




下午2点30左右,负责测试环境的同事电话说测试数据库中心库挂了,看alert日志发现测试环境的DBA同事已经重启好多次也没有成功,启动后马上就Crash。往前
翻看alert,发现最早是中午11:34的时候报的错,这个错误是一个oracle的bug,见mos的:ORA-600 [kghstack_free1] (文档 ID 285602.1):

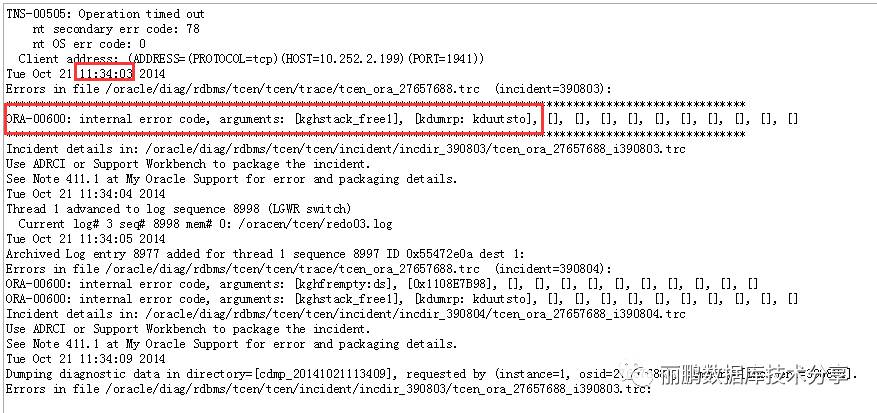
该bug导致数据库异常宕机,当数据库再次启动时,会先前滚(cache recovery),也就是读取redo日志,根据redo中的矢量进行恢复;然后再读取回滚段,进行回滚(tx recovery),异常宕机导致数据库回滚段出现坏块,数据库无法正常回滚,所以测试环境DBA不断尝试重启,一直没有成功,从alert中看问题还是比较明显:
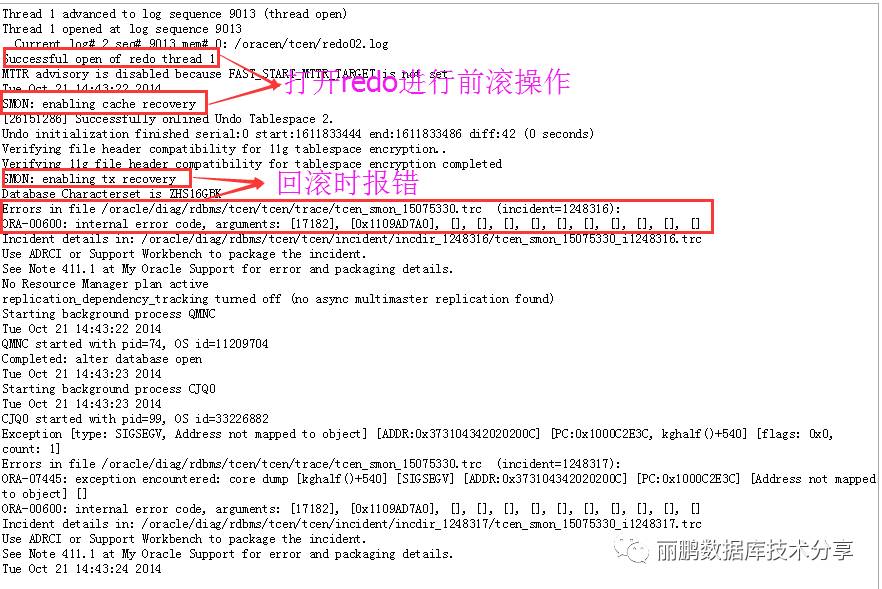
找到了原因,就可以确定解决方案了,解决该问题的思路:
1,设置event禁用smon进行tx recovery临时打开数据库
alter system set event='10513 trace name context forever,level 2' scope='spfile';
重启数据库
2.设置回滚段相关隐含参数,屏蔽回滚,然后重建undo tablespace以彻底解决该问题
新建一个undo表空间
create undo tablespace undotbs_tcen datafile '/oracen/tcendata/undotbs_tcen_01.dbf' size 10240M;
alter system set undo_tablespace=undotbs_tcen;
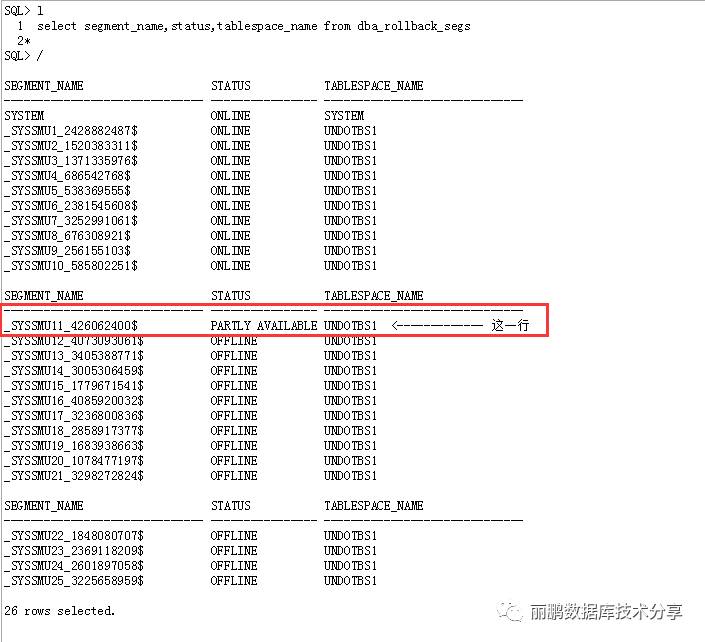
此时直接删除原来的undo表空间是无法删除的
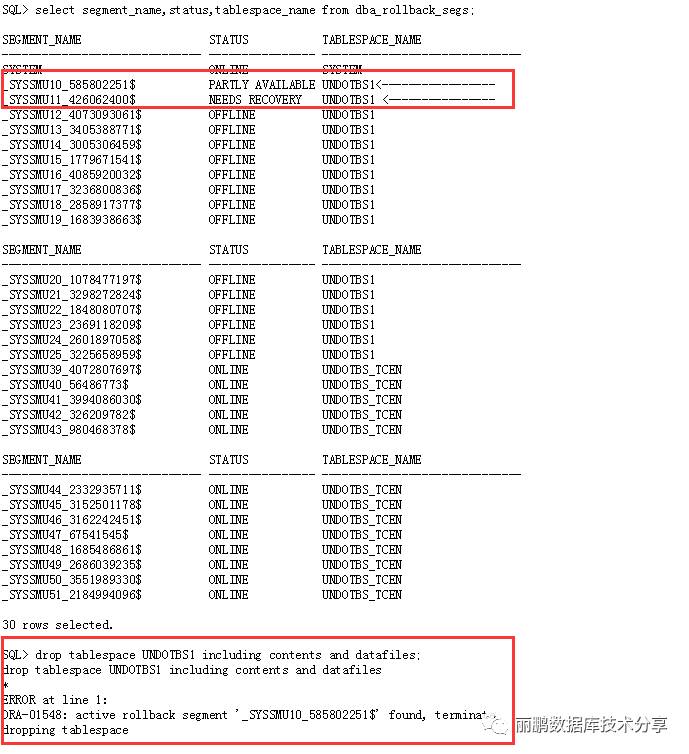
因此需要修改参数文件:
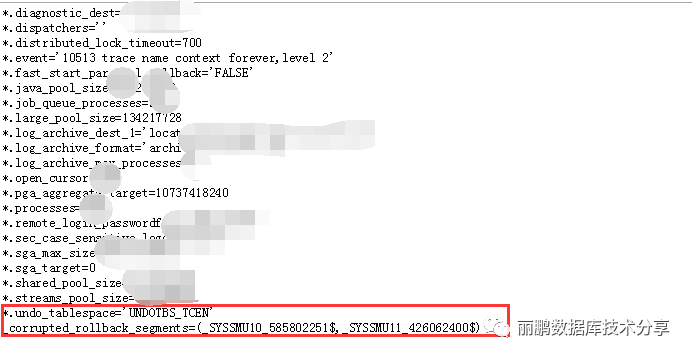
然后再打开数据库来删除老的undo表空间
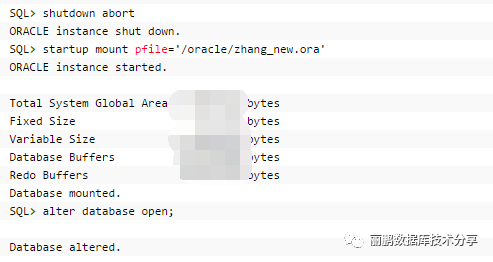

