




在测试 TiDB sql 兼容性的时候,部分 sql 需要改写,其中有些需要窗口函数来实现。
从 TiDB 官方文档来看,TiDB 基本兼容 MySQL8.0 的窗口函数:
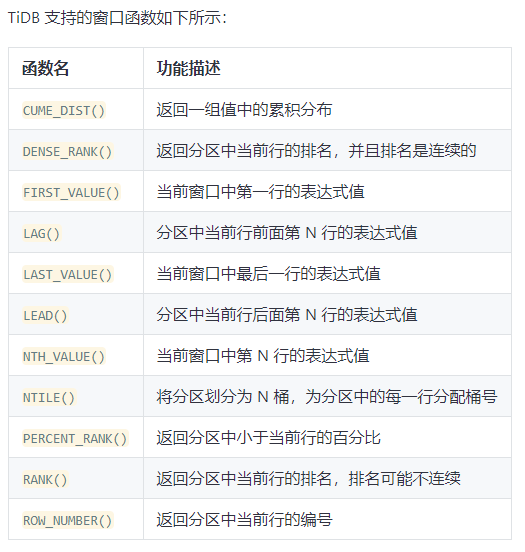
MySQL 窗口函数使用说明:
https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html
下面贴下之前研究 MySQL8.0 窗口函数时的笔记(都是基于Mysql8的):
窗口函数
窗口的概念非常重要,它可以理解为记录集合,窗口函数也就是在满足某种条件的记录集合上执行的特殊函数,对于每条记录都要在此窗口内执行函数,有的函数,随着记录不同,窗口大小都是固定的,这种属于静态窗口;有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。
窗口函数和普通聚合函数也很容易混淆,二者区别如下:
聚合函数是将多条记录聚合为一条;而窗口函数是每条记录都会执行,有几条记录执行完还是几条。
聚合函数也可以用于窗口函数中。
按照功能划分,可以把MySQL支持的窗口函数分为如下几类:
序号函数:row_number()/rank()/dense_rank()
分布函数:percent_rank()/cume_dist()
前后函数:lag()/lead()
头尾函数:first_val()/last_val()
其他函数:nth_value()/nfile()
窗口函数的使用
窗口函数语法如下:
函数名([expr]) over子句复制
over是关键字,用来指定函数执行的窗口范围,如果后面括号中什么都不写,则意味着窗口包含满足where条件的所有行,窗口函数基于所有行进行计算。其中,有四种语法支持设置窗口:
1. window_name
给窗口指定一个别名,如果SQL中涉及的窗口较多,采用别名可以看起来更清晰易读。
select * from
(
select row_number()over(partition by user_name order by amount desc) as row_num,
order_id,user_name,fund_name,amount,sell_time
from fund_order
) t ;复制
改写成以下格式,会使冗长的 sql 显得更清晰易读:
select * from
(
select row_number()over w as row_num,
order_id,user_name,fund_name,amount,sell_time
from fund_order
WINDOW w AS (partition by user_name order by amount desc)
) t ;复制
2. partition子句
窗口按照那些字段进行分组,窗口函数在不同的分组上分别执行。上面的例子就按照 user_name 进行了分组。在每个 user_name 上,按照 order by 的顺序分别生成从1开始的顺序编号。
3. order by子句
按照哪些字段进行排序,窗口函数将按照排序后的记录顺序进行编号。可以和 partition 子句配合使用,也可以单独使用。上例中二者同时使用,如果没有 partition 子句,则会按照所有用户的订单金额排序来生成序号。
4. frame子句
frame是当前分区的一个子集,在分区里面再进一步细分窗口,子句用来定义子集的规则,通常用来作为滑动窗口使用。
frame_unit {<frame_start>|<frame_between>}复制
frame_unit有两种,分别是 ROWS 和 RANGE,由 ROWS 定义的 frame 是由开始和结束位置的行确定的,由 RANGE 定义的 frame 由在某个值区间的行确定。
基于行 ROW:
通常使用 BETWEEN frame_start AND frame_end 语法来表示行范围,frame_start和frame_end 可以支持如下关键字,来确定不同的动态行记录:
CURRENT ROW 边界是当前行,一般和其他范围关键字一起使用
UNBOUNDED PRECEDING 边界是分区中的第一行
UNBOUNDED FOLLOWING 边界是分区中的最后一行
expr PRECEDING 当前行之前的expr(数字或表达式)行
expr FOLLOWING 当前行之后的expr(数字或表达式)行
比如,下面都是合法的范围:
rows BETWEEN 1 PRECEDING AND 1 FOLLOWING 窗口范围是当前行、前一行、后一行一共三行记录。
rows UNBOUNDED FOLLOWING 窗口范围是当前行到分区中的最后一行。
rows BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 窗口范围是当前分区中所有行,等同于不写。复制基于范围 RANGE:
和基于行类似,但有些范围不是直接可以用行数来表示的,比如希望窗口范围是一周前的订单开始,截止到当前行,则无法使用 rows 来直接表示,此时就可以使用范围来表示窗口:INTERVAL 7 DAY PRECEDING。Linux 中常见的最近1分钟、5分钟负载是一个典型的应用场景。
如果为 frame_definition 在OVER子句中指定,则 MySQL 默认使用以下框架:
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW复制
序号函数:row_number()/rank()/dense_rank()
用途:显示分区中的当前行号
使用场景:查询每个用户购买基金金额最高的前三个订单
mysql> select * from
-> (
-> select
-> row_number()over(partition by user_name order by amount desc)as row_num,
-> order_id,user_name,fund_name,amount,sell_time
