




序言 : 测试目的与情况说明
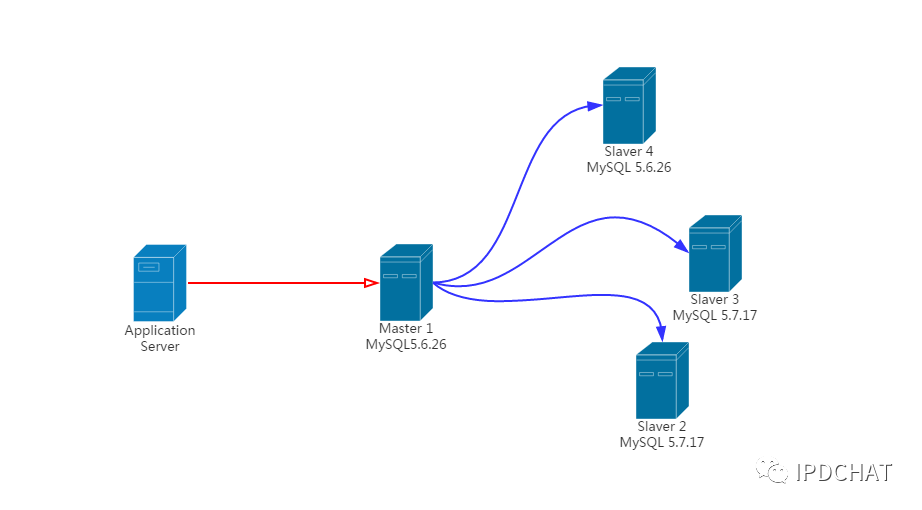
当前公司线上数据库主要是一主三从的架构,而且数量巨大,如何不借助中转服务器,就可以相对比较平滑的,对业务影响较小的情况下,升级到MySQL 5.7 的GR模式,希望借助此测试给大家一些参考。
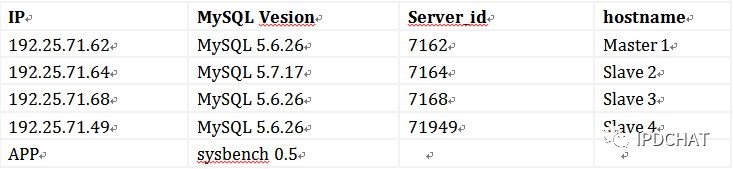
目前系统结构为1主3从四台MySQL Server结构,已经把其中Slave2,Slave3先升级为Mysql5.7.17。
使用sysbench模仿应用服务器访问读写服务器;
其中的MySQL5.7.17配置了以下参数:
log-bin=mysql-bin
binlog-format = ROW
log-slave-updates = ON
master-info-repository = TABLE
relay-log-info-repository = TABLE
binlog-checksum = NONE
slave-parallel-workers = 0
transaction-write-set-extraction=XXHASH64
其中的MySQL5.6两台参数和线上保持一致,列出相关参数:
log-bin=mysql-bin
binlog-format = ROW
log-slave-updates = ON
master-info-repository = TABLE
relay-log-info-repository = TABLE
binlog-checksum=CRC32
第一步 : 准备工作
使用sysbench准备数据
sysbench --test=oltp --oltp-table-size=100000 --db-driver=mysql --mysql-host="127.0.0.1" --mysql-port=3306 --mysql-user=root --mysql-password='' --mysql-db=waybill prepare
sysbench 1.0: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
在四台服务器 查询数据量得到相同的结果
select count(*) from waybill.sbtest1;
+----------+
| count(*) |
+----------+
| 100000 |
+----------+
运行sysbench基准测试,模拟数据读写操作
while true; do sysbench --test=oltp --oltp-table-size=100000 --oltp-read-only=off --init-rng=on --num-threads=32 --oltp-test-mode=complex --max-requests=0 --max-time=300 --tx-rate=20 --num-threads=2 --report-interval=5 --db-driver=mysql --mysql-host="127.0.0.1" --mysql-port=3306 --mysql-user=root --mysql-db=waybill --mysql-password='' run > result.log;done;
验证主从数据一致性,实际生产业务应该由研发同事验证5.7.17应用程序可读取。准备切换主库到Slave 2
pt-table-checksum --host=192.25.71.62 --recursion-method=processlist --no-check-binlog-format --port=3306 --user=root --ask-pass --databases=waybill
Enter MySQL password:
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
12-24T18:32:14 0 0 100000 4 0 1.088 waybill.sbtest1
第二步 : 切换主库到其中一台MySQL 5.7.17
因为在数据库的前端没有使用ProxySQL之类的proxy,所以我们暂停业务之后切换。
确保切换时主从一致性,即使在应用停之后,也要在Master 1开启只读。
set global read_only =1;
Query OK, 0 rows affected (0.00 sec)
show master status\G
*************************** 1. row ***************************
File: mysql-bin.000005
Position: 56742560
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set:
1 row in set (0.00 sec)
在所有的从库确认是否已经有已经数据都已同步完成
show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.25.71.62
