




当了一段时间DBA,觉得一个DBA最重要的能力是一种学习的自驱力,提升业务能力的办法就是学习前人的经验,总结自己的教训;只有懂得多了深了,线上操作就会有数了。作为一个数据库,有两个使命:可靠的存储和高效的计算,这两个任务是不是做好了,完备的监控也是必不可少,否则你对自己的数据岂能放心?本文有以下内容:
1. 有效的存储1.1 内存分配器1.1.1 内存分配器简述1.1.2 PostgreSQL的内存管理对象1.2 缓冲区管理1.2.1 缓冲区管理器简述1.2.2 PostgreSQL中的缓冲区管理对象1.3 访问方法1.3.1 访问方法简介1.3.2 PostgreSQL磁盘里的结构1.3.2.1 PostgreSQL 数据库目录的结构1.3.2.2 PostgreSQL 表文件的结构1.3.2.3 PostgreSQL的页的结构1.3.3 PostgreSQL 磁盘的管理主动管理:VACUUM自动管理:autovacuum process1.4 存储冗余1.4.1 物理冗余1.4.1.1 PITR1.4.1.2 流复制1.4.2 逻辑冗余1.4.2.1 publication/subscription1.4.2.2 pg_dump/pg_dumpall2. 高效的计算2.1 单个计算——SQL解析2.1.1 Parser2.1.2 Analyzer2.1.3 Rewriter2.1.4 PlanerScanNode (e.g.)JoinNode (e.g.)stats collector process2.1.6 Executor2.1.6.1 Pull模型2.1.6.2 Push2.2 多个计算——并发控制2.2.1 ACID2.2.2 锁2.2.2.1 加锁的方式2.2.2.2 锁类型2.2.2.3 MVCC3. 完备的监控3.1 系统表3.2 系统日志logger processcsv to table3.3 监控指标参考文献
图1. 数据库的主要模块(图来自论文Architecture of db)
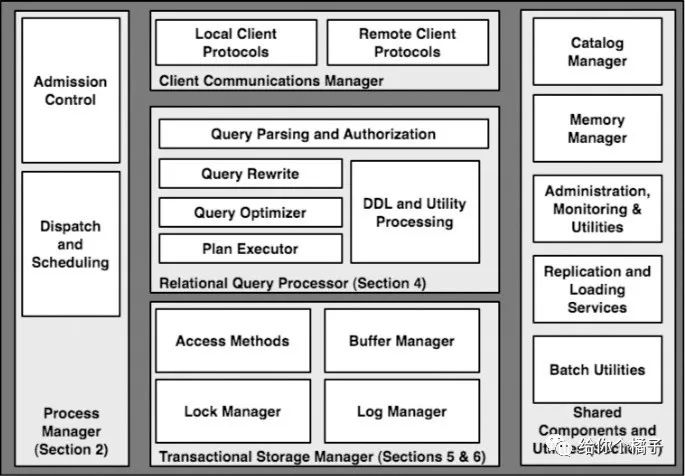
1. 有效的存储
计算机的存储介质主要有三种:disk,memory,cache;而cache是对上层透明的,我们只能做到了解各级cache的大小,写代码时适配cache大小的设计,尽量减少cache miss,但不能主动的操作cache;能主动操作的只有memory和disk,即通过控制指针和文件偏移(也有raw disk的方式,但基本还是通过OS FS来操作)来读写相应介质上的数据。
因此,数据库做到有效的存储,就是做到有效的利用好内存和磁盘,以及为了提高IO性能,在内存与磁盘之前加的缓冲区;
1.1 内存分配器
1.1.1 内存分配器简述
一般我们说的db内存管理,常常是指的buffer pool,在PostgreSQL中,就是shared_buffer;实际上,数据库系统中,还有一些需要内存的任务;比如,sort,hash,以及Selinger方式查询优化器中动态规划需要的额外空间;
内存管理一般是context-based方式的内存分配;这种方式可以方便地进行底层的垃圾回收,特别是在分阶段的查询执行中,上一阶段结束即可删除该上下文的内存空间,同时申请下一阶段的内存。另外,这种方式避免了多量小块内存的多次malloc/free调用,提高效率;
1.1.2 PostgreSQL的内存管理对象
在PostgreSQL中,内存管理一般指这些:
work_mem:太大,连接多了,占内存;太小,sort、hash计算慢;不用担心work_mem不够,可以降级用磁盘(temp_file_limit);
temp_buffers:临时表
maintenance_work_mem:维护进程的mem,可以比work_mem大一点
autovacuum_work_mem:特别维护进程:vacuum的mem,默认是maintenance_work_mem的大小
1.2 缓冲区管理
1.2.1 缓冲区管理器简述
All problems in computer science can be solved by another level of indirection
—— David Wheeler, fundamental theorem of software engineering
缓冲区是为了提高IO效率的一个中间层,db分配一个固定大小或可动态分配的内存空间作为buffer pool;
以disk page的大小作为一个单元,且和disk page的结构相同;这避免了读写时的Marshall/Unmarshall的cpu代价,以及避免了压缩展开带来的管理复杂度。
其实OS本身同样有一个buffer,但是OS的buffer关注的是性能,一般采用的是read-ahead/write-behind的方式;而DB除了控制数据的写在哪,更关键地是,还要控制写入的顺序。如果使用OS buffer,OS buffer可能会打乱DBMS的写入逻辑,这会有问题,违反ACID的正确性保证:
没有读写的时间顺序保证,就无法保证原子性恢复;