-> from fund_order
-> ) t where row_num<=3 ;
+---------+----------+-----------+-----------+--------+------------+
| row_num | order_id | user_name | fund_name | amount | sell_time |
+---------+----------+-----------+-----------+--------+------------+
| 1 | 6 | 张三 | 基金D | 4000 | 2020-03-19 |
| 2 | 5 | 张三 | 基金C | 3000 | 2020-03-18 |
| 3 | 4 | 张三 | 基金B | 2000 | 2020-03-17 |
| 1 | 7 | 李四 | 基金B | 10000 | 2020-03-18 |
| 2 | 8 | 李四 | 基金C | 10000 | 2020-03-19 |
| 3 | 11 | 李四 | 基金B | 8000 | 2020-03-20 |
| 1 | 10 | 王五 | 基金C | 6000 | 2020-03-19 |
| 2 | 9 | 王五 | 基金B | 4000 | 2020-03-18 |
| 3 | 3 | 王五 | 基金A | 2000 | 2020-03-17 |
+---------+----------+-----------+-----------+--------+------------+
9 rows in set (0.00 sec)复制
通过使用 ROW_NUMBER() 函数按照用户进行分组并按照订单日期进行由大到小排序,最后查找每组中序号 <=3 的记录。
rank 和 dense_rank ,这两个函数和row_number()非常类似,只是在出现重复值时处理逻辑有所不同。
mysql> select * from
-> (
-> select
-> row_number()over(partition by user_name order by amount desc)as row_num,
-> rank() over(partition by user_name order by amount desc)as rank_row_num2,
-> dense_rank() over(partition by user_name order by amount desc)as dense_rank_row_num3,
-> order_id,user_name,fund_name,amount,sell_time
-> from fund_order
-> ) t where row_num<=3 ;
+---------+---------------+---------------------+----------+-----------+-----------+--------+------------+
| row_num | rank_row_num2 | dense_rank_row_num3 | order_id | user_name | fund_name | amount | sell_time |
+---------+---------------+---------------------+----------+-----------+-----------+--------+------------+
| 1 | 1 | 1 | 6 | 张三 | 基金D | 4000 | 2020-03-19 |
| 2 | 2 | 2 | 5 | 张三 | 基金C | 3000 | 2020-03-18 |
| 3 | 3 | 3 | 4 | 张三 | 基金B | 2000 | 2020-03-17 |
| 1 | 1 | 1 | 7 | 李四 | 基金B | 10000 | 2020-03-18 |
| 2 | 1 | 1 | 8 | 李四 | 基金C | 10000 | 2020-03-19 |
| 3 | 3 | 2 | 11 | 李四 | 基金B | 8000 | 2020-03-20 |
| 1 | 1 | 1 | 10 | 王五 | 基金C | 6000 | 2020-03-19 |
| 2 | 2 | 2 | 9 | 王五 | 基金B | 4000 | 2020-03-18 |
| 3 | 3 | 3 | 3 | 王五 | 基金A | 2000 | 2020-03-17 |
+---------+---------------+---------------------+----------+-----------+-----------+--------+------------+
9 rows in set (0.00 sec)复制
row_number() 在 amount 都是 10000 的两条记录上随机排序,但序号按照 1、2 递增,后面amount为8000的的序号继续递增为3,中间不会产生序号间隙。
rank()/dense_rank() 则把 amount 为 8000 的两条记录序号都设置为2,但后续amount为600的需要则分别设置为3(rank)和2(dense_rank)。
综上,rank()会产生序号相同的记录,同时可能产生序号间隙;而dense_rank()也会产生序号相同的记录,但不会产生序号间隙。
分布函数 percent_rank()/cume_dist()
mysql> select * from
-> (
-> select
-> rank() over(partition by user_name order by amount desc) as row_num,
-> percent_rank() over( order by amount desc) as percent,
-> cume_dist() over( order by amount desc) as cume,