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000005
Read_Master_Log_Pos: 56742560
Relay_Log_File: relay-log.000004
Relay_Log_Pos: 29072
Relay_Master_Log_File: mysql-bin.000005
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 56742560
Relay_Log_Space: 56742703
……
在作为新主库的从库Slave 2上确认最新的binlog文件和点,并停止从旧主库的复制,关闭只读模式。
show master status\G
*************************** 1. row ***************************
File: mysql-bin.000003
Position: 56497493
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set:
1 row in set (0.00 sec)
stop slave;
Query OK, 0 rows affected (0.00 sec)
set global read_only=0;
Query OK, 0 rows affected (0.00 sec)
将Slave 3接入新主库作为从库
stop slave;
Query OK, 0 rows affected (0.00 sec)
Change master to master_host="192.25.71.64",master_port=3306,master_user="repl",master_password="password",master_log_file="mysql-bin.000003",master_log_pos=56497493;
Query OK, 0 rows affected, 2 warnings (0.02 sec)
start slave;
Query OK, 0 rows affected (0.00 sec)
show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.25.71.64
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 56497493
Relay_Log_File: relay-log.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mysql-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
开启sysbench连接新主库,
sysbench --test=oltp --oltp-read-only=off --init-rng=on --num-threads=32 --oltp-test-mode=complex --max-requests=0 --tx-rate=30 --report-interval=5 --db-driver=mysql --mysql-host="192.25.71.64" --mysql-port=3306 --mysql-user=root --mysql-db=waybill --mysql-password='' run > result.log
show processlist已有应用连接,binlog发生变化,说明数据已经写入,观察Slave 3复制状况确认复制没有问题。
根据以往MySQL 5.5升级5.6的经验,低版本不能接入到高版本作为从库,所以第二步结束。
目前的结构为:
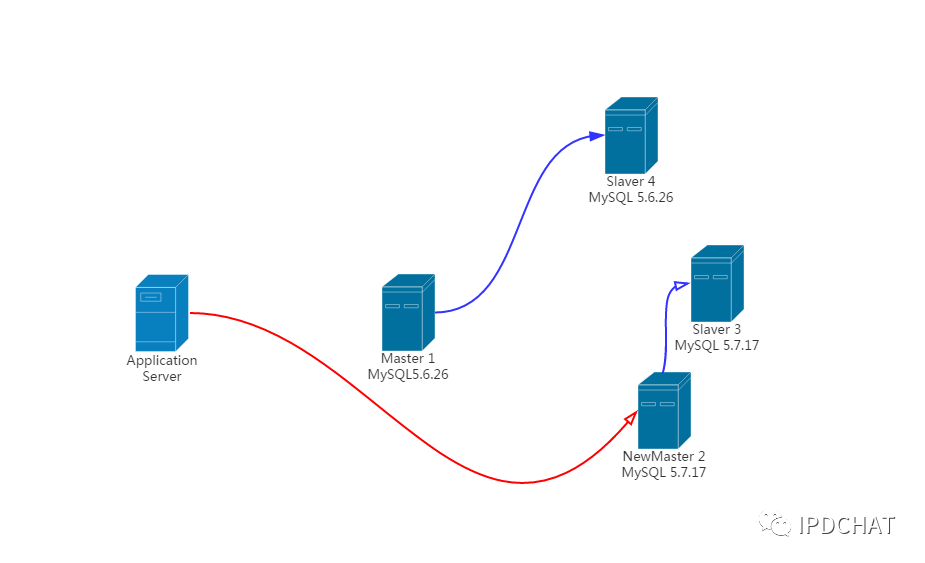
第三步 : 普通主从模式切换GTID复制模式
业务跑一段时间之后,接下来我们将实现不停业务实现修改为GTID复制
以下是官方文档提供的MySQL Group Replication的参数设置需求:
server_id=1 需要所有节点的server_id保持唯一
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
binlog_checksum=NONE
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW
MySQL 5.7.6以后的版本可以在线进行GTID的切换,但是要保证所有组中成员gtid_mode 为off状态。
以下为操作步骤:
NewMaster 2和Slave 3都执行。
set @@global.enforce_gtid_consistency = warn;
2. NewMaster 2和Slave 3都执行。
set @@global.enforce_gtid_consistency = on;
3. NewMaster 2和Slave 3都执行。