wal协议保证commit必须在wal写盘后,返回;
另外,double-buffer多一次内存拷贝,会带来性能问题:
Copy的时间
cpu的代价
污染cpu的cache
很多人认为相对于磁盘的操作,内存的操作代价不值一提;但是,DBMS的吞吐量有时并不是被IO限制的。
在DBMS中,其访问顺序由执行计划定义的,所以DB希望是自己准确控制磁盘的读写:在OS中提供了绕过os 文件系统buffer直接写磁盘的方法,比如fsync。
缓冲区管理中,往往有一个hash table的模块,包含了:
内存缓冲区的页号;
磁盘的存储位置;
相应页的一些元信息,比如脏页标记以及页面置换策略的一些信息;
在DB的页面置换算法上,由于DBMS不仅仅是最近访问,而是查询计划决定的。如果查询是全表扫描,会导致请出全部的buffer(表比buffer大的情况下),常规的LRU和Clock算法就不适用了,多数系统使用加强版的LRU,比如LRU-2,或者基于page类型采用不同的置换策略。
而现在64位内存已经很常见了,并且内存的价格也没那么贵了;大内存上的buffer,同时也带来管理的问题,以及recovery速度和checkpoint方式的考量。
1.2.2 PostgreSQL中的缓冲区管理对象
在PostgreSQL中,缓冲区中有这三类对象:
shared_buffers:shared_buffers设置通常是在OS内存的25%~40%之间;设置小了,当然会影响到db的性能;如果设置大了,会影响到checkpoint的速度,以及可能需要调大max_wal_size。
PostgreSQL的刷脏页有两个后台进程参与bgwriter checkpoint :
为了减少checkpoint对系统的影响,bgwriter定时(
bgwriter_delay
)地刷一下脏页;checkpointer定时(
checkpoint_timeout
)地,在wal日志中,记一个checkpoint记录,并开始进行存档;找到脏页
写脏页(可能在系统文件缓存中)
fsync到磁盘中 (
checkpoint_completion_target
,控制何时集中fsync)wal_buffers:一般是shared_buffers的1/32的大小,但是有个范围[64kB,
wal_segment_size
]。每次事务commit都会将wal_buffers写入磁盘,因此提高wal_buffer并没有太大的作用,只是当同时提交很多事务时,会提高写入性能。Wal日志的切换时机:
wal segment 满了
pg_switch_xlogarchive_mode
=on & archive_timeout
Commit LOG :pg_clog文件的缓存
1.3 访问方法
1.3.1 访问方法简介
访问方法,即访问磁盘的方法,即有两种——通过表访问和通过索引访问。
这里需要提到一点,当通过索引的方法访问时,如果过滤条件中,有索引建,明显返回的行数就不是全表,注意观察EXPLAIN命令,此时这个过滤条件叫Index Con,而不是Scan上的Filter。
1.3.2 PostgreSQL磁盘里的结构
1.3.2.1 PostgreSQL 数据库目录的结构
以PG10为例
drwx------ 6 postgres postgres 4096 Jan 22 15:54 base : 每个库的数据文件
-rw------- 1 postgres postgres 30 Jun 15 00:00 current_logfiles : 当前的日志文件
drwx------ 2 postgres postgres 4096 Jun 15 05:08 global : 系统表
drwx------ 2 postgres postgres 4096 Jan 28 00:00 log : 自己配置的日志位置
drwx------ 2 postgres postgres 4096 Jan 22 15:09 pg_commit_ts : 时间戳
drwx------ 2 postgres postgres 4096 Jan 22 15:09 pg_dynshmem : share mem用的文件
-rw-r--r-- 1 postgres postgres 1336 Apr 27 14:16 pg_hba.conf : 授权访问的白名单
-rw------- 1 postgres postgres 1636 Jan 22 15:09 pg_ident.conf : OS user和DB user的map
drwx------ 4 postgres postgres 4096 Jun 15 08:59 pg_logical : logical解码用的
drwx------ 4 postgres postgres 4096 Jan 22 15:09 pg_multixact : 多个事务shard row lock 状态
drwx------ 2 postgres postgres 4096 Jan 30 09:57 pg_notify : listen/notify
