




回接上一篇,日常的报表需求,等于我们自己写自己优化,像这种时候一定要有思路,不能胡碰乱撞,有了思路技术才能发散开来,
上次最终结果如下:
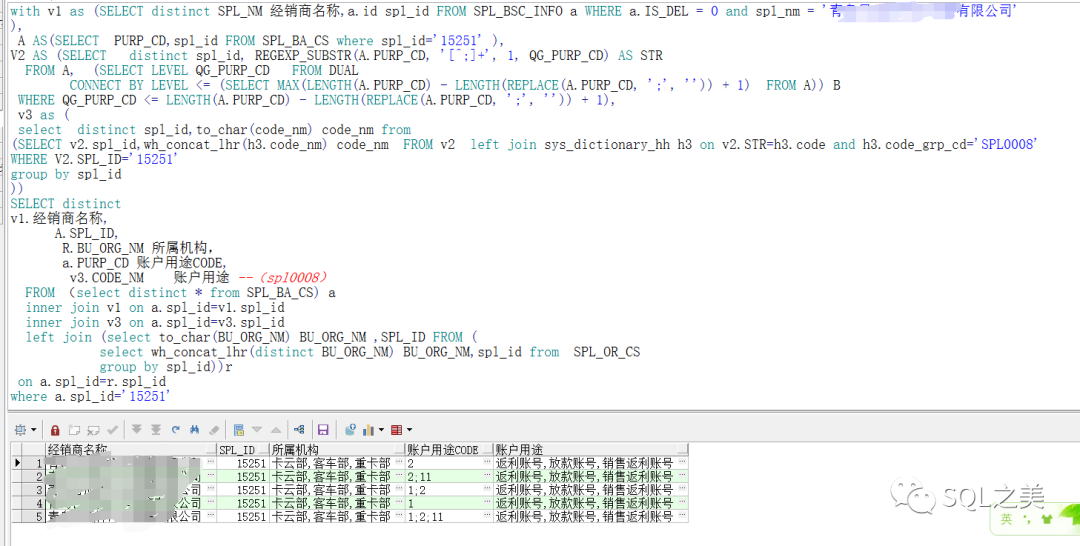
一家之言,针对这种情形大体有三种思路:
建立中间表,针对源表进行垂直切割,拉取关键数据到新表中
观察源表数据结构,进行散列切割,平均拆分数据
根据数据分布情况,创造条件,添加索引,综合12参考水平切割的思想,进行数据压缩。
整体思路如上,下面开始一一实验。
第一个,我们直接查数据结构:
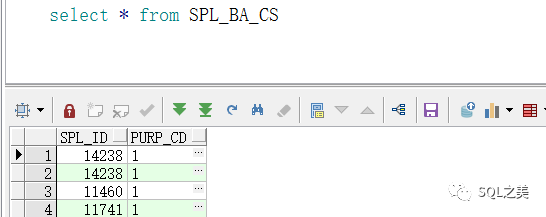
第一个直接GG了。就俩字段800W数据,没有冗余列,无法垂直切割,不可能为了这个报表新建一个表存储他切分后大约1500W的数据,代价太大了!