set @@global.gtid_mode = off_permissive;
4. NewMaster 2和Slave 3都执行。
set @@global.gtid_mode=on_permissive;
5. 执行按顺序执行完成之后,这时候新生成的binlog都带有GTID,我们还需要在NewMaster 2和Slave 3确认传统的binlog已经复制完成。
show status like 'ongoing_anonymous_transaction_count';
需要确认所有查询结果都为0。
6. NewMaster 2和Slave 3执行flush logs 切换一下日志文件。
7. 所有节点启用Gtid。
set @@global.gtid_mode=on;
8. 修改my.cnf添加参数防止重启参数失效。
gtid_mode=ON
enforce_gtid_consistency=ON
9. 在Slave 3转换成GTID复制
stop slave;
change master to master_auto_position=1;
start slave;
第四步 : 切换主从模式到Group Replication
这一步中我们将GTID主从复制模式切换到Group Replication模式
1. NewMaster 2和 Slave 3执行:
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
2. 在NewMaster 2上执行:
set @@global.transaction_write_set_extraction = XXHASH64;
set @@global.group_replication_start_on_boot = OFF;
set @@global.group_replication_bootstrap_group = OFF;
set @@global.group_replication_group_name = "d91ccd09-cb4b-11e6-9727-e83935247f08";
set @@global.group_replication_local_address = '192.25.71.64:6606';
set @@global.group_replication_group_seeds = '192.25.71.64:6606,192.25.71.68:6606';
3. 在Slave 3 上执行:
set @@global.transaction_write_set_extraction = XXHASH64;
set @@global.group_replication_start_on_boot = OFF;
set @@global.group_replication_bootstrap_group = OFF;
set @@global.group_replication_group_name = "d91ccd09-cb4b-11e6-9727-e83935247f08";
set @@global.group_replication_local_address = '192.25.71.68:6606';
set @@global.group_replication_group_seeds = '192.25.71.64:6606,192.25.71.68:6606';
注意这里的端口绝对不能设置为原数据库端口3306,否则后边开启Group Replication会失败错误日志里会提示:
[ERROR] Plugin group_replication reported: 'Unable to announce tcp port 3306. Port already in use?'
group_replication_group_name必须配置为uuid,而且两个服务器要配置相同,
这个值我使用select uuid() 生成。
group_replication_local_address配置本地的ip和端口(非3306)。
group_replication_group_seeds 配置本组内的所有ip和端口。
注意 transaction_write_set_extraction=XXHASH64 需要在之前配置过。
在Newmaster2执行:
CHANGE MASTER TO MASTER_USER='repl', MASTER_PASSWORD='password' FOR CHANNEL 'group_replication_recovery';
注意:复制用户是使用最初建立复制关系时建立。
开启Group Replication之前需要设置group_replication_ip_whitelist,初始值是AUTOMATIC,不设置的话:
START GROUP_REPLICATION;
ERROR 3092 (HY000): The server is not configured properly to be an active member of the group. Please see more details on error log.
