




MongoDB分片迁移原理与源码
move chunk
moveChunk 是一个比较复杂的动作, 大致过程如下: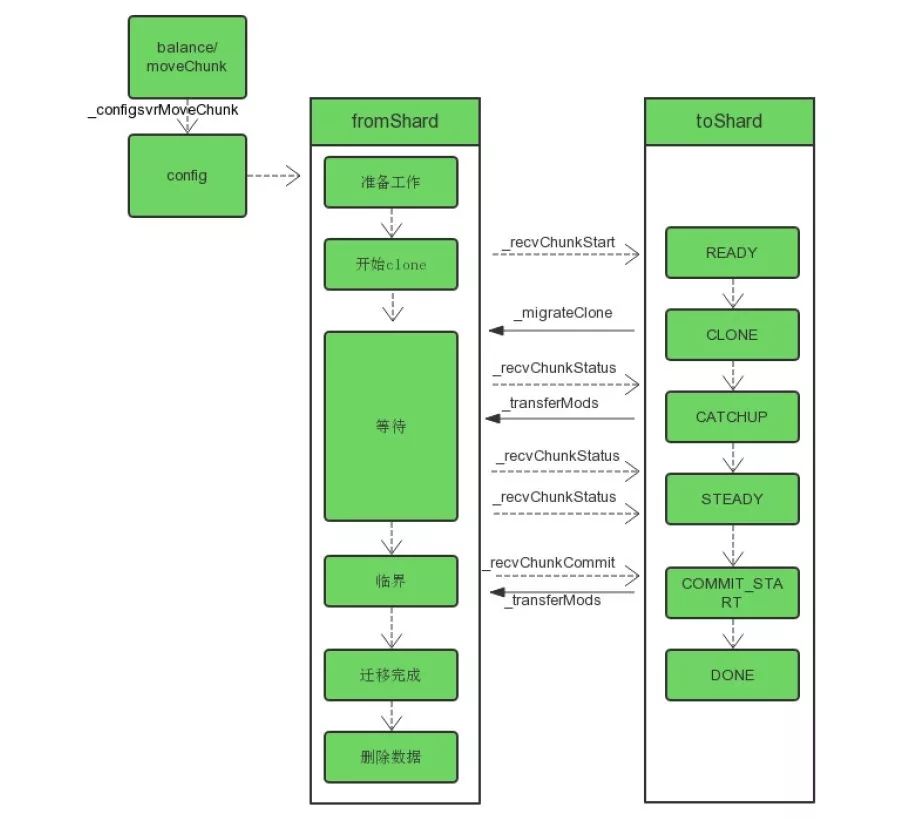
基于对应一开始介绍的块迁移流程
执行moveChunk有一些参数,比如在_moveChunks调用MigrationManager::executeMigrationsForAutoBalance()时,
balancerConfig->getSecondaryThrottle(),返回的为_secondaryThrottle: 变量,true 表示 balancer 插入数据时,至少等待一个 secondary 节点回复;false 表示不等待写到 secondary 节点;也可以直接设置为 write concern ,则迁移时使用这个 write concern . 3.2 版本默认 true, 3.4 开始版本默认 false。
balancerConfig->waitForDelete(),返回的为waitForDelete,迁移一个 chunk 数据以后,是否同步等待数据删除完毕;默认为 false , 由一个单独的线程异步删除孤儿数据。
config服务器
int Balancer::_moveChunks(OperationContext* opCtx,
const BalancerChunkSelectionPolicy::MigrateInfoVector& candidateChunks) {
auto migrationStatuses =
_migrationManager.executeMigrationsForAutoBalance(opCtx,
candidateChunks,
balancerConfig->getMaxChunkSizeBytes(),
balancerConfig->getSecondaryThrottle(),
balancerConfig->waitForDelete());
}复制
executeMigrationsForAutoBalance()函数会将所有需要迁移的块信息(from shard, to shard, chunk)信息构造一个块迁移任务请求发送给from shard,然后由from shard执行后续的move chunk流程。
MigrationStatuses MigrationManager::executeMigrationsForAutoBalance(
OperationContext* opCtx,
const vector<MigrateInfo>& migrateInfos,
uint64_t maxChunkSizeBytes,
const MigrationSecondaryThrottleOptions& secondaryThrottle,
bool waitForDelete) {
//将每一个需要处理的块迁移操作分别创建迁移任务请求发送到from shard
for (const auto& migrateInfo : migrateInfos) {
//向config.migrations中写入一个文档,防止此迁移必须由平衡器恢复。如果块已经在移动,则迁移下一个。
auto statusWithScopedMigrationRequest =
ScopedMigrationRequest::writeMigration(opCtx, migrateInfo, waitForDelete);
if (!statusWithScopedMigrationRequest.isOK()) {
migrationStatuses.emplace(migrateInfo.getName(),
std::move(statusWithScopedMigrationRequest.getStatus()));
continue;
}
scopedMigrationRequests.emplace(migrateInfo.getName(),
std::move(statusWithScopedMigrationRequest.getValue()));
//将一个块迁移操作加入到调度
responses.emplace_back(
_schedule(opCtx, migrateInfo, maxChunkSizeBytes, secondaryThrottle, waitForDelete),
migrateInfo);
}
//等待所有的迁移任务结束,更新
for (auto& response : responses) {
//......