drwx------ 2 postgres postgres 4096 Jan 22 15:29 pg_replslot : replication slot
drwx------ 2 postgres postgres 4096 Jan 22 15:09 pg_serial : 串行化提交的事务
drwx------ 2 postgres postgres 4096 Jan 22 15:09 pg_snapshots : 两个事务使用同一个快照
# pg_export_snapshot()
# SET TRANSACTION SNAPSHOT snapshot_id
drwx------ 2 postgres postgres 4096 Jan 30 09:57 pg_stat : 统计信息的文件
drwx------ 2 postgres postgres 4096 Jun 15 09:29 pg_stat_tmp : 统计信息的临时文件
drwx------ 2 postgres postgres 20480 Jun 15 09:28 pg_subtrans : 子事务状态
drwx------ 2 postgres postgres 4096 Jan 22 15:09 pg_tblspc : tablespace的软连接
drwx------ 2 postgres postgres 4096 Jan 22 15:09 pg_twophase : 两阶段提交的prepare阶段
-rw------- 1 postgres postgres 3 Jan 22 15:09 PG_VERSION : 主版本号
drwx------ 3 postgres postgres 618496 Jun 15 08:59 pg_wal : 事务日志
drwx------ 2 postgres postgres 12288 Jun 15 09:19 pg_xact : commit log
-rw------- 1 postgres postgres 88 Jan 22 15:09 postgresql.auto.conf : alter system
-rw------- 1 postgres postgres 26715 Apr 24 02:12 postgresql.conf
-rw------- 1 postgres postgres 79 Jan 30 09:57 postmaster.opts
-rw------- 1 postgres postgres 118 Jan 30 09:57 postmaster.pid : pid/datadir/start_time/port/unix_socket_dir/listen_addr/shared_mem_seg_id复制
1.3.2.2 PostgreSQL 表文件的结构
一个table对应的物理文件:
[postgres@localhost 16385]$ ll 353947*
-rw------- 1 postgres postgres 11567104 Jun 15 09:51 353947
-rw------- 1 postgres postgres 24576 Jun 15 09:51 353947_fsm
-rw------- 1 postgres postgres 8192 Jun 15 09:51 353947_vm复制
353947_fsm(free space map):一个二叉树,叶子节点是某个页上的FreeSpace,一个字节代表一个页;上层节点是下层信息的汇总;用来在insert或者update的时候,找FreeSpace;
353947_vm(visibility map):一个bitmap,
1
代表页中的所有tuple对所有tranaction可见
353947 : Heap Table
堆表 vs 索引组织表
堆表,页中有新数据,直接插入进去就行,省去了调整索引的代价;但是索引上没有tmin tmax信息,tuple的事务可见性不知道,虽然可以通过vm来知道部分信息,但是还是不能避免二次读表;
相对应地,索引组织表表是一个有结构的东西,有结构就会有维护结构的代价;但是良好的结构能够提高查询的速度,但是前提是查询时按照这个结构来的;换句话说,索引组织表,对于按照主键来的查询效果比较好,但是如果表上的索引多了,利用二级索引的查询效果就没那么好;
但是,在大内存中,差别就没那么大了,不同场景可以测试一下;
1.3.2.3 PostgreSQL的页的结构
PageHeader:page中各个部分的偏移
iterm,对应的tuple的(offset,length)
free space
tuple
Special:如果是index页,可能需要这部分存储额外信息。
1.3.3 PostgreSQL 磁盘的管理
主动管理:VACUUM
VACUUM [FULL]
避免堆表的膨胀,清理dead tuple (FULL要加排他锁,重写表);VACUUM FREEZE
避免mvcc的xid回卷,冻结旧事物;VACUUM ANALYZE
统计信息更新
自动管理:autovacuum process