-> order_id,user_name,fund_name,amount,sell_time
-> from fund_order
-> ) t ;
+---------+---------+---------------------+----------+-----------+-----------+--------+------------+
| row_num | percent | cume | order_id | user_name | fund_name | amount | sell_time |
+---------+---------+---------------------+----------+-----------+-----------+--------+------------+
| 1 | 0 | 0.18181818181818182 | 7 | 李四 | 基金B | 10000 | 2020-03-18 |
| 1 | 0 | 0.18181818181818182 | 8 | 李四 | 基金C | 10000 | 2020-03-19 |
| 3 | 0.2 | 0.2727272727272727 | 11 | 李四 | 基金B | 8000 | 2020-03-20 |
| 1 | 0.3 | 0.36363636363636365 | 10 | 王五 | 基金C | 6000 | 2020-03-19 |
| 4 | 0.4 | 0.45454545454545453 | 2 | 李四 | 基金A | 5000 | 2020-03-17 |
| 1 | 0.5 | 0.6363636363636364 | 6 | 张三 | 基金D | 4000 | 2020-03-19 |
| 2 | 0.5 | 0.6363636363636364 | 9 | 王五 | 基金B | 4000 | 2020-03-18 |
| 2 | 0.7 | 0.7272727272727273 | 5 | 张三 | 基金C | 3000 | 2020-03-18 |
| 3 | 0.8 | 0.9090909090909091 | 4 | 张三 | 基金B | 2000 | 2020-03-17 |
| 3 | 0.8 | 0.9090909090909091 | 3 | 王五 | 基金A | 2000 | 2020-03-17 |
| 4 | 1 | 1 | 1 | 张三 | 基金A | 1000 | 2020-03-17 |
+---------+---------+---------------------+----------+-----------+-----------+--------+------------+
11 rows in set (0.00 sec)复制
cume_dist():
一共有 11 条记录,当 amount=10000 时,大于等于 10000 的值共有2个 ,所以其 cume_dist() 值为 2/11 约等于0.1818。当 amount=8000 时,大于等于 8000 的值共有3个,cume_dist() 值为 3/11 约等于 0.2727,以此类推。
percent_rank()
当 amount=10000 时,大于 10000 的记录数为0,所以 percent_rank() 为0。当 amount=8000 时,大于 8000 的记录数有两个,所以 percent_rank()=2/10= 0.2。以此类推知道 amount=1000,10个数都比它大,percent_rank() 为1。
前后函数 lead(n)/lag(n)
分区中位于当前行前 n 行(lead)/ 后 n 行(lag) 的记录值,可以用来查询上一个订单距离当前订单的时间间隔:
mysql> select order_id,user_name,amount,sell_time, last_date,datediff(sell_time,last_date)as diff
-> from
-> (
-> select
-> order_id,user_name,amount,sell_time,
-> lag(sell_time,1) over w as last_date
-> from fund_order
-> WINDOW w AS (partition by user_name order by sell_time )
-> ) t;
+----------+-----------+--------+------------+------------+------+
| order_id | user_name | amount | sell_time | last_date | diff |
+----------+-----------+--------+------------+------------+------+
| 1 | 张三 | 1000 | 2020-03-17 | NULL | NULL |
| 4 | 张三 | 2000 | 2020-03-17 | 2020-03-17 | 0 |
| 5 | 张三 | 3000 | 2020-03-18 | 2020-03-17 | 1 |
| 6 | 张三 | 4000 | 2020-03-19 | 2020-03-18 | 1 |
| 2 | 李四 | 5000 | 2020-03-17 | NULL | NULL |
| 7 | 李四 | 10000 | 2020-03-18 | 2020-03-17 | 1 |
| 8 | 李四 | 10000 | 2020-03-19 | 2020-03-18 | 1 |
| 11 | 李四 | 8000 | 2020-03-20 | 2020-03-19 | 1 |
| 3 | 王五 | 2000 | 2020-03-17 | NULL | NULL |
| 9 | 王五 | 4000 | 2020-03-18 | 2020-03-17 | 1 |