}
}复制
之后,会创建一个远程调用命令给from shard,去触发迁移流程
shared_ptr<Notification<RemoteCommandResponse>> MigrationManager::_schedule(
OperationContext* opCtx,
const MigrateInfo& migrateInfo,
uint64_t maxChunkSizeBytes,
const MigrationSecondaryThrottleOptions& secondaryThrottle,
bool waitForDelete) {
//......
//构造"moveChunk"命令
BSONObjBuilder builder;
MoveChunkRequest::appendAsCommand(
&builder,
nss,
migrateInfo.version,
repl::ReplicationCoordinator::get(opCtx)->getConfig().getConnectionString(),
migrateInfo.from,
migrateInfo.to,
ChunkRange(migrateInfo.minKey, migrateInfo.maxKey),
maxChunkSizeBytes,
secondaryThrottle,
waitForDelete);
Migration migration(nss, builder.obj());
//发送到fromHostStatus.getValue()对应的from shard执行该moveChunk操作。
_schedule(lock, opCtx, fromHostStatus.getValue(), std::move(migration));
}复制
至此,后续的迁移任务就由from shard和to shard来执行了
from shard
迁移任务由from shard执行moveChunk命令,来完成迁移。
class MoveChunkCommand : public BasicCommand {
public:
MoveChunkCommand() : BasicCommand("moveChunk") {}
bool run(OperationContext* opCtx,
const std::string& dbname,
const BSONObj& cmdObj,
BSONObjBuilder& result) override {
_runImpl(opCtx, moveChunkRequest);
}
}复制
from端迁移状态机。此对象必须由单个线程创建和拥有,该线程控制其生存期,不应该跨线程传递。除非明确指出它的方法不能被一个以上的线程调用,也不能在持有任何锁时调用。
工作流程如下:
获取即将移动数据块的集合的分布式锁。
在堆栈上实例化一个MigrationSourceManager。这将快照最新的收集元数据,由于分布式收集锁,这些元数据应该保持稳定。
调用startClone启动块内容的后台克隆。这将执行复制子系统对克隆程序的必要注册,并开始监听文档更改,同时响应来自接收者的数据获取请求。
调用awaitUntilCriticalSectionIsAppropriate以等待克隆过程充分赶上,所以我们不会保持服务器在只读状态太长时间。
调用enterCriticalSection使碎片进入“只读”模式,而最新的更改将由to shard处理完毕。
调用commitDonateChunk将此次迁移结果提交到config服务器,并保持只读(临界区)模式。
几个阶段的状态为:enum State { kCreated, kCloning, kCloneCaughtUp, kCriticalSection, kCloneCompleted, kDone };
static void _runImpl(OperationContext* opCtx, const MoveChunkRequest& moveChunkRequest) {
//根据config传过来的_secondaryThrottle来处理是否插入数据时,至少等待一个 secondary 节点回复
const auto writeConcernForRangeDeleter =
uassertStatusOK(ChunkMoveWriteConcernOptions::getEffectiveWriteConcern(
opCtx, moveChunkRequest.getSecondaryThrottle()));
// Resolve the donor and recipient shards and their connection string
auto const shardRegistry = Grid::get(opCtx)->shardRegistry();
//获取from shard的连接串
const auto donorConnStr =
uassertStatusOK(shardRegistry->getShard(opCtx, moveChunkRequest.getFromShardId()))
->getConnString();
//获取to shard的连接信息
const auto recipientHost = uassertStatusOK([&] {
auto recipientShard =
uassertStatusOK(shardRegistry->getShard(opCtx, moveChunkRequest.getToShardId()));
return recipientShard->getTargeter()->findHostNoWait(
ReadPreferenceSetting{ReadPreference::PrimaryOnly});
}());
moveTimingHelper.done(1);
MONGO_FAIL_POINT_PAUSE_WHILE_SET(moveChunkHangAtStep1);