查看errlog提示:
[Warning] Plugin group_replication reported: '[GCS] Automatically adding IPv4 localhost address to the whitelist. It is mandatory that it is added.'
于是我们执行:
set global group_replication_ip_whitelist="192.25.71.0/8";
Query OK, 0 rows affected (0.00 sec)
START GROUP_REPLICATION;
Query OK, 0 rows affected (1.01 sec)
SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 97d51642-c83c-11e6-8c67-e83935247f08 | NewMaster2 | 3306 | ONLINE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
1 row in set (0.00 sec)
已经可以观察到有一台机器已经加入到Group Replication了。
在Slave 3中:
set global group_replication_ip_whitelist="192.25.71.0/8";
Query OK, 0 rows affected (0.00 sec)
START GROUP_REPLICATION;
Query OK, 0 rows affected (5.50 sec)
Slave 3开启Group Replication,可以在NewMaster 2观察机器状态(MEMBER_STATE)从 RECOVERING转为ONLINE的过程:
SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 97d51642-c83c-11e6-8c67-e83935247f08 | NewMaster2 | 3306 | ONLINE |
| group_replication_applier | f3af318c-c8cf-11e6-b8e5-e8393524f7ee | Slave3 | 3306 | RECOVERING |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
2 rows in set (0.00 sec)
SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 97d51642-c83c-11e6-8c67-e83935247f08 | NewMaster2 | 3306 | ONLINE |
| group_replication_applier | f3af318c-c8cf-11e6-b8e5-e8393524f7ee | Slave3 | 3306 | ONLINE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
2 rows in set (0.00 sec)
目前的结构为:
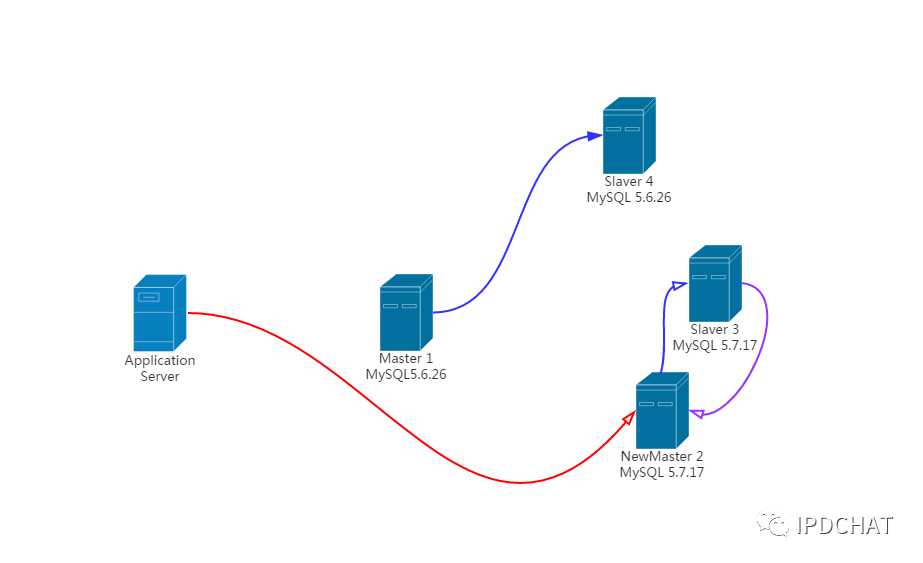
第五步 : 把之前的MySQL5.6升级5.7加入到Group Replication
首先使用Slave 4为例子,在做接入之前把Mysql停止,数据目录和程序目录移动到备份目录。之后安装MySQL 5.7.17,并确认这些参数的配置:
server_id=1 所有节点的server_id保持唯一
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
binlog_checksum=NONE
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW
在NewMaster 2中执行
/export/servers/mysql/bin/mysqldump --all-databases --master-data=2 --triggers --routines --events -hlocalhost -P3306 -uroot -p > tmp/masterall.sql
这一步中不能像5.6备份一样使用--single-transaction参数,否则会提示1290错误,而且实际sql文件里的数据是有问题的,缺少很多库和表的数据。
scp文件到Slave 4导入sql
/export/servers/mysql/bin/mysql -hlocalhost -P3306 -uroot -p < export/data/mysql/dumps/masterall.sql
在errorlog中发现最新的提示
2016-12-27T07:05:34.370571Z 6 [Note] @@GLOBAL.GTID_PURGED was changed from '' to '97d51642-c83c-11e6-8c67-e83935247f08:1-425220,
d91ccd09-cb4b-11e6-9727-e83935247f08:1-452762'.