autovacuum间隔autovacuum_naptime
执行一次vacuum
和analyze
命令;但是,为了避免autovacuum对系统的影响,如果autovacuum的代价超过了autovacuum_vacuum_cost_limit
,那么就等autovacuum_vacuum_cost_delay
这些时间;
避免表膨胀:检测到某个表中的
update,deleted
超过autovacuum_vacuum_scale_factor*reltuples+autovacuum_vacuum_threshold
执行一次vacuum
;更新统计信息:
insert,update,deleted
超过autovacuum_analyze_scale_factor*reltuples+autovacuum_analyse_threshold
执行一次analyze避免xid回卷:表的
relfrozenxid
超过vacuum_freeze_min_age
时,vacuum就要进行freeze的操作,freeze的时候可以通过vm中的信息,来跳过一些page;而当relfrozenxid超vacuum_freeze_table_age
时,执行vacuum的时候,就不能跳过page,必须全表freeze;而当autovacuum_freeze_max_age
为了避免xid回卷,autovacuum freeze会强制执行;
1.4 存储冗余
冗余的容灾的最佳,也可能是唯一方式;有了冗余,就有了容灾的能力,同时也可以提高数据库的可用性。
1.4.1 物理冗余
整个数据库集簇的物理复制;
1.4.1.1 PITR
有一个某一时刻a的全量备份,以及之后的归档文件;就可以恢复到a之后的指定时间点;
BaseBackup:pg_basebackup命令,主要就是注意做热备的时候;wal_keep_segment可以的话,调大点
archiver process:两个占位符:%p %f;三个配置项:mode/command/timeout;注意开了归档,确保command是有效的,要不磁盘空间会被wal占满;
1.4.1.2 流复制
PostgreSQL可以级联流复制,所以在一个基于流复制的Cluster中,有以下三个角色
primary master
在这个节点上,一定要设置好wal_level
,这决定了整个集群的复制级别;10中有了logical,之前的archive和hot standby整合成replica了;如果采用同步提交打开,需要master上设置好synchronous_standby_names
(有first和any两种模式);
由于主从的查询不一样,用到的tuple也不一样;为了防止master把slave用到的tuple给清理了,可以设置一下vacuum_defer_cleanup_age
保留一定时间的老数据;也可以在slave中打开hot_standby_feedback
,来向master知会slave上的查询状态;但是,这两种方式都可能导致表膨胀,所以通过old_snapshot_threshold
强制设置一个老快照的上限;
cascaded slave
承接上下游的关键节点,压力还是不要太大的好
leaf slave
承接读流量
1.4.2 逻辑冗余
更细粒度的表级复制,目前支持的是update insert delete操作的同步,可以同步到另一个PG中,也可以通过第三方的中间件,订阅到kaffa中。在数据集成等场景中,很方便。
1.4.2.1 publication/subscription
publication:默认使用主键作为replication identity,没有主键必须指定一个唯一索引作为replication identity;要么只能full
REPLICA IDENTITY { DEFAULT | USING INDEX index_name | FULL | NOTHING }
复制另外,注意表结构的更改一定要同步(subscription publication);
subscription:指定publication的连接和pubname,就会在publication端创建一个logical replication slot,多个表可以共用一个slot;
1.4.2.2 pg_dump/pg_dumpall
常用的导出数据的命令,如果数据有坏块,得处理一下;全局的对象用dumpall,比如role等;
2. 高效的计算
2.1 单个计算——SQL解析
2.1.1 Parser
ParserTree,自己拿flex/bison
定义一个语法,就可以做语法解析了
2.1.2 Analyzer
QueryTree,就是把语法解析出来的tablename,columnname和数据库里的metadata对比一下
2.1.3 Rewriter
Rules:基于pg_rules这个用户自定义的规则,或者经验上的一些规则,比如视图展开,选择下推,重写查询;
2.1.4 Planer
PlanTree,基于代价估计的方式,选择节点算法和连接路径;
ScanNode (e.g.)