/*使用指定的迁移参数实例化新的迁移源管理器。必须使用预先获得的分布式锁来调用(而不是断言)。加载最新的集合元数据并将其用作起点。由于分布式锁,集合的元数据不会进一步更改。*/
//kCreated
MigrationSourceManager migrationSourceManager(
opCtx, moveChunkRequest, donorConnStr, recipientHost);
moveTimingHelper.done(2);
MONGO_FAIL_POINT_PAUSE_WHILE_SET(moveChunkHangAtStep2);
//kCloning
uassertStatusOKWithWarning(migrationSourceManager.startClone(opCtx));
moveTimingHelper.done(3);
MONGO_FAIL_POINT_PAUSE_WHILE_SET(moveChunkHangAtStep3);
//kCloneCaughtUp
uassertStatusOKWithWarning(migrationSourceManager.awaitToCatchUp(opCtx));
moveTimingHelper.done(4);
MONGO_FAIL_POINT_PAUSE_WHILE_SET(moveChunkHangAtStep4);
//kCriticalSection
uassertStatusOKWithWarning(migrationSourceManager.enterCriticalSection(opCtx));
uassertStatusOKWithWarning(migrationSourceManager.commitChunkOnRecipient(opCtx));
moveTimingHelper.done(5);
MONGO_FAIL_POINT_PAUSE_WHILE_SET(moveChunkHangAtStep5);
//kCloneCompleted
uassertStatusOKWithWarning(migrationSourceManager.commitChunkMetadataOnConfig(opCtx));
moveTimingHelper.done(6);
MONGO_FAIL_POINT_PAUSE_WHILE_SET(moveChunkHangAtStep6);
}复制
Status MigrationSourceManager::startClone(OperationContext* opCtx) {
/*将元数据管理器注册到集合分片状态表示正在迁移该集合上的块。对于主动迁移,写操作要求克隆程序在场,以便跟踪需要传输给接收方的块的更改。*/
_cloneDriver = stdx::make_unique<MigrationChunkClonerSourceLegacy>(
_args, metadata->getKeyPattern(), _donorConnStr, _recipientHost);
Status startCloneStatus = _cloneDriver->startClone(opCtx);
_state = kCloning;
}
Status MigrationChunkClonerSourceLegacy::startClone(OperationContext* opCtx) {
auto const replCoord = repl::ReplicationCoordinator::get(opCtx);
if (replCoord->getReplicationMode() == repl::ReplicationCoordinator::modeReplSet) {
_sessionCatalogSource =
stdx::make_unique<SessionCatalogMigrationSource>(opCtx, _args.getNss());
//如果有要迁移的oplog条目,则启动会话迁移源。
_sessionCatalogSource->fetchNextOplog(opCtx);
}
//加载当前可用文档的id
auto storeCurrentLocsStatus = _storeCurrentLocs(opCtx);
if (!storeCurrentLocsStatus.isOK()) {
return storeCurrentLocsStatus;
}
//告诉接收碎片开始克隆,构造"_recvChunkStart"请求发送到to shard
BSONObjBuilder cmdBuilder;
StartChunkCloneRequest::appendAsCommand(&cmdBuilder,
_args.getNss(),
_sessionId,
_donorConnStr,
_args.getFromShardId(),
_args.getToShardId(),
_args.getMinKey(),
_args.getMaxKey(),
_shardKeyPattern.toBSON(),
_args.getSecondaryThrottle());
auto startChunkCloneResponseStatus = _callRecipient(cmdBuilder.obj());
}复制
from shard发送完“recvChunkStart”命令后,进入kCloning状态,随即进入awaitToCatchUp函数,一直发送"recvChunkStatus"命令到to shard,等待to shard进入"steady"状态,再进行下一步;或失败;或超时。
Status MigrationSourceManager::awaitToCatchUp(OperationContext* opCtx) {
// Block until the cloner deems it appropriate to enter the critical section.
