




最近复习MySQL把笔记重新梳理了一下,整理成了一份易于背诵的笔记,嗯,没错就是易于背诵,面试就得背。
内容有点多,除了B+树以外的我认为重要的内容都在这里面了,所以可能得分几次发出来,先发个一波吧。
数据库事务是什么?
事务是指满足ACID特性的一组操作。ACID分别是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。原子性是指一组操作要么全部成功,要么全部失败。一致性是指事务的执行不能破坏数据的完整性和一致性,数据是从一个一致的状态转移到另一个一致的状态。隔离性是指并发执行的事务相互之间不可见,一个事务在提交之前始终对其他事务不可见。持久性是指事务提交后所有的修改都会永久保存到数据库中,即使发生数据库崩溃或是机器宕机。
数据库三范式是什么?
说到数据库范式,就不得不说到键(码)的定义:如果集合A1-An是一个或多个属性的集合,该集合函数决定了关系的其它所有属性并且是最小的,那么该集合就称为键码。
第一范式的定义是属性不可分。第二范式的定义是非主属性完全函数依赖于键(码),不能是部分函数依赖。第三范式的定义是非主属性不传递函数依赖于键(码)。
有哪几种隔离级别?各自存在什么问题?
隔离级别包括读未提交、读提交、可重复读、可串行化四种。读未提交存在脏读、不可重复读和幻读问题。读提交存在不可重复读(侧重的是“修改“,同样的查询语句,前后执行返回的值不一致)和幻读问题。可重复读存在幻读问题(侧重的是“新增”或“删除”,同样的查询语句,前后执行返回的行数不一致)。可串行化因为每次都会加锁所以不存在并发一致性问题。
Delete/Truncate/Drop三者的区别?
这三者的区别主要体现在四个方面:执行效果、是否支持事务、空间占用、执行效率。Delete用来删除行,可以激活触发器,支持事务,不会释放磁盘空间,速度最慢。Truncate用来清空表,不支持事务,会将表和索引占用的空间恢复到初始值,速度较快。Drop用来删除表和数据,不支持事务,删除数据的同时会释放占用的空间,速度最快。
InnoDB和MyISAM的区别?
InnoDB支持事务,MyISAM不支持。InnoDB支持行级锁,MyISAM只支持表级锁。
InnoDB索引即数据,聚簇索引上保存着所有的数据。MyISAM索引和数据分离,所有的索引都是二级索引。InnoDB是通过二级索引先查到主键,再通过主键查询数据,而MyISAM索引中存储的是数据文件的索引偏移量,因此MyISAM回表效率更高,但是相对的维护代价也更高。
InnoDB不保存表的行数,使用COUNT(*)时需要扫描全表,MyISAM保存了表的行数,查询时直接返回即可。
InnoDB主要面向在线事务处理(OLTP)的数据库应用,而MyISAM主要面向联机分析处理(OLAP)的数据库应用。
MVCC是什么?
MVCC(Multi-Version Concurrency Control),多版本并发控制,主要用于提高系统并发度。在早期的数据库系统中,只有读读之间不冲突,读写、写读、写写之间都是冲突的,需要加锁访问数据。引入MVCC功能后,读写和写读就都可以并发进行了。
MVCC在READ COMMITTED、REPEATABLE READ和SERIALIZABLE级别下都可以工作,不过由于SERIALIZABLE级别较少使用到,所以大多数情况下MVCC都是工作在RC和RR级别下,这种场景比较好理解,就是使用数据版本链来访问历史版本数据。不过说MVCC也会工作在SERIALIZABLE级别下可能会让人有点困惑,不是说SERIALIZABLE级别下都是加锁访问吗?
这么说确实没错,但是有个例外。SERIALIZABLE级别下,开启自动提交时,由于每个事务都只包含一条SQL语句,所以不会存在不可重复读和幻读问题,因此也就可以使用MVCC来读取数据。关闭自动提交时,每次SELECT都会在记录上加读锁。
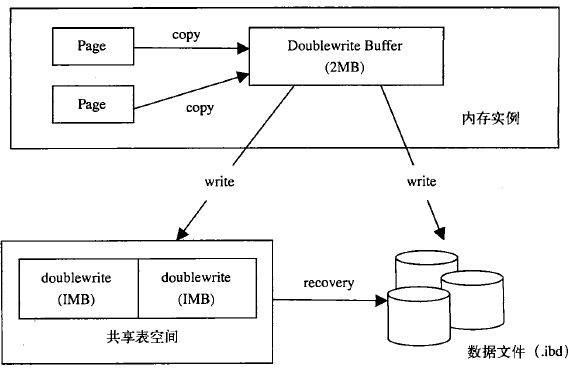
doublewrite是什么?