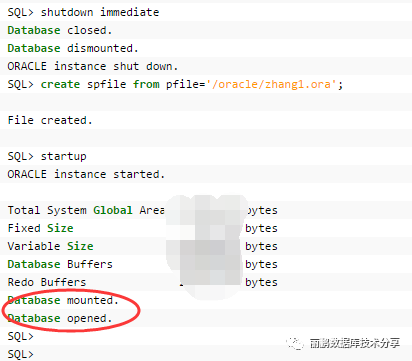
然后去掉参数文件pfile中的下面的参数,重建spfile,然后数据库恢复完成
_corrupted_rollback_segments=(_SYSSMU10_585802251$,_SYSSMU11_426062400$)
*.event='10513 trace name context forever,level 2'
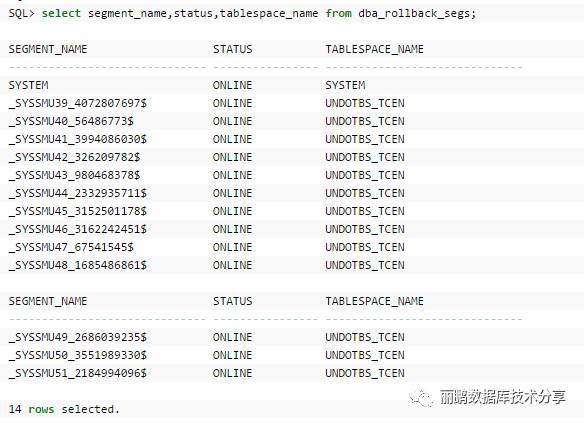
undo表空间全部online状态
-----------完----------