各种场景下,选择哪些Scan算法:Seq 、Index、Index-Only、bitmap-index;这里注意有时候索引多了会给PostgreSQL误导
JoinNode (e.g.)
nestloop、 hash、 sort-merge;PostgreSQL中的join算法还比较全,Mysql只有第一个;这也是为什么PostgreSQL在OLAP中表现比较好的原因之一;
stats collector process
该进程有个UDP端口,系统中的别的活动,往这里发消息来收集;
2.1.6 Executor
2.1.6.1 Pull模型
PostgreSQL等常见的DB中,基本都是Pull模型;
This fact is often a surprise to people who have not operated or implemented a database system, and assume that main-memory operations are “free” compared to disk I/O. But in practice, throughput in a well-tuned transaction processing DBMS is typically not I/O-bound.
—— Hellerstein, Architecture of a Database System
每个节点实现hasNext(), Next()
接口,从上往下逐级pull。这种模型产生时,也是一开始造出DB系统的年代,那时IO代价比CPU代价高;
在这种模型中,每个tuple都需要一个next调用;其次,这个next的调用往往是一个虚拟函数或者函数指针的方式,因此,这种方式的代码本地性(code locality)也不好;并且会有复制的虚拟函数和函数指针记录的逻辑(book-keeping);整体CPU代价比较高。
code locality:
类似于数据缓存,利用数据访问的局部性,可以提高性能;代码的执行也是一行一行的,代码也是需要加载的,跳来跳去不太好;就比如在代码中,尽量少用goto控制语句,鼓励使用顺序,循环和分支来处理;

2.1.6.2 Push
在Push中,查询计划中有一些materialization points,也叫pipeline breaks;数据不是从前往后拉,是从后向前推,直到遇到某个pipeline breaks;如下图,原来的执行计划,分成了四段;
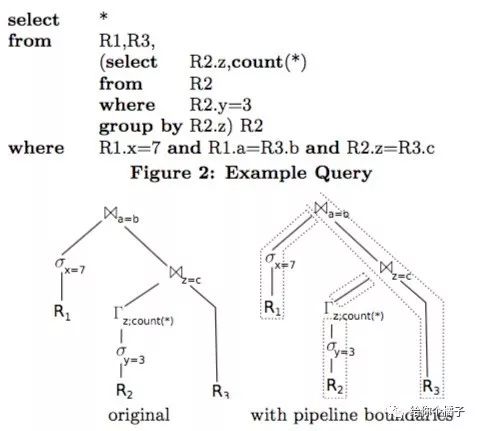
2.2 多个计算——并发控制
2.2.1 ACID
原子:事务要么成功,要么失败;关注的是事务的状态只有两种:commit和aborted
一致:整个db的数据,从外部看总是一致的;事务处理的中间状态,对外是不可见的;这是要求的强一致性,需要严格加锁;
隔离:太强的一致性,带来性能的损失;适当的降低隔离性,提高性能;
持久:先写日志,后写数据
2.2.2 锁
2.2.2.1 加锁的方式
Pre-claiming Lock
在事务开始执行前,请求所需要的对象上的所有的锁;请求失败,就回滚;
Two-Phase Locking 2PL
事务关于锁有两个阶段,第一个阶段:只加锁,不放锁;当有一个锁被释放了,进入第二个阶段:只放锁,不加锁;
这种方式的2PL,由于咩有严格的隔离型,会导致cascading abort:提前释放了修改好的对象上的锁,别的事务可见了,这样如果当前事务回滚了,那么这些相关的事务,都要回滚
Strict Two-Phase Locking
和2PL的不同就是,锁保持到事务结束,一次性释放;不会有cascading abort;
2PL,由于有一个持有部分锁,并等待其他锁的过程;这有可能会导致死锁;更保守的2PL协议Conservative 2-PL 可以避免这个问题,但是实际上很少使用这个方式;了解一下。。。
时间戳排序协议
每个事务有一个开始的时间戳:TS(Ti);每个数据有一个读时间戳:R-ts(X),和一个写时间戳:W-ts(X);时间戳排序控制协议如下:
如果事务Ti要读数据X
If TS(Ti) < W-ts(X)
Operation rejected.