说到doublewrite就不得不说部分写失效问题,部分写失效问题说的是,当系统正在从内存向磁盘写一个数据页时,数据库宕机,导致数据页只写入了部分数据的情况。这时候磁盘上对应的数据页实际已经损坏(File Header和File Trailer校验值不一致),重做日志记录的是对数据页的物理修改,如果数据页已经损坏,那么重做日志也无能为力。
doublewrite主要是用来提高InnoDB的数据可靠性,解决部分写失效问题。Doublewrite Buffer是内存中一个大小为2M的缓冲区,在磁盘共享表空间中有一个对应的大小也为2M的存储空间。InnoDB在将数据页写入磁盘文件之前,会先把数据页拷贝到两次写缓冲区,接着从两次写缓冲区中分两次写入共享表空间,每次写入1M。上一步完成后,再将两次写缓冲区写入磁盘文件。
另外,还可以通过两次写特性观察当前系统的负载情况,如果发现 Innodb_dblwr_pages_written Innodb_dblwr_writes 的比值为 64/1,那说明当前系统负载很高,反之则说明当前系统负载不高。
刷脏页的时机?
redo log被写满,必须推进checkpoint,此时所有写入都会阻塞。
内存不足,必须淘汰一部分数据页,注意innodb_flush_neighbors机制,8.0之前的版本都会顺带把临近的脏页一起刷盘。
后台线程定时刷
MySQL正常关闭
如何控制刷脏页的速度?
innodb_io_capacity用于告诉InnoDB所在系统的磁盘能力,该属性配置的值越大,脏页刷新速度越快,但是要注意平衡读取和写入。
innodb_flush_neighbors配置开启时会在刷脏页时顺带把临近的脏页一起刷盘,这时候脏页刷盘可能会比较慢,这属于机械硬盘时代的遗留配置,如果使用SSD硬盘的话,该配置不建议开启,反而会影响系统性能。
崩溃恢复过程会做哪些事情?
崩溃恢复时,如果redo log里的事务处于commit状态,该事务会被提交。如果redo log里的事务处于prepare状态,并且存在binlog,该事务会被提交,如果不存在binlog的话,事务会被回滚。
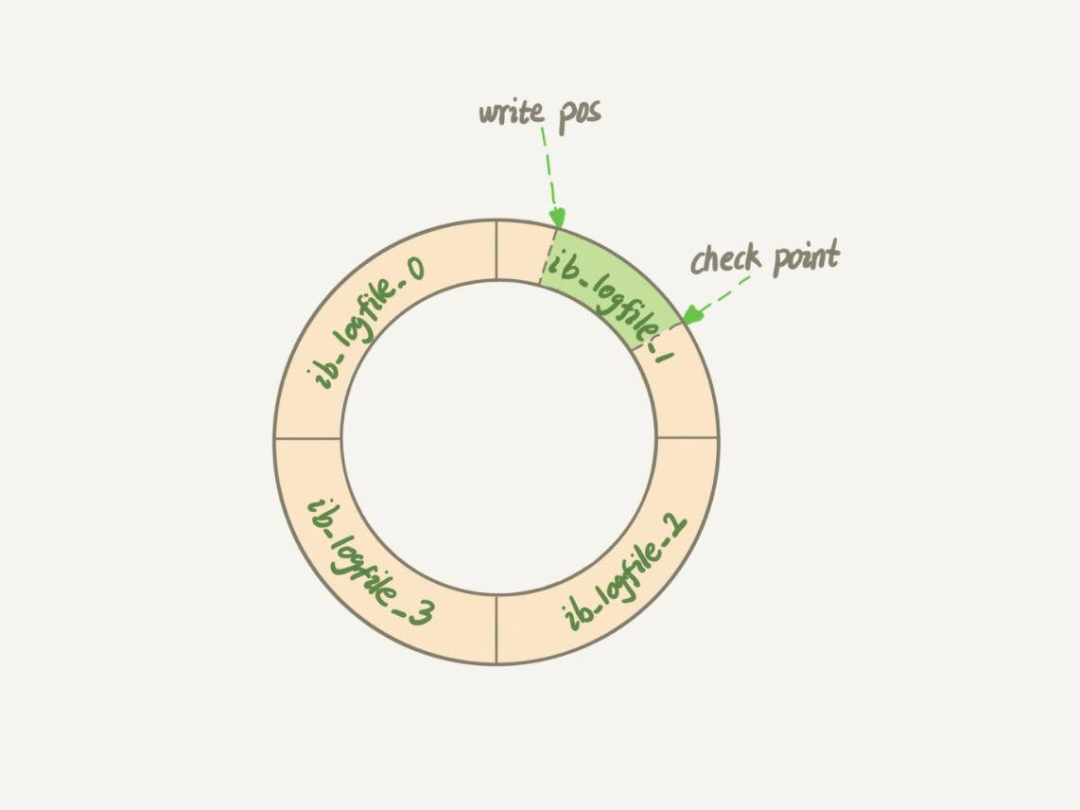
binlog是归档文件,会不断追加写入。redo log和binlog不一样,redo log在磁盘上的存储空间是一块固定大小、循环写入的存储空间。对于redo log,有write pos和checkpoint这两个关键位置,write pos和checkpoint之间是可以写入的空间。
崩溃恢复时,checkpoint之前的数据肯定已经刷盘,checkpoint之后的数据则无法确定,因为在上一次做checkpoint之后可能有一部分脏页已经刷盘。可以通过数据页header中的page_lsn来判断数据页是否已经刷盘,如果该页在上次做完checkpoint之后刷过盘,那数据页的page_lsn肯定大于当前checkpoint_lsn,这种数据页就可以直接跳过。
