




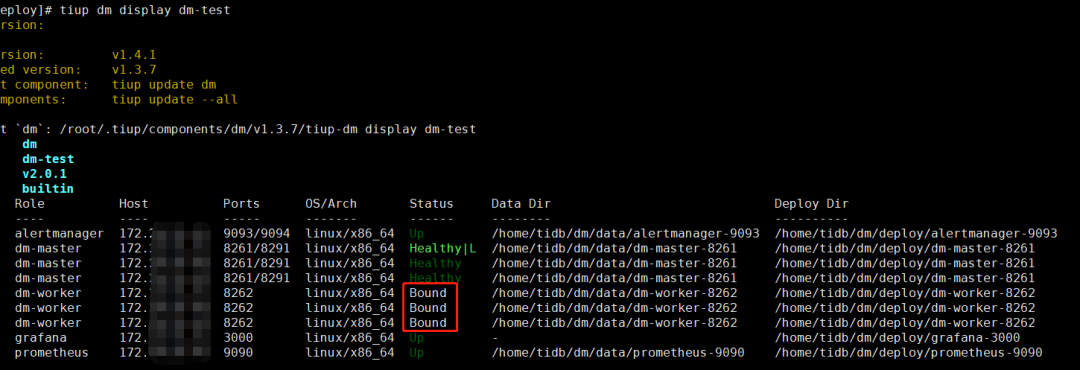
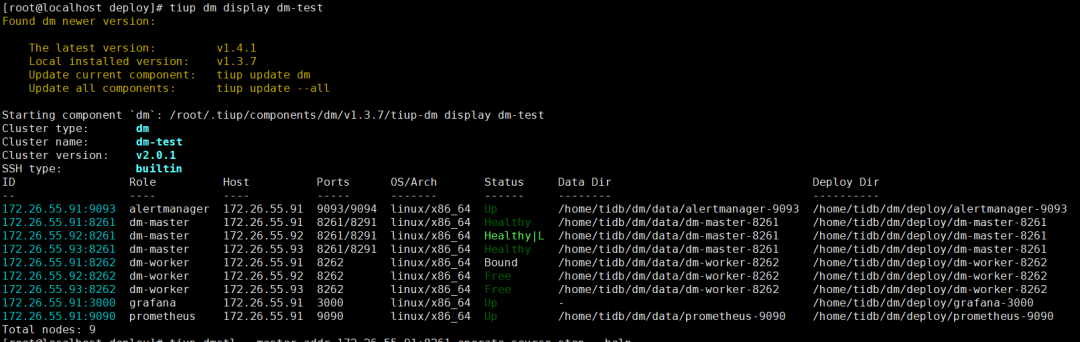
dm-worker 均处于 Bound 状态
问题描述
在迁移测试库的过程中,每次重置同步工作的时候,采用了以下命令:
tiup dmctl --master-addr 172.26.55.91:8261 operate-source create source1.yaml复制
每次 create 一下,然后就占用一个 dm-work,最终三个 worker 都处于 Bound 状态:
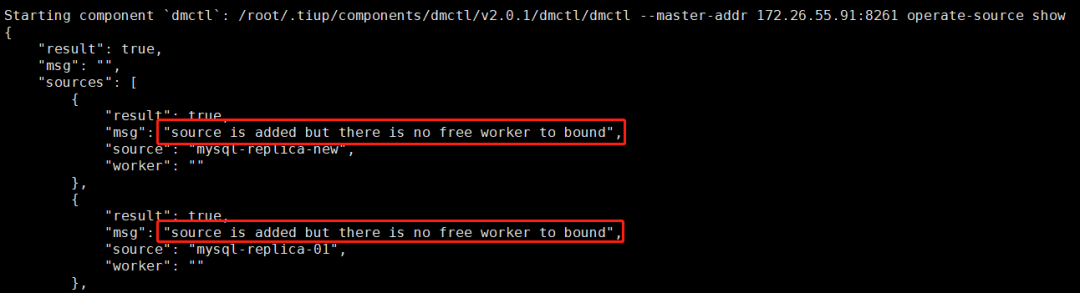
再次 operate-source create ,会报以下错误:
解决方案
1. 查看 source 和 worker 关系:
tiup dmctl --master-addr 172.26.55.91:8261 operate-source show复制
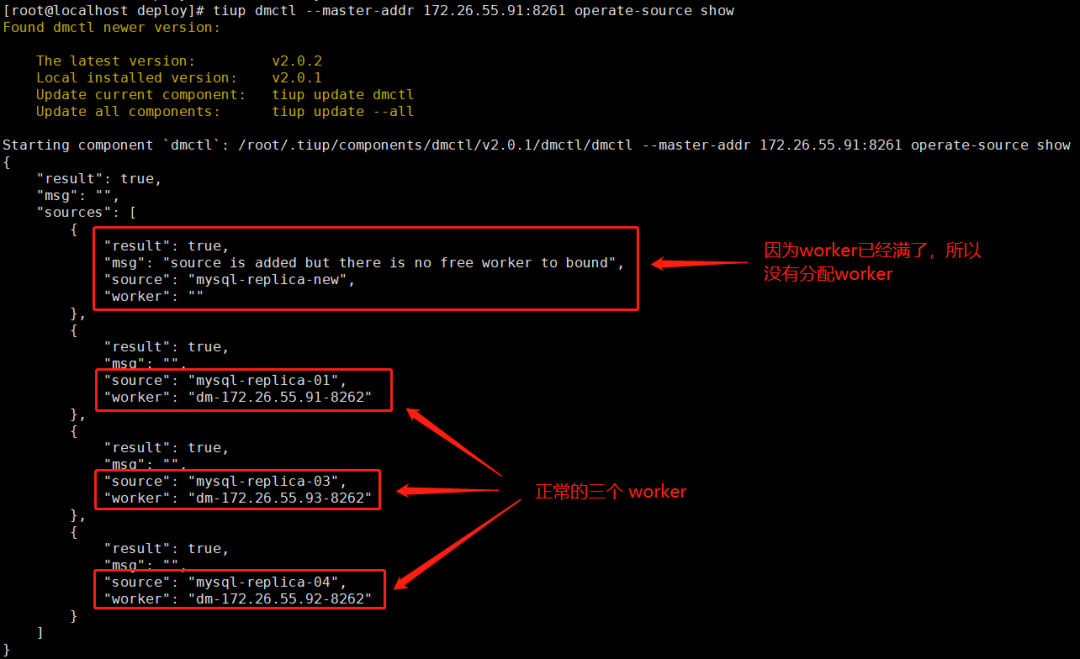
如果先把 mysql-replica-new 加入worker,需要移除 mysql-replica-01、mysql-replica-03 和mysql-replica-04 其中的一个。
2. 配置需要移除的 worker 信息:
假如 mysql-replica-01 已不再使用,去配置文件里修改需要移除的 source_uid
vim source1.yaml
source-id: "mysql-replica-01" # 这里配置需要移除的名字,对应信息可以用 operate-source show 命令查看
enable-gtid: false
from:
host: "172.26.55.21"
user: "root"
password: "XXXXXX"
port: 3306复制
3. 关闭 DM 任务:
tiup dmctl --master-addr 172.26.55.91:8261 stop-task test复制
4. 移除不需要的 source:
tiup dmctl --master-addr 172.26.55.91:8261 operate-source stop source1.yaml
