





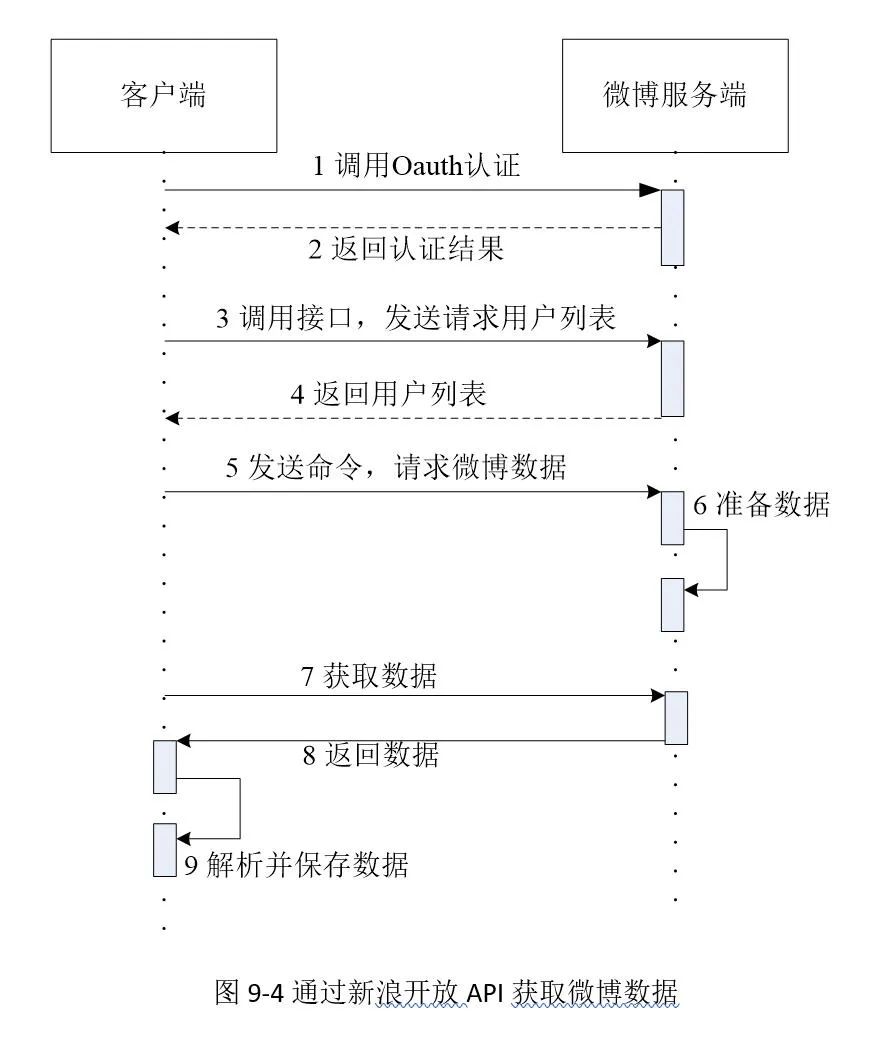
使用微博API进行微博信息获取的基本流程如图9-4所示。在该流程中,首先通过申请到的access token,通过开放平台的认证接口进行OAuth认证。认证通过后,即可通过微博所提供的接口获得各种数据,例如用户数据、博文、关注信息等等。
在微博OAuth2.0实现中,授权服务器在接收到验证授权请求时,会按照OAuth2.0协议对本请求的请求头部、请求参数进行检验,若请求不合法或验证未通过,授权服务器会返回相应的错误信息,包含以下几个参数:
error: 错误码
error_code: 错误的内部编号
error_description: 错误的描述信息
error_url: 可读的网页URI,带有关于错误的信息,用于为终端用户提供与错误有关的额外信息。
如果通过认证,则可以调用各种API。返回的数据按照JSON格式进行封装,最后根据API文档的说明提取所需要的内容。
01
微博API及使用方法
1 微博API介绍
微博API是微博官方提供给开发人员的一组函数调用接口,这是一种在线调用方式,不同于普通语言所提供的函数。这些API能够根据输入的参数返回相应的数据,其范围涵盖用户个人信息、用户的粉丝和关注、用户发布的博文、博文的评论等等。只要携带符合要求的参数向接口发送HTTP请求,接口就会返回所对应的JSON格式数据。
新浪微博提供的API有九大类,即:粉丝服务接口、微博接口、评论接口、用户接口、关系接口、搜索接口、短链接口、公共服务接口和OAuth 2.0授权接口。这些接口的名称及功能如表9-1所示。需要注意的是,新浪微博API会不断升级,最新的接口及功能可以到官方网站查阅:http://open.weibo.com/wiki/%E5%BE%AE%E5%8D%9AAPI。
2 微博API的使用方法
对于每个API,新浪微博规定了其请求参数、返回字段说明、是否需要登录、HTTP请求方式、访问授权限制(包括访问级别、是否频次限制)等关键信息。其中,请求参数是API的输入,而返回字段是API调用的输出结果,一般是以JSON的形式进行封装。HTTP请求方式支持GET和POST两种,访问授权限制则规定了客户端调用API的一些约束条件。
01
例1:采集微博用户个人信息
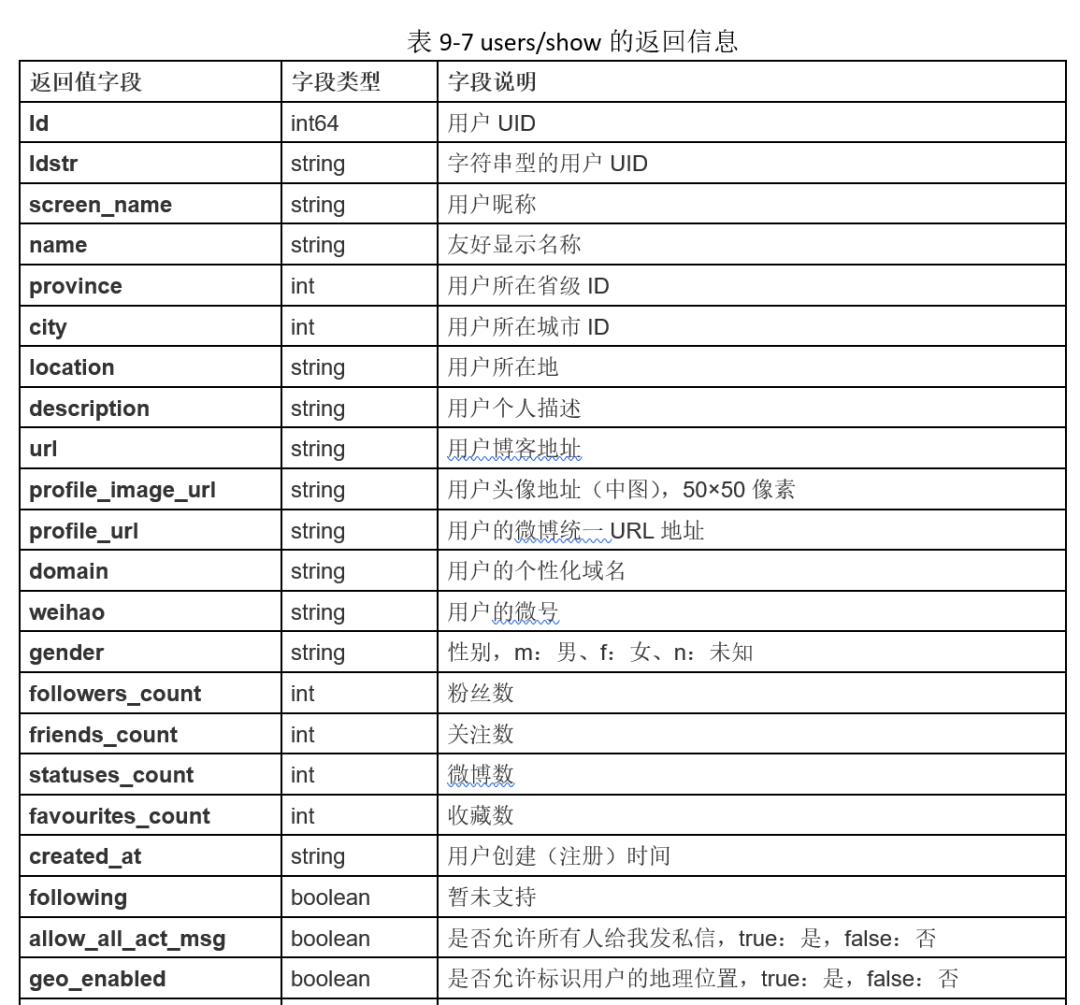
微博用户的个人信息包括用户昵称、简介、粉丝数、关注数、微博数等,通过调用微博开发接口API可以得到这些个人信息数据。该接口为users/show,请求参数如表9-6所示,其中参数uid与screen_name二者必选其一,且只能选其一个。