If TS(Ti) >= W-ts(X)
Operation executed.
All data-item timestamps updated.复制写了之后才能读;
如果事务Ti要写数据X
If TS(Ti) < R-ts(X)
Operation rejected.
If TS(Ti) < W-ts(X)
Operation rejected and Ti rolled back.
Otherwise, operation executed.复制数据的任何操作之后,才能写;并且老的写事务会被新的写事务忽略,这叫Thomas' Write Rule;
Graph Based Protocol
2PL只是保证了事务的Strict Schedule;但是没有保证deadlock free;Graph Based Protocol是一个可选方案,tree based Protocol是一个简单的实现;比较复杂了,没细看;
2.2.2.2 锁类型
主要有两种类型,排他和共享的;但是根据锁的粒度不同,显式的有表和行两个级别;对程序不可见的还有页上的锁,也叫闩(latch);同时,数据并发访问大的时候,也有咨询锁;最后就是死锁了。关于锁的另一篇:http://yummyliu.github.io/jekyll/update/2018/05/30/lock-PostgreSQL/
2.2.2.3 MVCC
PostgreSQL的MVCC是PostgreSQL的诸多亮点的其中一个(关于mvcc的另一篇: http://yummyliu.github.io/jekyll/update/2018/05/30/MvccAndVacuum/),MVCC简单说就是数据带上了版本号,这样不同的事务只能看到自己版本的数据。关于PostgreSQL的快照隔离,有一篇论文Serializable Snapshot Isolation。
3. 完备的监控
3.1 系统表
table:基本就是一些PostgreSQL中的一些概念的元信息,pg_trigger pg_type/ pg_class/ pg_index/ pg_sequence 等等。
view:基于系统表或函数上的一个系统视图,pg_stat_*
3.2 系统日志
logger process
where
log_destination:stderr, csvlog , syslog;csvlog需要
logging_collector = onlog_directory:
log_filename
when
log_min_duration_statement
what
log_connections
log_checkpoints
log_duration
log_lock_waits
log_statement
log_temp_files
csv to table
CREATE TABLE postgres_log
(
log_time timestamp(3) with time zone,
user_name text,
database_name text,
process_id integer,
connection_from text,
session_id text,
session_line_num bigint,
command_tag text,
session_start_time timestamp with time zone,
virtual_transaction_id text,
transaction_id bigint,
error_severity text,
sql_state_code text,
message text,
detail text,
hint text,
internal_query text,
internal_query_pos integer,
context text,
query text,
query_pos integer,
location text,
application_name text,
PRIMARY KEY (session_id, session_line_num)
);
COPY postgres_log FROM '/full/path/to/logfile.csv' WITH csv;复制
cluster_name;一个机器上多个实例,可以区分一下;
3.3 监控指标
结合pgwatch的一些常规监控指标整理
参考文献
PostgreSQL监控指标整理
Concurrency Control
architecture of db
Adaptive Query Processing
Pull&push