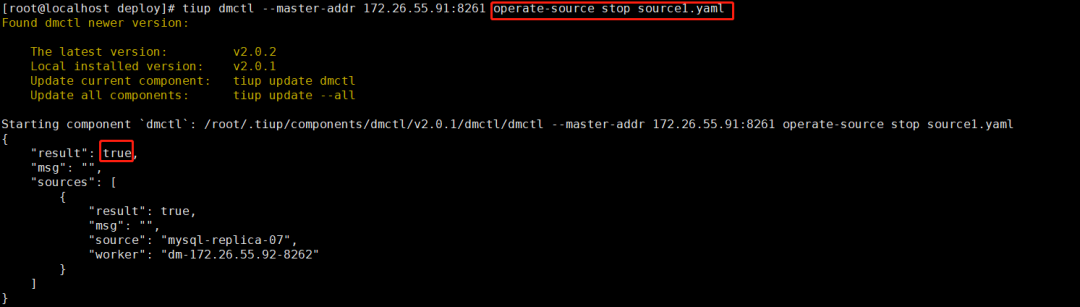
之前图片被刷,这里删除的是 mysql-replica-07。原理步骤其实一样,正常删除的话 result 会返回 true
5. 检查 DM 最新状态:
把不需要的同步源都删了,只保留需要的那个:
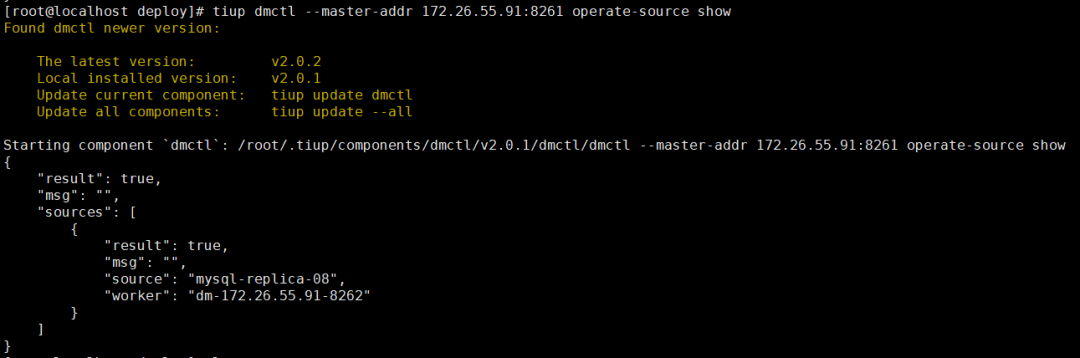
只有一个源的话,就只有一个 worker 处于 Bound 状态,其他都处于 Free:
6. 查看同步进度
tiup dmctl --master-addr 172.26.55.91:8261 query-status test复制
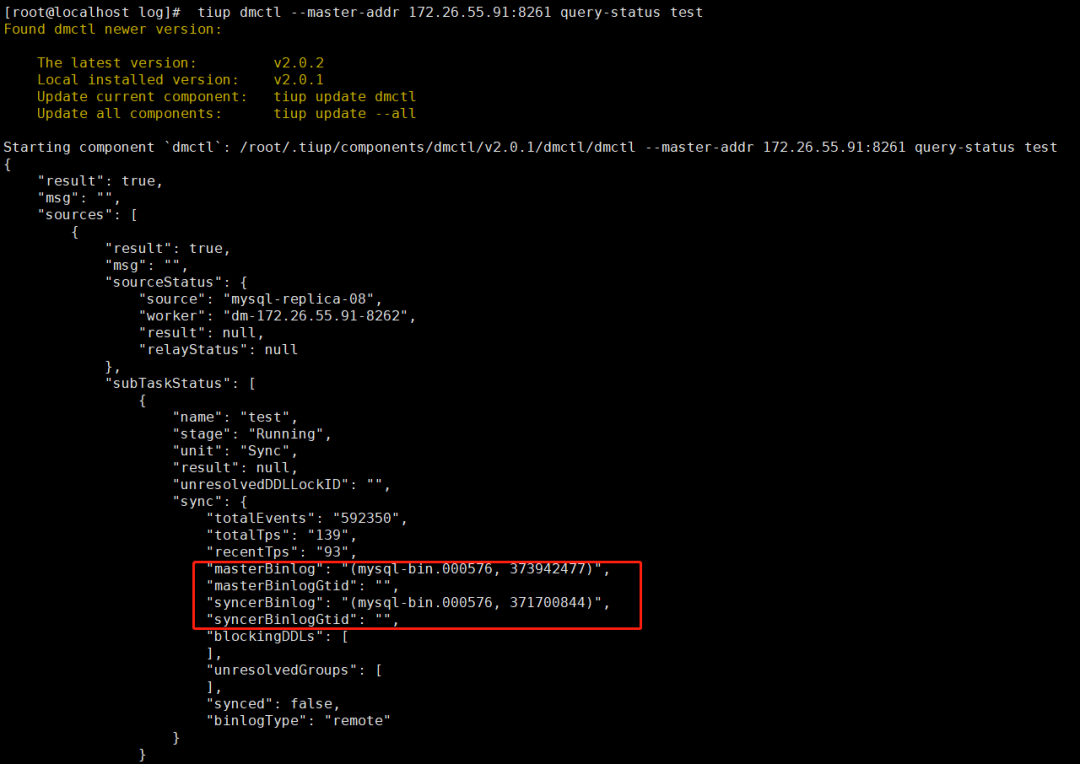
可以看到 masterbinlog 和 syncerbinlog 差的不多,基本处于实时同步状态了。
DM 过程 TiDB 发生 OOM
问题描述
因为是测试环境,所以资源分配比较有限,每台给了 2c/8G/500G:
| IP | Service |
|---|---|
| 172.26.55.91 | tidb-server,pd-server,tikv-server,dm-master,dm-worker,prometheus,grafana |
| 172.26.55.92 | tidb-server,pd-server,tikv-server,dm-master,dm-worker |
| 172.26.55.93 | tidb-server,pd-server,tikv-server,dm-master,dm-worker |
DM 是通过默认配置进行全量迁移数据,报错如下:

dm-worker 的 error log:

解决方案
主要还是资源的问题,所以需要把 DM 同步时的并发线程数降低。
vim task.yaml复制
mysql-instances 下需要调整的参数主要有两个:
loader-thread:
load 处理单元用于导入数据的线程数量,等同于 loaders 配置中的
pool-size
,当同时指定它们时loader-thread
优先级更高。当有多个实例同时向 TiDB 迁移数据时可根据负载情况适当调小该值