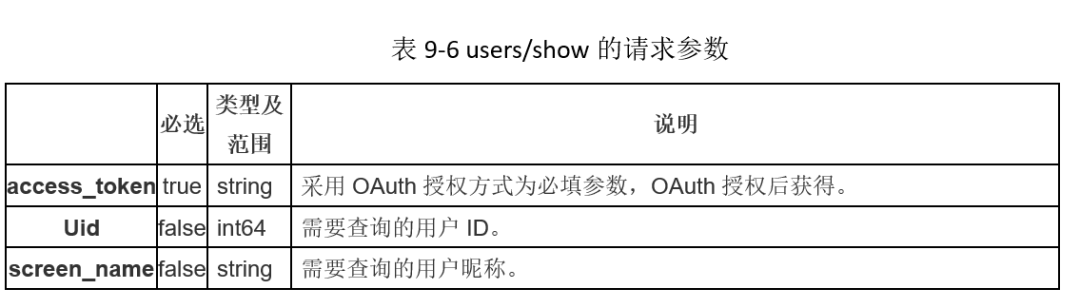
该接口返回的信息包含了用户的昵称、省份、头像、粉丝数等等
在理解接口定义之后,可以使用Python来实现微博个人信息采集。主要过程包括按照请求参数构造、发起请求和结果的提取和转换。具体的程序代码和解释如下。
Prog-12-weiboUserInfo.py
# -*- coding: utf-8 -*- from urllib import parse import requests import json # 调用users/show 接口 def get_pinfo(access_token,uid): # 用户个人信息字典 pinfo_dict = {} url = 'https://api.weibo.com/2/users/show.json' url_dict = {'access_token': access_token, 'uid': uid} url_param = parse.urlencode(url_dict) res=requests.get(url='%s%s%s' % (url, '?', url_param), headers=header_dict) decode_data = json.loads(res.text) pinfo_dict['昵称'] = decode_data['name'] pinfo_dict['简介'] = decode_data['description'] # 性别,转换一下 if decode_data['gender'] == 'f': pinfo_dict['性别'] = '女' elif decode_data['gender'] == 'm': pinfo_dict['性别'] = '男' else: pinfo_dict['性别'] = '未知' # 注册时间 pinfo_dict['注册时间'] = decode_data['created_at'] # 粉丝数 pinfo_dict['粉丝数'] = decode_data['followers_count'] # 关注数 pinfo_dict['关注数'] = decode_data['friends_count'] # 微博数 pinfo_dict['微博数'] = decode_data['statuses_count'] # 收藏数 