2016-12-27T07:05:34.370610Z 6 [Note] @@GLOBAL.GTID_EXECUTED was changed from '' to '97d51642-c83c-11e6-8c67-e83935247f08:1-425220,
d91ccd09-cb4b-11e6-9727-e83935247f08:1-452762'.
如果导入出现错误提示
ERROR 1840 (HY000) at line 24: @@GLOBAL.GTID_PURGED can only be set when @@GLOBAL.GTID_EXECUTED is empty.
先执行reset master 再次执行就可以了。
导入数据完成之后我们需要修改原来节点的members信息:
在Slave 3和NewMaster 2中执行
set global group_replication_group_seeds = "192.25.71.64:6606,192.25.71.68:6606,192.25.71.49:6606";
其实也可以不修改,只是Slave 4加入到Group Replication之后,其他节点的group_replication_group_seeds 的参数不会被自动修改。
在Slave 4中执行:
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
set @@global.group_replication_group_name = "d91ccd09-cb4b-11e6-9727-e83935247f08";
set global group_replication_ip_whitelist="192.25.71.0/8";
set @@global.group_replication_local_address= '192.25.71.49:6606';
set global group_replication_group_seeds = "192.25.71.64:6606,192.25.71.68:6606,192.25.71.49:6606";
CHANGE MASTER TO MASTER_USER='repl', MASTER_PASSWORD='password' FOR CHANNEL 'group_replication_recovery';
start group_replication;
注意在Slave 4上执行show master status\G观察是否binlog位置发生变化,还有在其他节点查看MEMBER_STATE,直到Slave 4状态从RECOVERING成为ONLINE。
最后用同样的方式把最初的主库也接入到Group Replication。
作为收尾工作,关闭每一台服务器只读模式开启多个应用写入不同的节点。
并行写入测试过程中出现sysben强退的问题,提示错误:
ALERT: mysql_drv_query() returned error 1180 (Got error 149 during COMMIT) for query 'COMMIT'
FATAL: failed to execute function `event': 3
在对应的实例中show engine innodb status\G中提示这两个sql发生死锁。
DELETE FROM sbtest1 WHERE id=4982
INSERT INTO sbtest1 (id, k, c, pad) VALUES (4982, 4978, '42430618369-09772564852-28891611107-28303609950-16784581221-80984984106-09373377499-91149711480-29531268561-74594260540', '62976712932-54931665568-44168600775-93871457929-74080148907')
结论
从5.6主从复制迁移到Group Replication过程并不是难搞定,唯一的断点在于第二步切换到5.7,之后我们会使用自动切换系统进行切换,尽量减小对业务的影响。
另外对多主写入推荐使用proxy灵活的设置规则,应用直接连必然会出现死锁和锁争用现象。
以上内容为IPD原创,如需转载,请注明出处~
扫描下方二维码关注我们~IPDCHAT专注输出技术干货~!


