
ax1.set_title('扩容前的薪资分配')
sns.kdeplot(X_train['EstimatedSalary'], ax=ax1)
# 缩放后
ax2.set_title('薪酬分配标准比例')
sns.kdeplot(X_train_scaled['EstimatedSalary'], ax=ax2)
plt.show()复制输出:
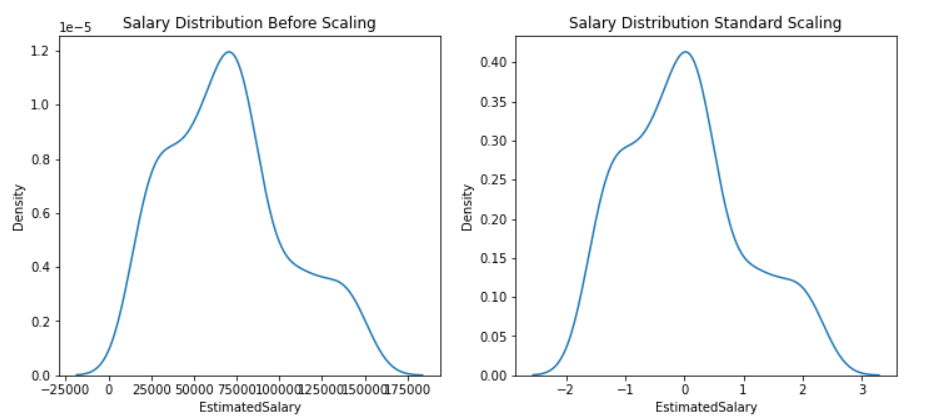
推论:在上面的两个图中,我们已经看到了两种情况下的特征,即缩放之前和缩放之后,并获得了确凿的证据表明标准化不会改变分布,只是数据的规模会改变。
为什么缩放很重要?
到目前为止,我们看到了缩放如何影响数据集的分布和性质。现在是时候看看为什么缩放在模型构建之前很重要,或者它如何提高模型的准确性。除此之外,我们还将看到哪种算法显示效果,我们采用了两种算法,即逻辑回归,其中距离的意义很大,另一种是决策树,与距离。
那么,让我们看看这两种算法将如何对标准缩放做出反应。
从 sklearn.linear_model 导入 LogisticRegression
# 构建逻辑回归实例
lr = 逻辑回归()
lr_scaled = 逻辑回归()
# 模型训练
lr.fit(X_train,y_train)
lr_scaled.fit(X_train_scaled,y_train)
# 存储缩放和预缩放数据的预测
y_pred = lr.predict(X_test)
y_pred_scaled = lr_scaled.predict(X_test_scaled)
从 sklearn.metrics 导入 accuracy_score
print("实际",accuracy_score(y_test,y_pred))
打印(“缩放”,accuracy_score(y_test,y_pred_scaled))复制输出:
实际 0.6583333333333333 缩放 0.8666666666666667复制
推断:在上面的代码中,我们首先导入了Logistic Regression,然后按照与之前相同的每个步骤使用标准 scaler对数据进行了缩放,当我们将Actual data模型的准确性与Scaled 数据进行比较时,我们发现在这种算法的情况下缩放数据非常有帮助,因为准确度从65% 提高到 87%。
从 sklearn.tree 导入 DecisionTreeClassifier
dt = 决策树分类器()
dt_scaled = 决策树分类器()
dt.fit(X_train,y_train)
dt_scaled.fit(X_train_scaled,y_train)
y_pred = dt.predict(X_test)
y_pred_scaled = dt_scaled.predict(X_test_scaled)
print("实际",accuracy_score(y_test,y_pred))
打印(“缩放”,accuracy_score(y_test,y_pred_scaled))复制输出:
实际 0.875 缩放 0.875复制
推论:正如我们在之前的 ML 算法中所做的一样,我们在决策树分类器的情况下所做的,但是在这种情况下,我们可以看到缩放并没有提高模型的准确性,因为缩放对算法很有帮助像KNN、PCA等都依赖于距离。
标准化后异常值的影响
这是我们将在本文课程中讨论的最后一件事,在这里我们将了解标准化后异常值的影响,即标准缩放是否可以去除异常值或者它对它们没有影响。因此,让我们快速找出答案。
df = df.append(pd.DataFrame({'Age':[5,90,95],'EstimatedSalary':[1000,250000,350000],'Purchased':[0,1,1]}),ignore_index =真)
df复制输出:
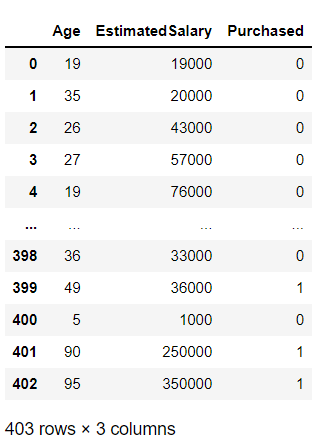