pinfo_dict['收藏数'] = decode_data['favourites_count'] return pinfo_dict if __name__ == '__main__': header_dict = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko'} # 填写access_token参数 与 uid access_token = '*****************' #通过8.2节方法获得,每个人不一样 uid = '7059060320' pinfo = get_pinfo(access_token,uid) for key, value in pinfo.items(): print('{k}:{v}'.format(k=key, v=value))复制
在http请求中携带access_token和uid参数访问接口,获得一个json格式的返回结果,对json进行解析即可。运行结果如图9-5所示。

03
例2:采集微博博文
使用微博API获取博文主要涉及到两个接口,即statuses/user_timeline/ids和statuses/show。前者用于获取用户发布的微博的ID列表,后者是根据微博ID获得单条微博信息内容,包括文本内容、图片以及评论转发情况等。以下是这两个接口的详细说明。
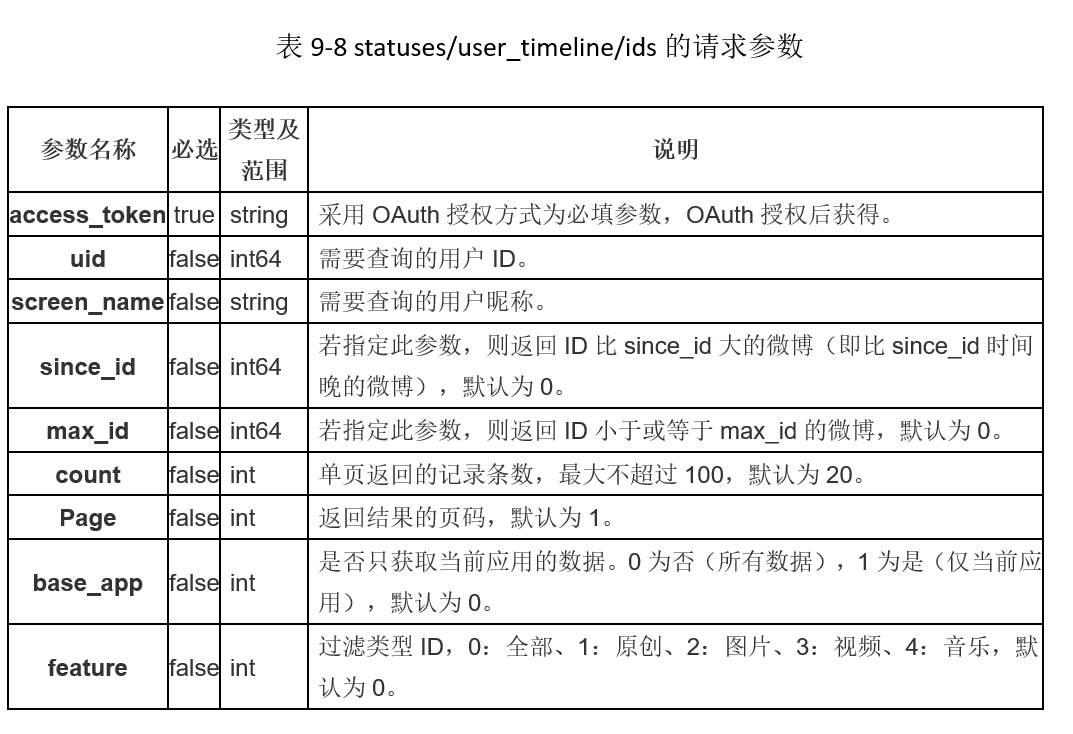
(1) statuses/user_timeline/ids
该接口的请求参数包括采用OAuth授权后获得的access_token,以及所需要检索的微博用户ID,具体定义如表9-8所示,有些参数是可选的,采用默认值。
该接口只返回最新的5条数据,即用户uid所发布的微博ID列表。格式如下,statuses中即为记录列表。
{ "statuses": [ "3382905382185354", "3382905252160340", "3382905235630562", ... ], "previous_cursor": 0, // 暂未支持 "next_cursor": 0, // 暂未支持 "total_number": 16 }复制
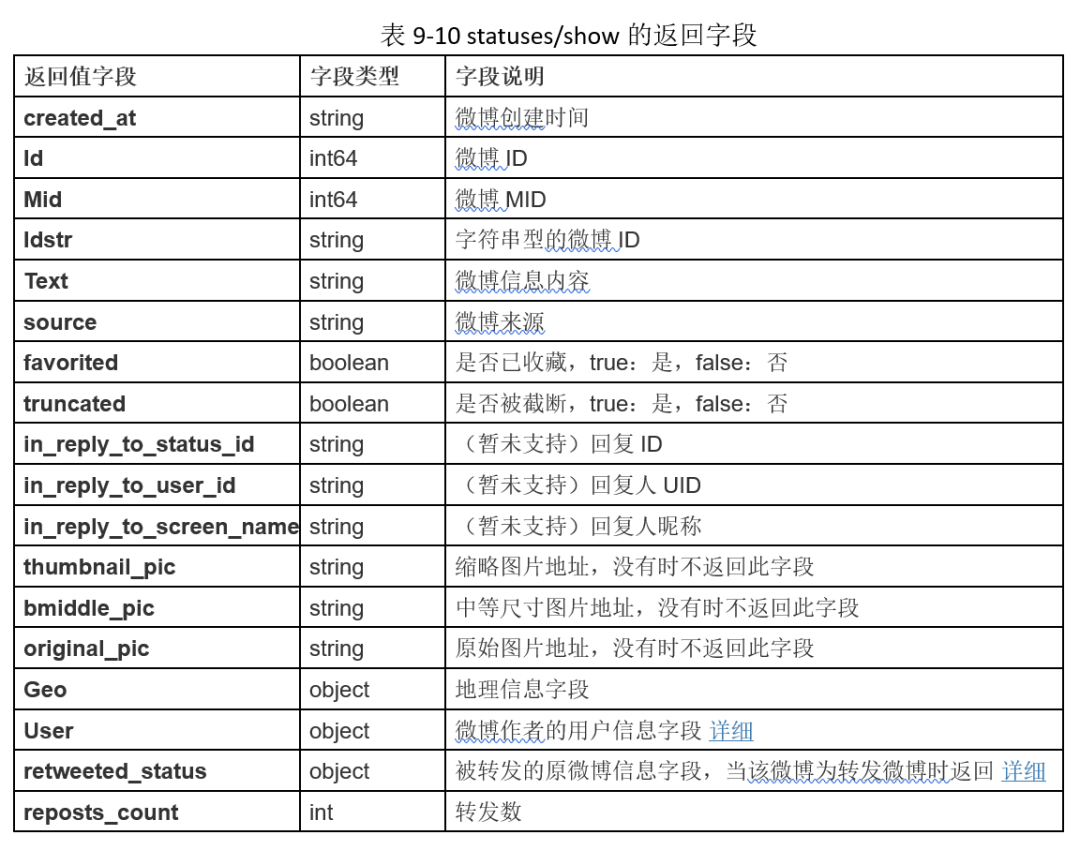
(2) statuses/show
该接口的请求参数也包括采用OAuth授权后获得的access_token,另一个就是微博ID,两个参数均为必选,具体说明如表9-9所示。

该接口返回微博的相关属性值,包括微博创建时间、文本内容等