| 10 | 王五 | 6000 | 2020-03-19 | 2020-03-18 | 1 |
+----------+-----------+--------+------------+------------+------+
11 rows in set (0.00 sec)复制
内层 SQL 先通过 lag 函数得到上一次订单的日期,外层SQL再将本次订单和上次订单日期做差得到时间间隔diff。last_date 为 null 说明该用户的该笔订单时间最早。
头尾函数 first_val(expr)/last_val(expr)
得到分区中的第一个/最后一个指定参数的值,我们可以查询截止到当前订单,按照日期排序第一个订单和最后一个订单的订单金额:
mysql> select*
-> from
-> (
-> select
-> order_id,user_name,amount,sell_time,
-> first_value(amount) over w as first_amount,
-> last_value(amount) over w as last_amount
-> from fund_order
-> WINDOW w AS (partition by user_name order by sell_time )
-> ) t;
+----------+-----------+--------+------------+--------------+-------------+
| order_id | user_name | amount | sell_time | first_amount | last_amount |
+----------+-----------+--------+------------+--------------+-------------+
| 1 | 张三 | 1000 | 2020-03-17 | 1000 | 2000 |
| 4 | 张三 | 2000 | 2020-03-17 | 1000 | 2000 |
| 5 | 张三 | 3000 | 2020-03-18 | 1000 | 3000 |
| 6 | 张三 | 4000 | 2020-03-19 | 1000 | 4000 |
| 2 | 李四 | 5000 | 2020-03-17 | 5000 | 5000 |
| 7 | 李四 | 10000 | 2020-03-18 | 5000 | 10000 |
| 8 | 李四 | 10000 | 2020-03-19 | 5000 | 10000 |
| 11 | 李四 | 8000 | 2020-03-20 | 5000 | 8000 |
| 3 | 王五 | 2000 | 2020-03-17 | 2000 | 2000 |
| 9 | 王五 | 4000 | 2020-03-18 | 2000 | 4000 |
| 10 | 王五 | 6000 | 2020-03-19 | 2000 | 6000 |
+----------+-----------+--------+------------+--------------+-------------+
11 rows in set (0.00 sec)复制
order_id=9 “王五”的订单,截止这单购买时,“王五”所有的订单,最高的买了4000元,最低的买了2000元基金。
其他函数 nth_value(expr,n)/nfile(n)
返回窗口中第N个expr的值,expr可以是表达式,也可以是列名。可以用来查询每个用户订单中显示该用户金额排名第二和第三的订单金额:
mysql> select*
-> from
-> (
-> select
-> order_id,user_name,amount,sell_time,
-> nth_value(amount,2) over w as second_amount,
-> nth_value(amount,3) over w as third_amount
-> from fund_order
-> WINDOW w AS (partition by user_name order by amount )
-> ) t;
+----------+-----------+--------+------------+---------------+--------------+
| order_id | user_name | amount | sell_time | second_amount | third_amount |
+----------+-----------+--------+------------+---------------+--------------+
| 1 | 张三 | 1000 | 2020-03-17 | NULL | NULL |
| 4 | 张三 | 2000 | 2020-03-17 | 2000 | NULL |
| 5 | 张三 | 3000 | 2020-03-18 | 2000 | 3000 |
| 6 | 张三 | 4000 | 2020-03-19 | 2000 | 3000 |
| 2 | 李四 | 5000 | 2020-03-17 | NULL | NULL |
| 11 | 李四 | 8000 | 2020-03-20 | 8000 | NULL |
| 7 | 李四 | 10000 | 2020-03-18 | 8000 | 10000 |
| 8 | 李四 | 10000 | 2020-03-19 | 8000 | 10000 |
| 3 | 王五 | 2000 | 2020-03-17 | NULL | NULL |
| 9 | 王五 | 4000 | 2020-03-18 | 4000 | NULL |
| 10 | 王五 | 6000 | 2020-03-19 | 4000 | 6000 |
+----------+-----------+--------+------------+---------------+--------------+