Status catchUpStatus = _cloneDriver->awaitUntilCriticalSectionIsAppropriate(
opCtx, kMaxWaitToEnterCriticalSectionTimeout);
if (!catchUpStatus.isOK()) {
return catchUpStatus;
}
_state = kCloneCaughtUp;
}
Status MigrationChunkClonerSourceLegacy::awaitUntilCriticalSectionIsAppropriate(
while ((Date_t::now() - startTime) < maxTimeToWait) {
auto responseStatus = _callRecipient(
createRequestWithSessionId(kRecvChunkStatus, _args.getNss(), _sessionId, true));
const BSONObj& res = responseStatus.getValue();
if (res["state"].String() == "steady") {
if (cloneLocsRemaining != 0) {
return {ErrorCodes::OperationIncomplete,
str::stream() << "Unable to enter critical section because the recipient "
"shard thinks all data is cloned while there are still "
<< cloneLocsRemaining
<< " documents remaining"};
}
return Status::OK();
}
}
}复制
在to shard进行了READY, CLONE, CATCHUP, STEADY状态变化后,进入steady后,表明to shard完成了数据块上数据的复制,以及完成了复制期间新写的数据的同步,则from shard就可以进入下一个阶段"kCriticalSection"了。
Status MigrationSourceManager::enterCriticalSection(OperationContext* opCtx) {
//表明当前分片上的该集合进入X锁阶段,这将导致该集合不能再进行任何写操作,直到chunk迁移提交
_critSec.emplace(opCtx, _args.getNss());
_state = kCriticalSection;
}复制
进入不可写阶段后,from shard会发送"_recvChunkCommit"命令,告知to shard去获取最后一次的修改并提交整个迁移过程。
Status MigrationSourceManager::commitChunkOnRecipient(OperationContext* opCtx) {
//发送"_recvChunkCommit"命令
auto commitCloneStatus = _cloneDriver->commitClone(opCtx);
_state = kCloneCompleted;
}复制
收到to shard正确提交的回复后,from shard也将所有的修改结果提交到config服务器
Status MigrationSourceManager::commitChunkMetadataOnConfig(OperationContext* opCtx) {
//构造"_configsvrCommitChunkMigration"命令,提交相关数据给config服务器
BSONObjBuilder builder;
{
ChunkType migratedChunkType;
migratedChunkType.setMin(_args.getMinKey());
migratedChunkType.setMax(_args.getMaxKey());
CommitChunkMigrationRequest::appendAsCommand(
&builder,
getNss(),
_args.getFromShardId(),
_args.getToShardId(),
migratedChunkType,
controlChunkType,
metadata->getCollVersion(),
LogicalClock::get(opCtx)->getClusterTime().asTimestamp());
builder.append(kWriteConcernField, kMajorityWriteConcern.toBSON());
}
//保持X锁
_critSec->enterCommitPhase();
//发送命令给config服务器
auto commitChunkMigrationResponse =
Grid::get(opCtx)->shardRegistry()->getConfigShard()->runCommandWithFixedRetryAttempts(
opCtx,
ReadPreferenceSetting{ReadPreference::PrimaryOnly},
"admin",
builder.obj(),
Shard::RetryPolicy::kIdempotent);
//提交成功,释放X锁
_cleanup(opCtx);
//异步删除。根据上边的介绍,是否异步删除是可配置的。通过调用cleanUpRange来实现删除数据,如果异步删除,调用完毕就进行下一个chunk的迁移了
auto notification = [&] {
auto const whenToClean = _args.getWaitForDelete() ? CollectionShardingRuntime::kNow
: CollectionShardingRuntime::kDelayed;
UninterruptibleLockGuard noInterrupt(opCtx->lockState());
AutoGetCollection autoColl(opCtx, getNss(), MODE_IS);
return CollectionShardingRuntime::get(opCtx, getNss())->cleanUpRange(range, whenToClean);
}();
}复制
config服务器要进行最后数据的提交确认.