下面,以statuses/user_timeline/ids接口为例来说明具体的调用和处理方法。
(1)根据接口说明构造正确的http请求。
阅读在线接口说明可知,该接口需要以Get方式请求,必选参数access_token,返回格式为json。其中必选参数access_token来源于OAuth授权,具体创建方法见9.2节。
(2)向服务端发送http请求,并处理返回数据。
在获取了access_token后,就可以使用Python内建模块urllib构建http请求或requests发送请求。可以发现返回的json中包含了该用户的最新5条微博的id,这是因为由于微博API的限制,非商用授权调用微博API中的statuses/user_timeline/ids接口只能获取已授权用户的最新五条博文。
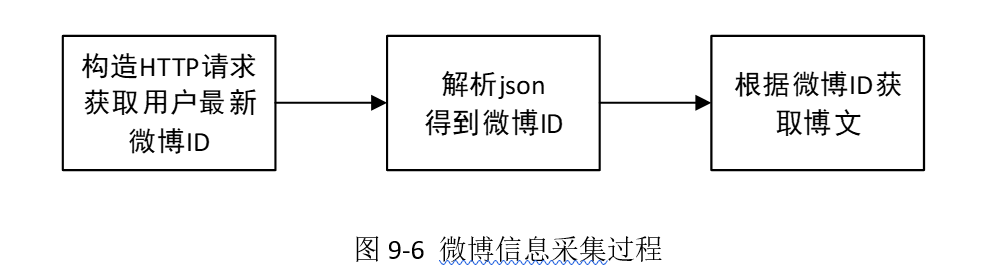
在获得了微博id数据集之后,就逐条记录调用接口statuses/show,该接口会返回对应微博id的博文信息。程序解析json封装的数据,即可实现获取用户博文信息的目标。整个处理过程如图9-6所示。
基于这样的设计思路,使用Python语言可以构造两个函数get_weibo、get_weiboid来获得指定用户的最近博文信息。在程序中需要导入json,具体程序及解释如下。
Prog-13-weiboMsgInfo.py
# -*- coding: utf-8 -*- from urllib import parse import requests import json # 调用statuses/show 接口 def get_weibo(access_token, wid,header_dict): url = 'https://api.weibo.com/2/statuses/show.json' url_dict = {'access_token': access_token, 'id': wid} url_param = parse.urlencode(url_dict) res=requests.get(url='%s%s%s' % (url, '?', url_param), headers=header_dict) decode_data = json.loads(res.text) text = decode_data['text'] if 'retweeted_status' in decode_data: text += ' <---原始微博:'+decode_data['retweeted_status']['text'] return