让我们来尝试第二种思路:
直接切割800W数据 切成1500W效率较低,那么尝试下根据字段长度散列切割:
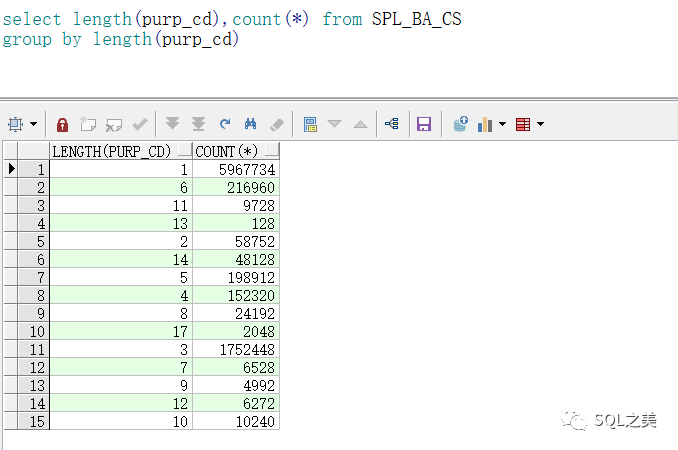
=1 值过多,数据倾斜较大,也无法做散列切割。
到这里,只剩最后一招了,没有条件 让我们创造条件,强行切割达到 减少切割目标 数据量的目的。
让我们先看下目标表实际数据情况:
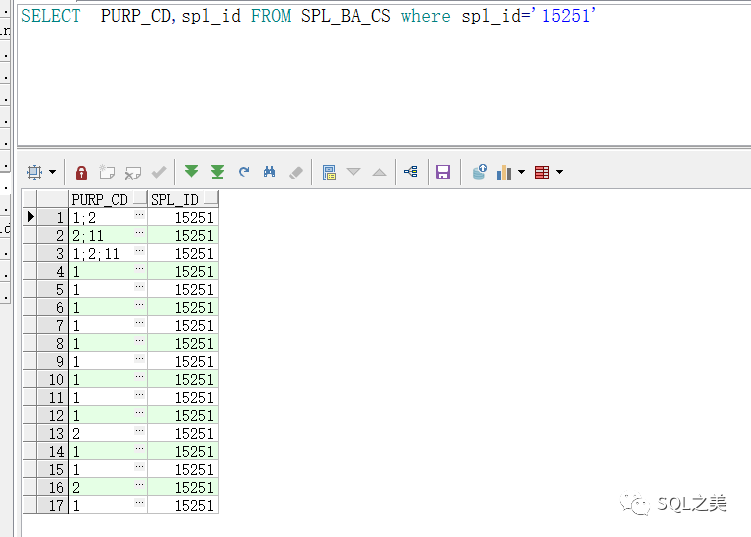
居然 有这么多重复!

果然。去重以后 800W变成 20W! 不知道这些数据干啥的。调整后,让我们查看切割效率:
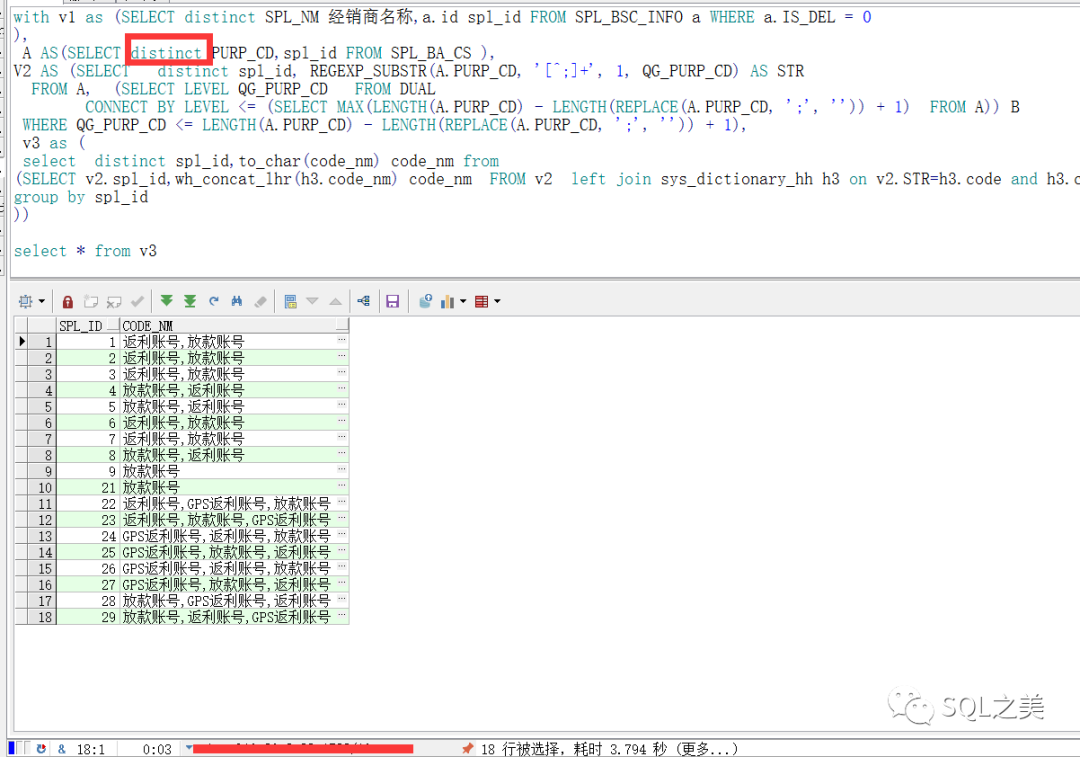
3.8S 切割完毕!