syncer-thread:
sync 处理单元用于复制增量数据的线程数量,等同于 syncers 配置中的
worker-count
,当同时指定它们时syncer-thread
优先级更高。当有多个实例同时向 TiDB 迁移数据时可根据负载情况适当调小该值
DM 监控覆盖 TiDB 监控
问题描述
这次 DM 是通过 TiUP 去部署的,部署的时候自动布了套 DM 的监控,使用的是 promethues 和 grafana 占用的端口和之前 TiDB 一样,所以把之前 TiDB-cluster 监控覆盖掉了。导致 TiDB、TiKV、PD 等组件所有的监控项,趋势图都没了。
解决办法
一般来说 DM 属于外部组件,不会和 TiDB 部署在一起,也就不会遇到监控覆盖的问题。
这次使用 scale-out
把监控重新部署回去。
创建一个配置文件 rebulid.yaml
vim /home/tidb/.tiup/rebulid.yaml
# 这里只配置监控信息
monitoring_servers:
- host: 172.26.55.91
ssh_port: 22
port: 9090
deploy_dir: "/data/tidb_cluster/tidb/deploy/prometheus-8249"
data_dir: "/data/tidb_cluster/tidb/data/prometheus-8249"
log_dir: "/data/tidb_cluster/tidb/deploy/prometheus-8249/log"
grafana_servers:
- host: 172.26.55.91
port: 3000
deploy_dir: /data/tidb_cluster/tidb/deploy/grafana-3000
alertmanager_servers:
- host: 172.26.55.91
ssh_port: 22
web_port: 9093
cluster_port: 9094
deploy_dir: "/data/tidb_cluster/tidb/deploy/alertmanager-9093"
data_dir: "/data/tidb_cluster/tidb/data/alertmanager-9093"
