




近日,接到开发组长申请优化SQL的需求,本次过程感悟到一些内容,特此分享给各位同仁,前辈,共勉!
简单处理后,初始SQL如下:
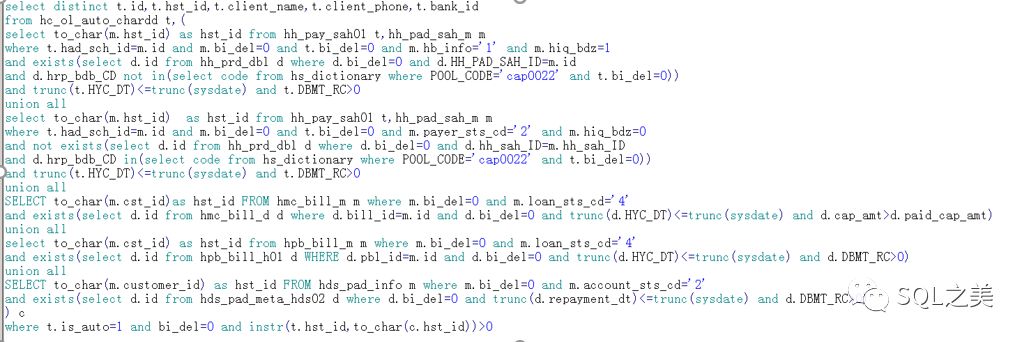
开发反馈,该SQL直接执行高达56分钟才能出结果,查看执行计划:

大概看一眼执行计划发现一些问题,首先count结果集:8226
这个SQL整体结构还是比较简单的,直接拆分计算数据分布:
T表74362条数据,C表15677 ,最外环执行计划看来没啥问题,那么先看看SQL写法:
当然,老司机基本已经一眼看出来问题所在了:
这个条件是无比坑爹的,开发自己也跟我承认错误:这个数据在生产是有问题的,没办法有些业务人员为了做业绩特殊处理了,当时没做数据管控,就这么让这些数据进来了(看看,一个公司木有好的架构设计是多么坑!),高潮来了!这位开发组长跟我们DBA组另一位同事说明:c表的hst_id在t表的hst_id里面,然后t表的hst_id可能存在多条hst_id,而且T表的hst_id值不一定跟C表一样,然后我那位同事就这么告诉我了,同是DBA。。我就这么信了,此时此刻 我以为T和C表的hst_id是这样的:
T表 hst_id值 | C表 hst_id值 |
23123160448,160444323 | 160448 |
这就很无解了。无法将这个条件干掉,like还是个字段,无法走索引优化,只能让他俩走NL然后再把结果集做hash unique。
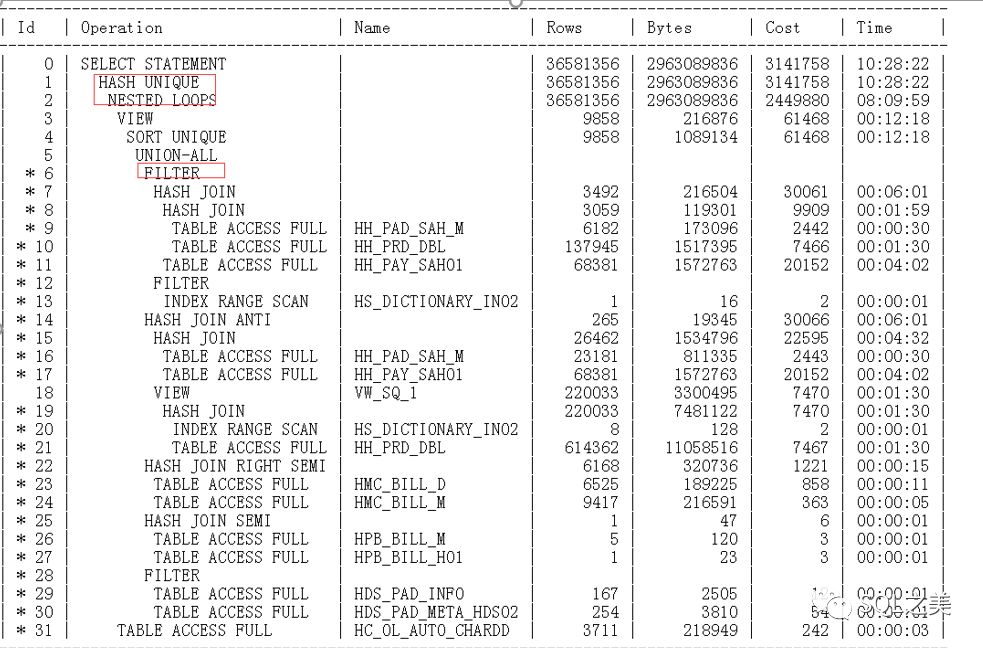
外环无解,那么我们只能加快内环速度,开始分析C表,拆分5个小SQL,通过set auto trace,发现前面2个SQL单独执行消耗的逻辑读均很高,后面3个SQL消耗逻辑读平均不足1500,根据经验,判断C表整体改写减少表链接方式收益不足,那么只能一一针对优化了,让我们来优化第一个:

直接查看执行计划+数据分布+统计信息:

大表全扫,T表多余嵌套条件,看来是问题所在了,干掉多余条件然后针对SQL建立组合索引尝试走FFS:

优化成功,性能降低数十倍,简单对比两者消耗:

继续优化第二个:

跟第一个一样,正好完美利用到刚建立的组合索引,但由于T表多余嵌套条件,d表无法走FFS,干掉【t.bi_del=0】,优化完毕
简单对比两者消耗:
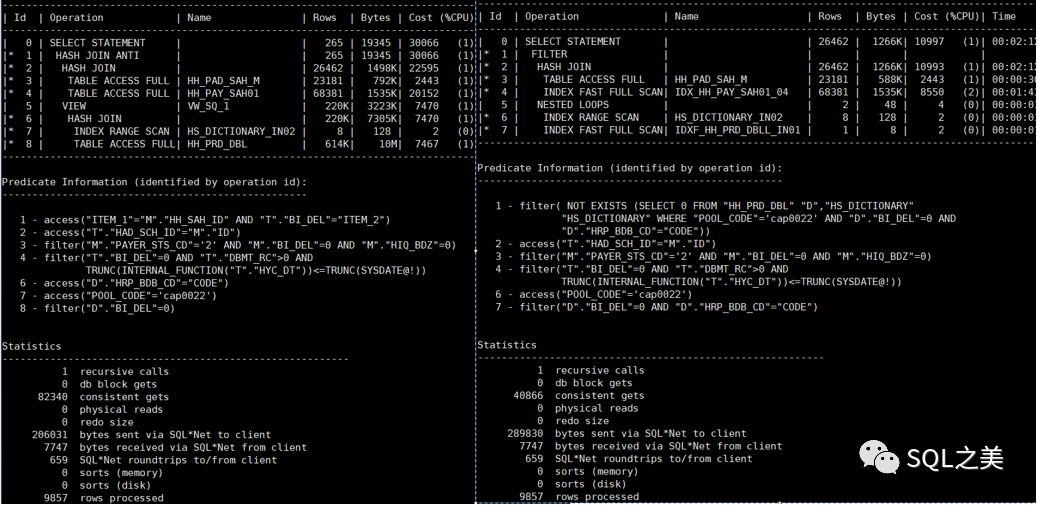
提升一半的性能。
至此,C表基本优化完毕,简单利用WITHAS 查看C表整体消耗:
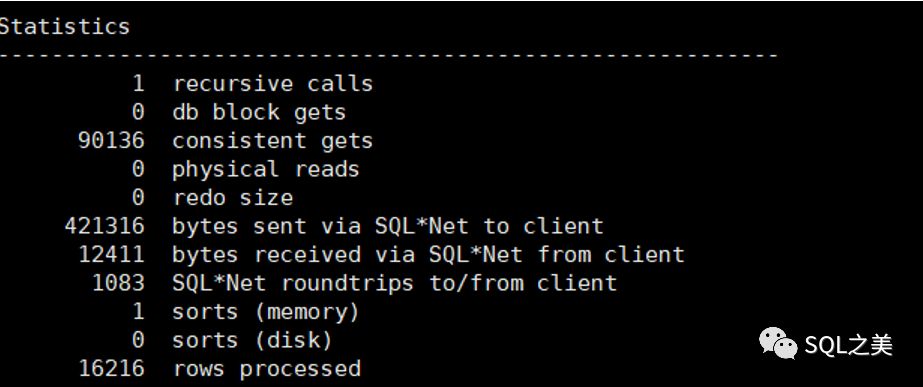
然而,将优化后的SQL放入整体,还是需要10分钟左右才能出来数据,虽然速度已经提升了数倍,但肯定还是不能被开发与业务接受,有人问了,那干脆建立物化视图呗,让他在后台自己更新数据,然而,这个SQL就是一个大型物化视图最重要的部分之一,那么进入到这里,似乎 陷入了死局。
这里在进一步,可以思考:是否可以针对T表数据做处理?
尝试A like B改写 不行使用能否中间表ROWID切片并行关联?
灵光一闪,再次找到这位开发组长确认,原来T和C的hst_id是这样的:
T表 hst_id值 | C表 hst_id值 |
160448,160444323 | 160448 |
T表只会有且只有一个,符号 用来连接不同的HST_ID值!
问题瞬间清晰!果然,坑太多,不确认到底还是不行!
那么针对这种数据如何处理呢?
这里使用了本人编写的自定义函数做了数据处理:
(当小彩蛋吧,后面公布脚本,免得马上被大佬一顿鄙视 哈哈)

