




 欢迎关注:)
欢迎关注:)
10月8日晨(长假上班第一天),某女同事早上告知“我的库用不了了,咋办”,回复之“凉拌”。
背景说明,此库为开发库,按照以往经验认为可能是监听死掉了,没太当回事。登陆服务器查看一下吧。
例行动作,检查os日志,检查磁盘空间,发现磁盘空间满了,这简单啊。加一块磁盘吧,扩充完文件系统,启动数据库,发现不太妙啊.....
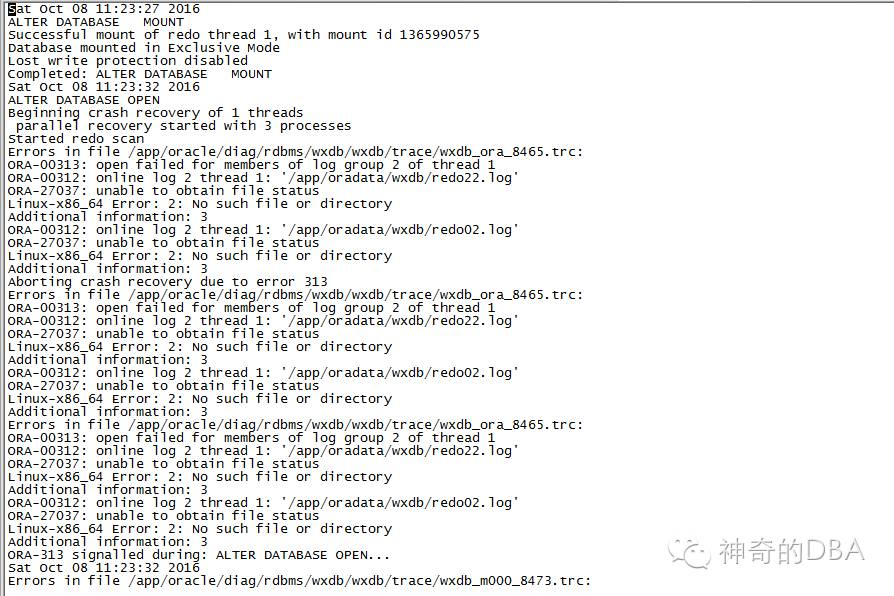
在线日志丢失了,OMG。长假后第一天就这么刺激!ORA-00313 ORA-00312 ORA-27037多么讨厌的数字又看见了。烦恼的不是多难解决,数据基本也不会丢失,而是还得重建数据库,工作量啊。开发数据库也是数据库啊,咱得一视同仁,不能歧视它吧,本着救数据库一命胜造N级浮屠的仁心,搞一搞吧。过程其实挺简单的,如下:
先生成pfile
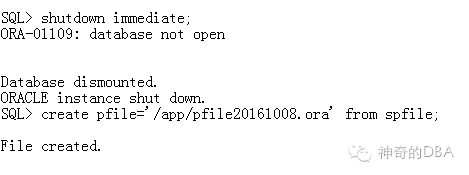
使用隐含参数拉起数据库 使用_allow_resetlogs_corruption参数进行拉起数据库。 --allow resetlogs even if it will cause corruption --当前日志损坏;没有数据库备份; 有活动事务,非正常关闭;

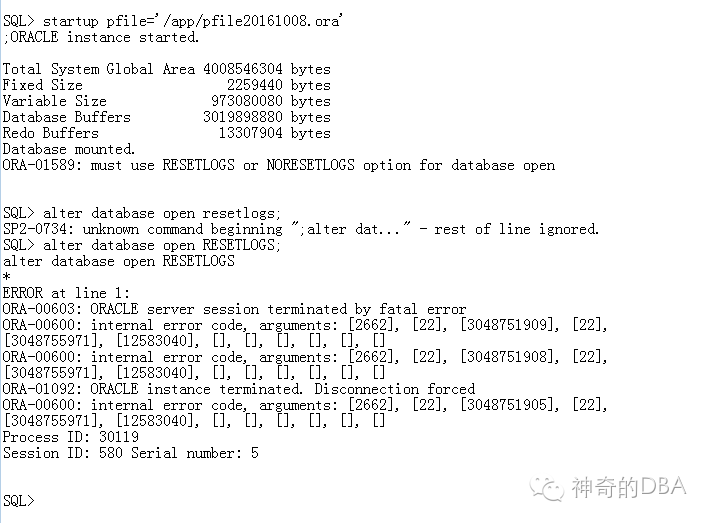
这时会遇到2662报错:。非正常关闭导致SCN不一致。[2662]往往需要通过adjust scn来推进SCN,[2663]有时候能够通过反复重启数据库自动修复. 一般解决方法:
这里我采用如下方法: 这时启动数据库会遇到如下问题:
SQL>startup
这时启动数据库会遇到如下问题:
SQL>startup
4194错误:[4194]表示UNDO表空间存在逻辑错误,([4***]表示与undo有关的错误) 解决方法:1>在参数文件中修改
undo_management='MANUAL'
--manual表示oracle使用system回滚段进行操作,auto表示oracle使用undoTablespace自动管理
2>在参数文件中添加
_offline_rollback_segments_corrupted_rollback_segments标识损坏块(或者全部_SYSSMUn$),
跳过进行启动
_offline_rollback_segments=true
_corrupted_rollback_segments=(_SYSSMU2$,_SYSSMU3$,_SYSSMU4$,_SYSSMU5$,_SYSSMU6$,_SYSSMU7$,_SYSSMU8$,_SYSSMU9$,_SYSSMU10$,_SYSSMU1$,_SYSSMU11$,_SYSSMU12$,_SYSSMU13$,_SYSSMU14$,_SYSSMU15$,_SYSSMU16$,_SYSSMU17$,_SYSSMU18$,_SYSSMU19$,_SYSSMU20$)

