




2016年2月3日上午8点左右,接到同事电话反映一套集群数据库不能正常访问,简单询问之后,初步判断应该是归档日志空间满导致ORA-00257: archiver error. Connect internal only, until freed,到公司进行初步检查判断果然如此。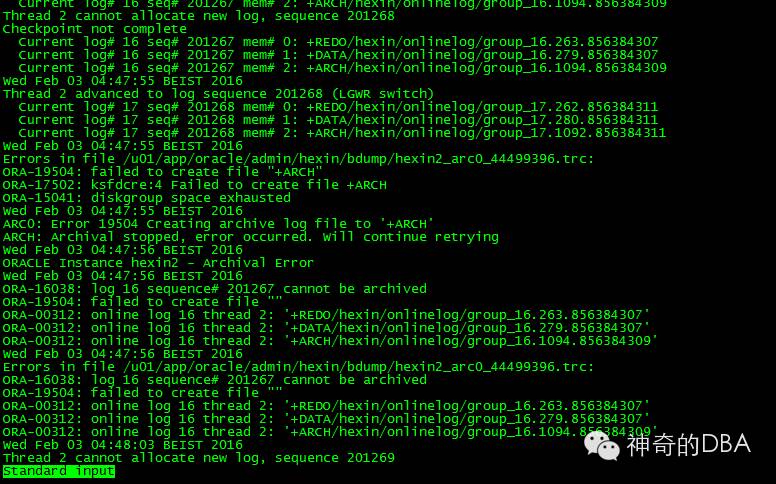
此问题处理起来并不困难,用rman清掉归档日志即可,但究竟是什么原因造成了12个小时之内400G的archivelog空间满呢?让DBA来抽茧剥丝,根据线索追述本源吧。
首先查询该集群数据库每天的归档日志记录,
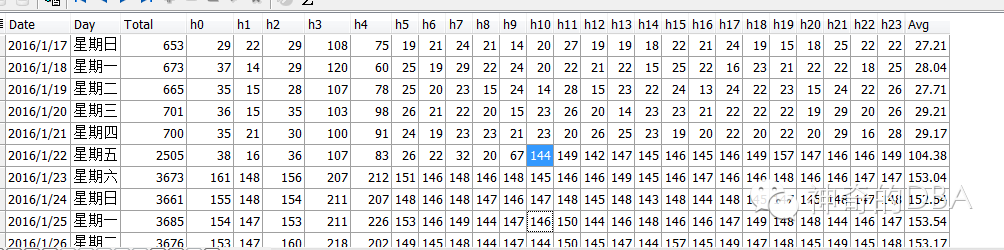
可以看到之前每天的归档日志切换数量在600-700次左右(redo 200M每个),但在1月22日10点后激增5倍之多!why?这时候就要看DBA的快速分析判断能力了,因为高频归档还在继续,病源未除,岂能收兵?
在性能瓶颈的高压力下,一个DBA或者一个运维人员如何能快速定位故障点并迅速解决呢?这已经是一个团队的时代,互联网的时代,DBA也不再是单打独斗的孤胆战士,作为甲方我决定,找外援结合自主分析。马上联系数据库服务商,并提交故障点相关awr等报告,组成临时团队一起追述这个故障的根源,人多力量大嘛!30分钟,基本找到了故障源,并确定了初步solution。(在我的职业生涯里,30分钟一直是一个神奇的周期,绝大部分问题与故障应该在30分钟内找到并给出solution,超过30分钟无果的,那就可能摊上事了......)

