




数据库版本:11.2.0.4
操作系统:AIX 6.1
一,故障描述:
查看v$session发现有大量latch free等待事件,最高到了800多,而前台tuxdo队列也出现了积压
select event,count(*) from gv$session where wait_class<>'Idle' group by event;
二,故障原因:
由于对一张订单表TF_B_TRADE(普通表)的唯一索引修改为全局HASH分区索引,创建该索引时使用的是parallel 16参数,导致之后
对所有表的操作都使用并行,导致大量的latch 争用。
三,故障排查与分析步骤:
1,开始时发现有大量的latch free的等待,通过上面的语句查询。然后就想看看是哪个sql引起的latch free
select event,count(*),sql_id from gv$session where wait_class<>'Idle' group by event,sql_id;
查询后发现sql_id是空的,居然没有sql_id,于是就想看看latch free具体是什么latch
select event,p1,p2text,p2,p3 from v$session where wait_class<>'Idle' and event='latch free';
发现latch#是24、414

这两个latch比较少见,此时我也不太肯定这两个latch是什么。
2,于是就马上抓了一个当时的AWR,下面我们对AWR进行分析:


都在排队等待CPU,于是我们查看了当时的操作系统CPU负载情况,果然发现在18:40系统负载达到峰值,利用率80%:

在Latch Statistics部分的Latch Activity下面我们也发现了之前我们查到的那两个latch
的等待时间非常长


如果是并行的等待,那么sql执行时间一定很长,为了验证是否是并行我们下一步看看sql的统计
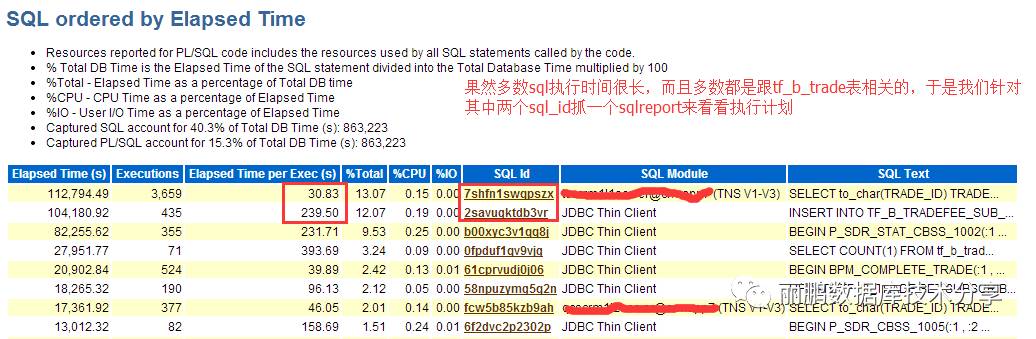
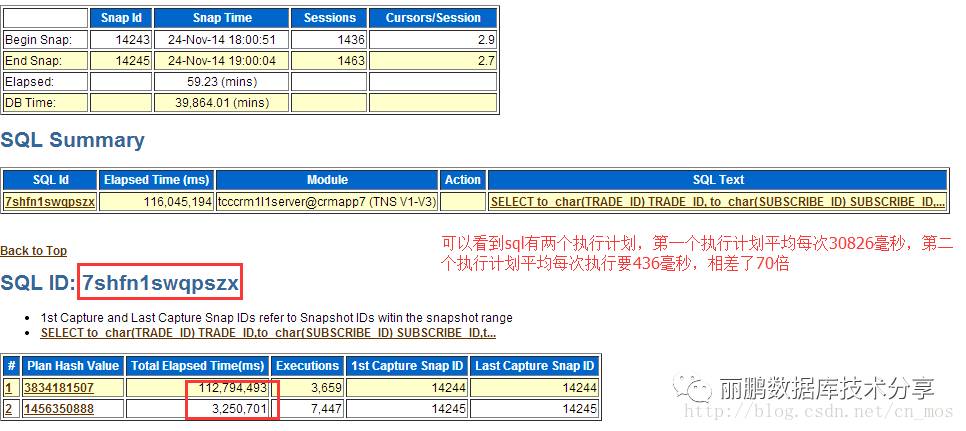

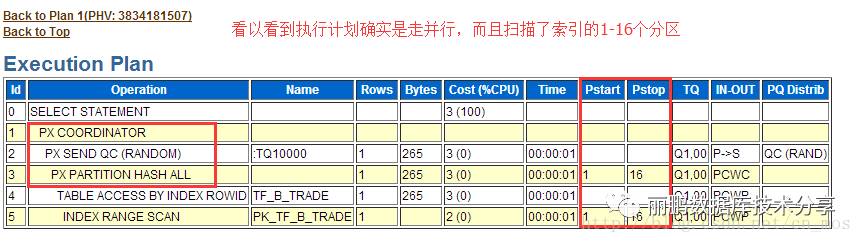
再看另一个sql的执行情况,也是有两个执行计划,一个也是并行的


SQL> show parameter parallel_max
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
parallel_max_servers integer 3600
SQL>
由此可见确实是由于并行导致的数据库的latch 的争用!
3,查看数据库表degree>1,发现就是tf_b_trade表,degree=16

4,把该索引改为非并行可以解决问题
alter index UCR_UIF1.PK_TF_B_TRADE noparallel;
四,总结
我们分析出现这个并行是因为之前针对这个trade有大量的索引分裂,为了缓解这个问题,dba对该索引重建,
重建为hash的分区索引,为了加快创建速度使用了并行,但是oracle会把并行带入到索引属性里,以后只要用到这个索引就会用并行,
使用并行的索引创建后,针对这条sql的执行计划都发生了改变,都要使用并行,因此引起了latch的争用导致sql执行变慢引起前台队列积压。
所以当使用并行创建表或索引后,要使用noparallel取消并行,以免出现不必要的故障。
