




好几天没写了,这个问题前几天在群里大家争论过,仅我们小范围大家看法也多少有点不同。(有不同也很正常,这种本来也没有标准定义)。对于HATP是不是一定有用或者说100%做得到。大家还是能达成一致的,就是不可能100%做得到。但是也不是一点也做不到。
TiDB的TiFlash和MySQL的HeatWave都是主从架构来实现行列转换来打通TP到AP的传输。而Oracle是用行列混存来让应用无感知的打通TP到AP的传输。其他数据库我就不一一列举了。以上这样做就是为了不少场景中做分析,能够更加实时而又不对在线交易系统有较大的负荷。比如我上一篇写的实时推荐的文章,其实就是类似的。如果没有实时,那么这个推荐的意义就失去了。
当然HATP只是其中一种,他也不能使用100%的场景。使用场景我个人觉得有类似但是不限于,比如一个系统大约一天是1万-10万的交易量的,那么几乎每10秒或者每秒都有数据进来,这种场景下进行较为实时的查询或者报表是做得到的。但是如果是每秒写入几十万到一百万数据的场景,可能这个时候做一个小时级别的分析也要小时级别,那么由于不能实时出结果,那么实时的意义可能就没有那么大了。所以看业务场景。
还有一种模式就是ETL,ETL能不能做实时?几乎不能。我以前做公安系统做过每分钟将分局数据送到市局,或者市局数据送到省公安厅。这种是基于公安数据落地不变的情况下。可以定时任务搬运。由于间隔一分钟,我认为这个不叫实时。ETL最怕上游改数据,这个时候不好区分。更加要命的是上游删除数据,更加不知道了。每当遇到DDL加字段,彻底完了。可能还要重拿全量数据。我简直不敢想象一个10T的表,这样做一下是什么结果?这种的架构我从网上找的图是这样的。

如果涉及到刚才说的商业数据要改的话,那么图就是这样的
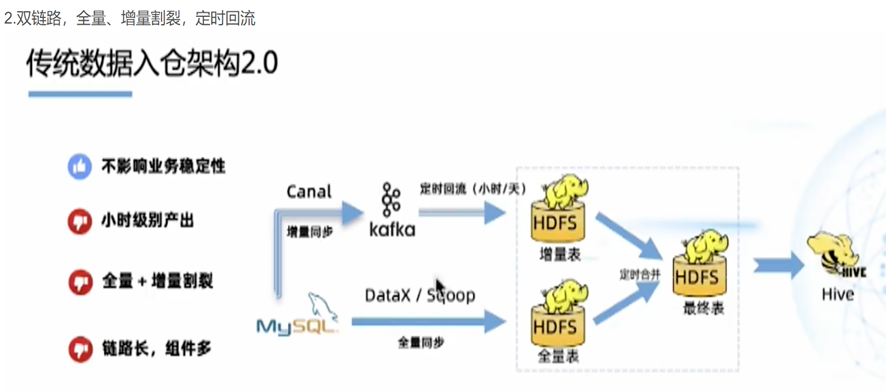
总之看上去很麻烦是吧?其实就是由于Hive这个家伙不支持改嘛。他要是和关系型数据库一样可以update,delete还有ddl,不就都解决了嘛。(话说这样不就是一个标准的关系型数据库嘛,我要hive干什么?)
此外还有一个种就是CDC技术,flinkCDC、TiCDC、OGG等都是这类。能支持多数据源,支持增量且实时的。目前是flinkCDC和OGG。有一次再群里讨论,一个人搞定这两个要什么代价。普遍觉得任意一个搞得定的,都是一个团队的事情,而不是一个人。
情况FlinkCDC和OGG的架构图。他们都是管道类型负责搬运,所以就像搬家公司一样,首先自己有力气,其次搬家两头的路线都要熟悉。就看看图上的各种技术栈图标,这是一个人可以玩的吗?基本不现实。
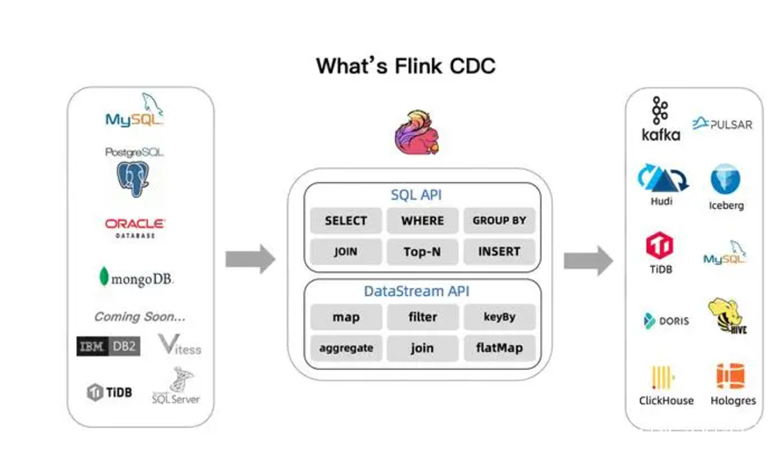
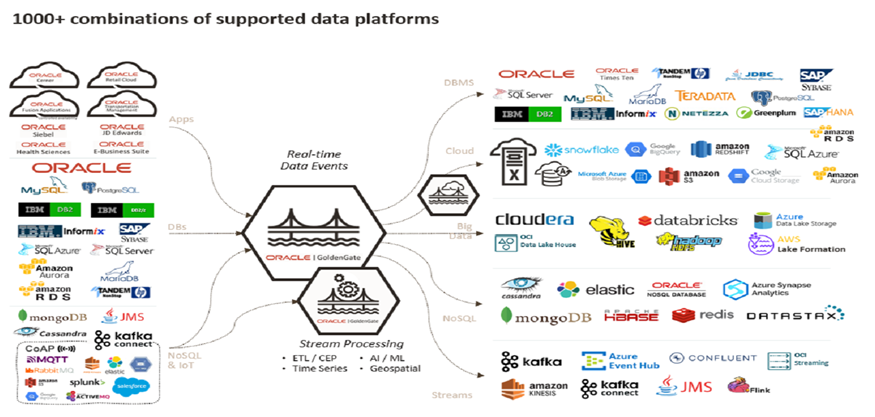
所以在技术实力并不是很出众,人力资源不充足,而且业务量不是大厂的那样上亿用户的场景下,HATP能起到很大作用。
对于大厂来说CDC能做实时,ETL能做离线也挺好。如果非大厂做ETL,性价比太低。(比如1000万数据量,变更几十条或者批量变更几次,CDC或者HATP两种很快就可以完成增量变化,而ETL则做不到)
可能最终也没有个结论,可以结合自己情况定。从我的角度首推HATP(尽管不是100%能解决问题,能解决大部分就行),其次是CDC(没有哪个CDC工具一点问题都没有,可能OGG是问题最少的,但是不熟练也是有问题的)。ETL最后。因为业务普遍诉求,有实时的能解决,为什么要让我等一天?