log_dir: "/data/tidb_cluster/tidb/deploy/alertmanager-9093/log"复制
使用 scale-out 命令:
tiup cluster scale-out zofund_test toto.yaml复制
DM 常用命令
启动 DM 集群:
tiup dm start dm-test复制查看 DM 集群状态信息:
tiup dm display dm-test复制DM 更新配置:
tiup dm edit-config dm-test复制DM 配置生效:
tiup dm reload dm-test复制创建数据源:
tiup dmctl --master-addr 172.26.55.91:8261 operate-source create source1.yaml复制关闭数据源:
tiup dmctl --master-addr 172.26.55.91:8261 operate-source stop source1.yaml复制任务前置检查:
tiup dmctl --master-addr 172.26.55.91:8261 check-task task.yaml复制开启任务:
tiup dmctl --master-addr 172.26.55.91:8261 start-task task.yaml复制查看任务进度及状态:
tiup dmctl --master-addr 172.26.55.91:8261 query-status test复制查看 DM 成员列表:
tiup dmctl --master-addr 172.26.55.91:8261 list-member复制DM 跳过 DDL 错误:
tiup dmctl --master-addr 172.26.55.91:8261 handle-error test skip复制缩减 DM 集群:
tiup dm scale-in dm-test -N 172.26.55.91:8262复制DM 滚动升级:
tiup dm upgrade dm-test v2.0.1复制查看 DM 日志:
tiup dm audit
tiup dm audit [audit-id] [flags]复制