在崩溃恢复的过程中,为了提高恢复效率,InnoDB使用哈希表将同一个页面的redo log串了起来,这样在恢复的过程中就可以避免很多读取页面的随机IO,加快了恢复的速度。
我们知道崩溃恢复是从checkpoint位置开始的,那读取到什么位置停止呢?普通block的header部分有一个data_len字段用于记录当前block的空间使用情况,对于已经填满的block来说,该值永远为512,如果该值不为512,说明日志到这里就结束了,那么读取到该block停止即可。
Buffer Pool的LRU链表?
InnoDB的LRU链表分为young和old两个区域,热数据放在young区域,冷数据放在old区域,默认情况下old区域大概占LRU链表的3/8。可以通过参数innodb_old_blocks_pct来调整old区域占用的比例,首次从磁盘加载的数据页会被放在old区域的头部,在innodb_old_blocks_time(ms)间隔时间内重复访问数据页不会导致数据页从old区域移动到young区域。在buffer pool没有空闲的可用缓存页时,会首先淘汰old区域的数据页。
全表扫描时,由于磁盘预读特性的存在,磁盘数据首次加载到缓存页时,虽然会被放到old区域,但是后续马上会被访问到。针对这种情况,为了避免young区域的热数据被淘汰,所以才引入了innodb_old_blocks_time机制。
长事务导致内存溢出的原因是什么?
说到事务肯定绕不开undo log,undo log是实现数据库原子性和MVCC机制的关键。我们知道聚簇索引数据行里有三个隐藏字段:trx_id、roll_pointer、row_id,undo log记录是通过roll_pointer串起来的,trx_id记录的是该记录最后一次修改时的事务id。这是前提。
可重复读级别下,会在事务开始时创建ReadView视图,视图会有一个对应的trx_id。正常情况下,ReadView会在事务提交或回滚后消失,也就是说,系统活跃视图对应的最小的trx_id会不断递增,在这个过程中,后台线程就可以定期删除系统中不再需要的undo log记录(也就是记录trx_id小于现有活跃视图中最小trx_id的记录)。
但是假如我们开启了一个事务后,长期不关闭,就会导致系统活跃视图对应的最小的trx_id无法向前推进,后台线程也就无法删除历史版本的undo log记录,即使那些记录再也不会被访问到。当积累的数据大到一定程度,必然就会导致内存溢出。
如何防止大数据量下翻页性能急剧下降?
有三种方式可以避免这个问题,第一种简单粗暴,直接在业务上禁止查询太靠后的数据。第二种是把上一次查询结果中最大的id作为下一页的查询参数,利用索引实现稳定的查询性能。第三种是延迟关联,先利用索引查出id,再根据id回表查询。
暂时先发这些哈,觉得还行可以点一波在看,有问题可以直接找我或者公众号留言,感谢。