SQL>startup --现在应该正常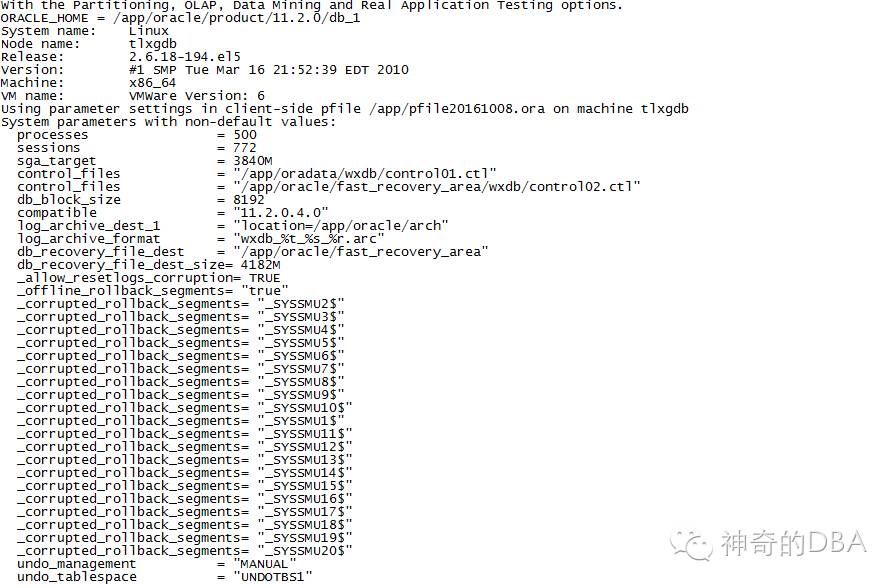
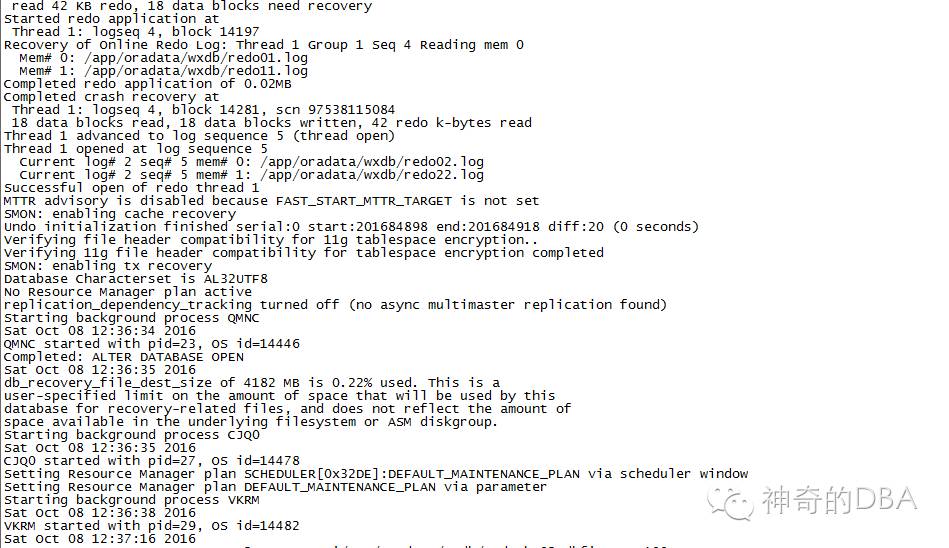
建立新的undotablespace,删除老的,这就不写了。修改参数文件 undo_management='AUTO',undo_tablespace='undotbs2',然后就应该能正常启停了。可能还会遇到如下问题
ORA-08102: index key not found -- 索引键值与表不一致 --drop/create ;
SMON应用redo,undo进行实例恢复:
设置Oracle参数event 10513将禁止smon进程进行事务回滚
select pid, program from v$process where program like '%SMON%';
PID PROGRAM
---------- ------------------------------------------------
13 oracle@tlxgdb (SMON)
针对smon进程进行参数设置
SQL> oradebug setorapid 13;
Oracle pid: 13, Unix process pid: 4779, image: oracle@tlxgdb (SMON)
SQL> oradebug event 10513 trace name context forever, level 2
Statement processed.
关闭event参数
SQL> oradebug event 10513 trace name context off
Statement processed.
至此结束拉起数据库任务,后面需要执行全库导出,重建DB,全库数据导入,这就不写了,还没吃午饭呢.......