代入到源SQL中:
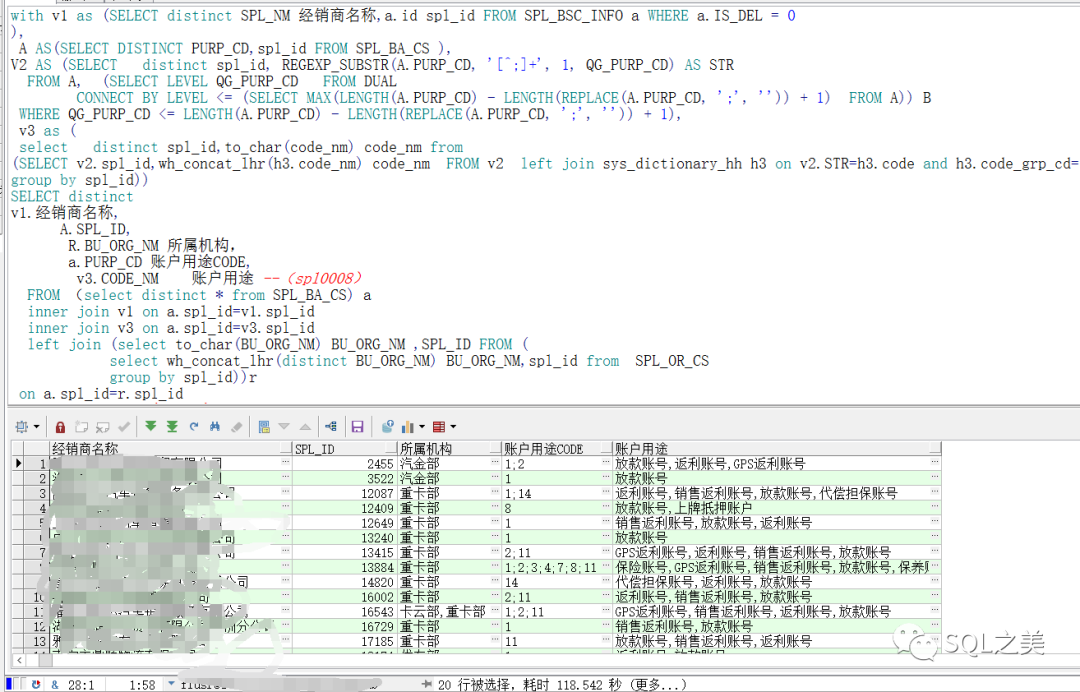
由于这里有个所属机构数据跟账户用途 存储方式相左,一个横向多条一个纵向多条,不得不采用 wh_concat_lhr函数合并(通wm_concat函数效果),118S完成,成功切割完毕。
总结:在面对数据切割需求场景时,减少计算量才是最终极的杀手锏思想。
文章转载自SQL之美,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
数据库国产化替代深化:DBA的机遇与挑战
代晓磊
1192次阅读
2025-04-27 16:53:22
2025年3月国产数据库中标情况一览:TDSQL大单622万、GaussDB大单581万……
通讯员
871次阅读
2025-04-10 15:35:48
2025年4月国产数据库中标情况一览:4个千万元级项目,GaussDB与OceanBase大放异彩!
通讯员
683次阅读
2025-04-30 15:24:06
数据库,没有关税却有壁垒
多明戈教你玩狼人杀
584次阅读
2025-04-11 09:38:42
天津市政府数据库框采结果公布,7家数据库产品入选!
通讯员
571次阅读
2025-04-10 12:32:35
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
551次阅读
2025-04-14 09:40:20
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
489次阅读
2025-04-17 17:02:24
一页概览:Oracle GoldenGate
甲骨文云技术
465次阅读
2025-04-30 12:17:56
GoldenDB数据库v7.2焕新发布,助力全行业数据库平滑替代
GoldenDB分布式数据库
458次阅读
2025-04-30 12:17:50
优炫数据库成功入围新疆维吾尔自治区行政事业单位数据库2025年框架协议采购!
优炫软件
352次阅读
2025-04-18 10:01:22