text # 调用statuses/user_timeline/ids 接口 def get_weiboid(access_token,header_dict): url = 'https://api.weibo.com/2/statuses/user_timeline/ids.json' url_dict = {'access_token': access_token} url_param = parse.urlencode(url_dict) #req = request.Request(url='%s%s%s' % (url, '?', url_param), headers=header_dict) #res = request.urlopen(req) #res = res.read() res=requests.get(url='%s%s%s' % (url, '?', url_param), headers=header_dict) decode_data = json.loads(res.text) wid_list = decode_data['statuses'] return wid_list header_dict = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko'} # 填写access_token参数 access_token = '2.00cDGjhHQUpTpCf203bf4e270j8kfF' wid_list = get_weiboid(access_token=access_token, header_dict=header_dict) # 输出博文 for item in wid_list: weibo_text = get_weibo(access_token=access_token, wid=item, header_dict=header_dict) print('微博id:'+str(item)+'--->'+weibo_text+'\n') print('获取结束\n')复制
本例首先使用get_weiboid()函数,调用statuses/user_timeline/ids接口,获取最新5条微博的ID;然后使用get_weibo()函数,调用statuses/user_timeline/ids接口,传入刚刚得到的微博ID,并获得返回的对应ID的博文内容。
运行结果如图9-7所示,显示了作者发的三条博文。