推论: 在上面的代码中,我们追加(添加)了三个新数据点,通过这些数据点的值,我们可以假设它们将是整个样本空间中的异常值。
plt.scatter(df['Age'], df['EstimatedSalary'])复制
输出:
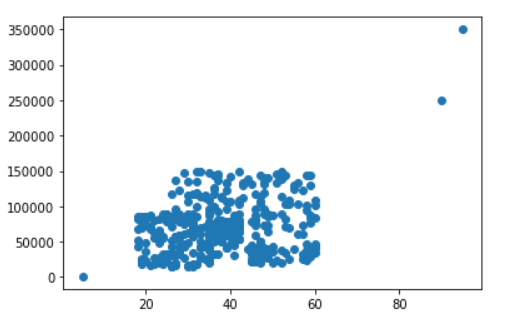
推论:在上图中,我们可以看到三个完全不同的数据点,这肯定是我们刚刚在原始数据集中估算的异常值。
从 sklearn.model_selection 导入 train_test_split
X_train, X_test, y_train, y_test = train_test_split(df.drop('Purchased', axis=1),
df['已购买'],
test_size=0.3,
随机状态=0)
X_train.shape,X_test.shape复制输出:
((282, 2), (121, 2))复制
正如开头提到的关于训练测试拆分的那样,在使用标准缩放 之前遵循这种技术是一种很好的做法(推荐但不是必需的)。
从 sklearn.preprocessing 导入 StandardScaler 缩放器 = 标准缩放器() # 将缩放器拟合到训练集,它将学习参数 scaler.fit(X_train) # 转换训练集和测试集 X_train_scaled = scaler.transform(X_train) X_test_scaled = scaler.transform(X_test)复制
推理:同样,使用StandardScaler在训练集上的拟合函数对数据集进行标准化,并同时转换测试集和训练集。
X_train_scaled = pd.DataFrame(X_train_scaled, columns=X_train.columns) X_test_scaled = pd.DataFrame(X_test_scaled, columns=X_test.columns)复制
无花果, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12, 5))
ax1.scatter(X_train['Age'], X_train['EstimatedSalary'])
ax1.set_title("缩放前")
ax2.scatter(X_train_scaled['Age'], X_train_scaled['EstimatedSalary'],color='red')
ax2.set_title("缩放后")
plt.show()复制输出:
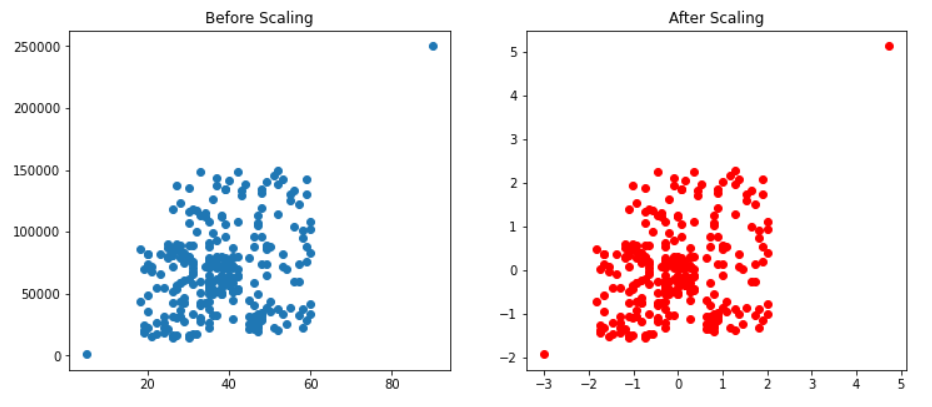
推论:从上面的代码中,我们绘制了缩放前后的刺激,从结果中可以看出,标准缩放不会影响异常值,因为数据点根本没有改变它们的位置。
结论
这是本文的最后一部分,我们将尝试涵盖本文迄今为止讨论的所有内容,但简而言之,以便该部分将起到修订和概念复习的作用,所以让我们开始吧。
- 首先,我们从介绍部分开始,我们讨论了标准缩放,然后我们在应用标准化之前了解了训练测试拆分的重要性。
- 然后我们比较了这两种情况下数据集的分布,即,对于实际和缩放后的数据集,在查看分布之后,我们得到了分布没有改变的确凿证据。
- 然后我们通过比较两种最常用的算法(但背后有不同的数学直觉)了解了为什么缩放很重要。最后一个主题是对离群值的影响,我们看到了图和推断,离群值没有影响。
原文标题:Understand the Concept of Standardization in Machine Learning
原文作者:Aman Preet Gulati
原文链接:https://www.analyticsvidhya.com/blog/2022/10/understand-the-concept-of-standardization-in-machine-learning/