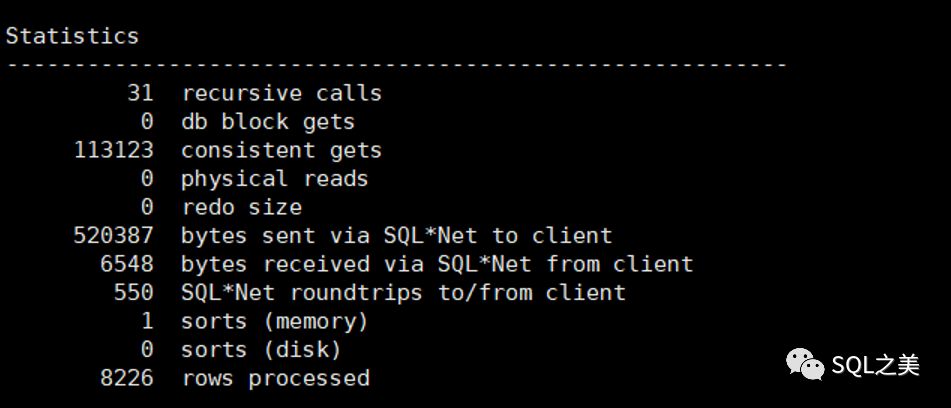

跟前面原始56分钟SQL做对比,结果集一致,确认优化成功!
至此整个过程圆满结束,然而不想玩设计的DBA不是好的开发!这里的问题,归根究底还是数据架构设计的问题,像这种数据(确认非主键),设计应该如何玩呢?
1.建立多种业务需求中间表,专门存储T和C这种关系类型的相关字段
2.中间表建立多个字段,保持与各个源表的外键关联
3.以ROWID分区切片中间表
好处是很多的,降低主表体积,提高查询效率,减少热点压力等等。这里就简单说到这里吧,设计SQL的美妙谁玩谁知道,哈哈!
欢迎各位读者发散思维讨论一波,因本人水平有限,如有不对的地方,欢迎指正!