11 rows in set (0.01 sec)复制
结果是符合该函数预期的。
分桶 ntile()
将分区中的有序数据分为n个桶,记录桶号,我们将每个用户的订单按照订单金额分成3组:
mysql> select * from
-> (
-> select
-> ntile(3) over w as nf,
-> order_id,user_name,amount,sell_time
-> from fund_order
-> WINDOW w AS (partition by user_name order by amount desc )
-> ) t;
+------+----------+-----------+--------+------------+
| nf | order_id | user_name | amount | sell_time |
+------+----------+-----------+--------+------------+
| 1 | 6 | 张三 | 4000 | 2020-03-19 |
| 1 | 5 | 张三 | 3000 | 2020-03-18 |
| 2 | 4 | 张三 | 2000 | 2020-03-17 |
| 3 | 1 | 张三 | 1000 | 2020-03-17 |
| 1 | 7 | 李四 | 10000 | 2020-03-18 |
| 1 | 8 | 李四 | 10000 | 2020-03-19 |
| 2 | 11 | 李四 | 8000 | 2020-03-20 |
| 3 | 2 | 李四 | 5000 | 2020-03-17 |
| 1 | 10 | 王五 | 6000 | 2020-03-19 |
| 2 | 9 | 王五 | 4000 | 2020-03-18 |
| 3 | 3 | 王五 | 2000 | 2020-03-17 |
+------+----------+-----------+--------+------------+
11 rows in set (0.00 sec)复制
此函数在数据分析中应用较多,比如由于数据量大,需要将数据平均分配到 N 个并行的进程分别计算,此时就可以用 NFILE(N) 对数据进行分组,由于记录数不一定被 N 整除,所以数据不一定完全平均,然后将不同桶号的数据再分配。
聚合函数
在窗口中每条记录动态应用聚合函数(sum/avg/max/min/count),可以动态计算在指定的窗口内的各种聚合函数值。
查询每个用户按照订单id,截止到当前的累计订单金额/平均订单金额/最大订单金额/最小订单金额/订单数?
mysql> select*
-> from
-> (
-> select
-> order_id,user_name,amount,sell_time,
-> sum(amount) over w as sum1,
-> avg(amount) over w as avg1,
-> max(amount) over w as max1,
-> min(amount) over w as min1,
-> count(amount) over w as count1
-> from fund_order
-> WINDOW w AS (partition by user_name order by order_id )
-> ) t;
+----------+-----------+--------+------------+-------+-----------+-------+------+--------+
| order_id | user_name | amount | sell_time | sum1 | avg1 | max1 | min1 | count1 |
+----------+-----------+--------+------------+-------+-----------+-------+------+--------+
| 1 | 张三 | 1000 | 2020-03-17 | 1000 | 1000.0000 | 1000 | 1000 | 1 |
| 4 | 张三 | 2000 | 2020-03-17 | 3000 | 1500.0000 | 2000 | 1000 | 2 |
| 5 | 张三 | 3000 | 2020-03-18 | 6000 | 2000.0000 | 3000 | 1000 | 3 |
| 6 | 张三 | 4000 | 2020-03-19 | 10000 | 2500.0000 | 4000 | 1000 | 4 |
| 2 | 李四 | 5000 | 2020-03-17 | 5000 | 5000.0000 | 5000 | 5000 | 1 |
| 7 | 李四 | 10000 | 2020-03-18 | 15000 | 7500.0000 | 10000 | 5000 | 2 |
| 8 | 李四 | 10000 | 2020-03-19 | 25000 | 8333.3333 | 10000 | 5000 | 3 |
| 11 | 李四 | 8000 | 2020-03-20 | 33000 | 8250.0000 | 10000 | 5000 | 4 |
| 3 | 王五 | 2000 | 2020-03-17 | 2000 | 2000.0000 | 2000 | 2000 | 1 |
| 9 | 王五 | 4000 | 2020-03-18 | 6000 | 3000.0000 | 4000 | 2000 | 2 |
| 10 | 王五 | 6000 | 2020-03-19 | 12000 | 4000.0000 | 6000 | 2000 | 3 |
+----------+-----------+--------+------------+-------+-----------+-------+------+--------+复制
评论

 0 点赞
0 点赞