(BTW这服务商非常专业,有需要的兄弟关注本媒体号,二维码见上图 ^.^)
下面简述一下侦破过程:
归档日志的产生绝大部分是由DML语句产生的,从下图可看到由DML语句导致数据块变化最多的对象,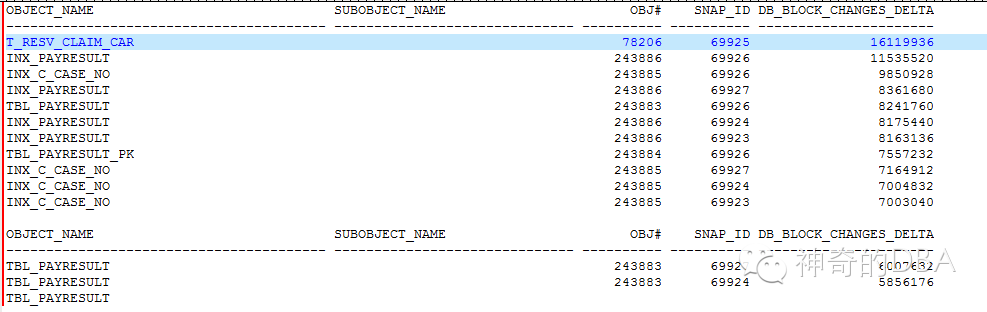
这是非常重要的线索。由此锁定TBL_PAYRESULT 和 t_recv_claim_car 表这条线索继续查。
再结合看故障时刻的awr,两个节点上均出现了堵塞(共享存储的缘故),节点1 redo为10万/s,节点2 redo 为80万/s
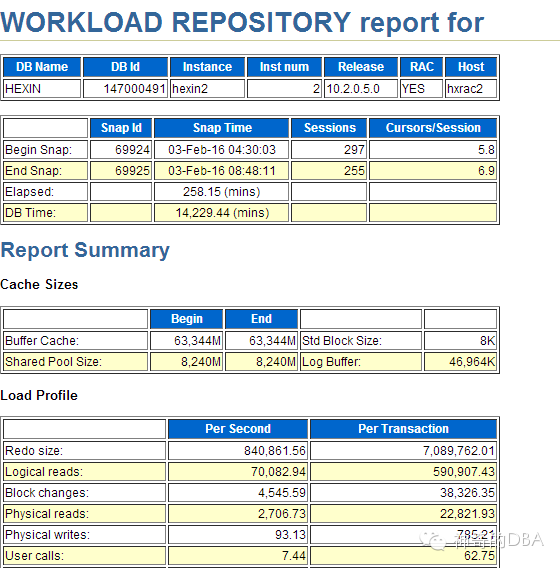
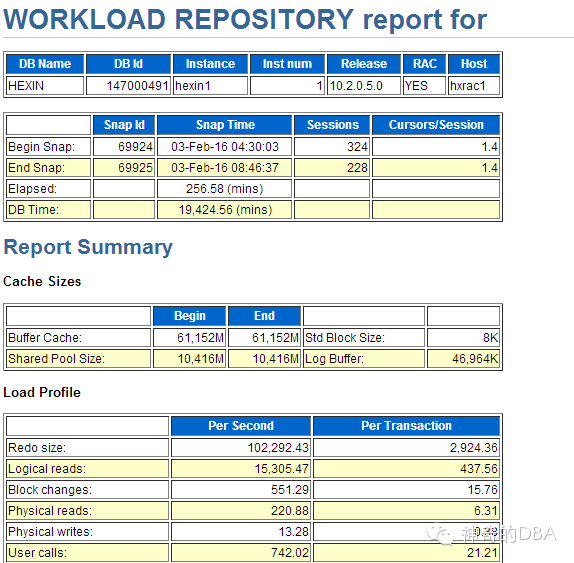
并通过ash,取04:30~05:00,看到节点2上(节点1上没任何信息)在TBL_PAYRESULT表上有DML语句,因为insert语句调用了另一套库上一个很慢的视图——BHZJ.V_PAYRESULT,所以其活跃度比较高,就被ash抓出了。联想到昨天上午BHZJ所在库的繁忙程度比往常多出40%,初步猜测可能与此有关。
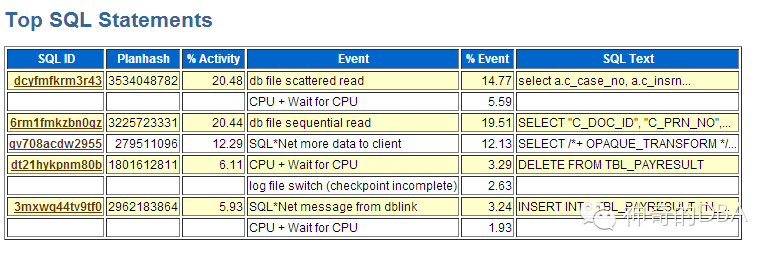

从ash中还可以看出,BHRESVADMIN.PROC_RESV_DATA_DAILY和CLAIM.MOVEPAYRESULT这两个过程最活跃,而这也正契合DB_BLOCK_CHANGES最大的两个对象tbl_payresult 和 t_recv_claim_car。

根据以上线索继续挖掘,经过与开发人员协调,确认一个临时解决方案,分为两部分:
1,将一个每3分钟执行一次的job,拉长为每30分钟执行一次
2,将job中delete表操作改为truncate。
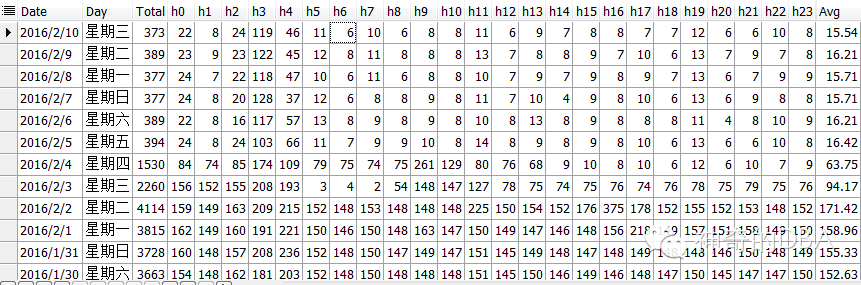
实施后的效果从每天将近4000次归档降为400次,降低近10倍。后续再将数据交互方式改变,应该会有更好的效果。
BTW:至于为啥归档频次突然增大5倍,这涉及了商业机密不便在此透露,但可以确定的是跟应用上线有关。有兴趣的buddy可以关注本订阅号(神奇的DBA)私下与我交流。
此case由大罗,老怀一起完成!