"_configsvrCommitChunkMigration"命令获取正在迁移的块(“migratedChunk”),并为其生成一个新版本,该版本连同它的新碎片位置(“toShard”)一起写入到块集合中。它还接受一个控制块(“controlChunk”)并为其分配一个新版本,以便源碎片(“fromShard”)碎片的shardVersion将增加。如果没有控制块,那么正在迁移的块就是源碎片惟一剩下的块。新的块版本是通过查询集合的最高块版本生成的,然后对已迁移块和控制块的主值进行递增,并将已迁移块的次值设置为0,控制块设置为1。在生成新块版本和写入块集合的过程中,将持有一个全局独占锁,这样就不会产生块集合。这确保生成的ChunkVersions是严格单调递增的——第二个进程在第一个进程写完它生成的最高块版本之前,将无法查询最大块版本。
class ConfigSvrCommitChunkMigrationCommand : public BasicCommand {
public:
ConfigSvrCommitChunkMigrationCommand() : BasicCommand("_configsvrCommitChunkMigration") {}
bool run(OperationContext* opCtx,
const std::string& dbName,
const BSONObj& cmdObj,
BSONObjBuilder& result) override {
// Set the operation context read concern level to local for reads into the config database.
repl::ReadConcernArgs::get(opCtx) =
repl::ReadConcernArgs(repl::ReadConcernLevel::kLocalReadConcern);
const NamespaceString nss = NamespaceString(parseNs(dbName, cmdObj));
auto commitRequest =
uassertStatusOK(CommitChunkMigrationRequest::createFromCommand(nss, cmdObj));
StatusWith<BSONObj> response = ShardingCatalogManager::get(opCtx)->commitChunkMigration(
opCtx,
nss,
commitRequest.getMigratedChunk(),
commitRequest.getCollectionEpoch(),
commitRequest.getFromShard(),
commitRequest.getToShard(),
commitRequest.getValidAfter());
uassertStatusOK(response.getStatus());
result.appendElements(response.getValue());
return true;
}
}复制
to shard
然后来到to shard收到"_recvChunkStart"命令请求,然后to shard开始复制数据。
to shard的整个迁移过程包含如下阶段:enum State { READY, CLONE, CATCHUP, STEADY, COMMIT_START, DONE, FAIL, ABORT };
class RecvChunkStartCommand : public ErrmsgCommandDeprecated {
public:
RecvChunkStartCommand() : ErrmsgCommandDeprecated("_recvChunkStart") {}
bool errmsgRun(OperationContext* opCtx,
const std::string& dbname,
const BSONObj& cmdObj,
std::string& errmsg,
BSONObjBuilder& result) override {
//......
//进入从源端拷贝数据的准备工作,以及实施后续的所有迁移操作
uassertStatusOK(
MigrationDestinationManager::get(opCtx)->start(opCtx,
nss,
std::move(scopedReceiveChunk),
cloneRequest,
shardVersion.epoch(),
writeConcern));
result.appendBool("started", true);
return true;
}
}
Status MigrationDestinationManager::start(OperationContext* opCtx,
const NamespaceString& nss,
ScopedReceiveChunk scopedReceiveChunk,
const StartChunkCloneRequest cloneRequest,
const OID& epoch,
const WriteConcernOptions& writeConcern) {
//to shard 进行READY状态,即进行迁移准备工作
_state = READY;
//......
//单独起一个线程去负责后续的处理
_migrateThreadHandle = stdx::thread([this]() { _migrateThread(); });
}
void MigrationDestinationManager::_migrateThread() {
_migrateDriver(opCtx.get());
}复制
_migrateDriver()函数真正进行to shard clone数据的若干步骤,包括CLONE、CATCHUP、STEADY、COMMIT_START,一直到DONE。这阶段to shard要创建集合和索引(如果没有),从from shard读数据,insert到本地,同步这期间的写操作等。
void MigrationDestinationManager::_migrateDriver(OperationContext* opCtx) {
{
//to shard开始之后的第一步,下边的函数内包含三个操作:
// 0. Get the collection indexes and options from the donor shard.
//从from shard读取迁移集合的索引信息以及集合的配置项以及uuid信息
// 1. Create the collection (if it doesn't already exist) and create any indexes we are missing (auto-heal indexes).
//如果to shard不存在该集合,则创建该集合;创建to shard上缺失的索引
cloneCollectionIndexesAndOptions(opCtx, _nss, _fromShard);
timing.done(1);
MONGO_FAIL_POINT_PAUSE_WHILE_SET(migrateThreadHangAtStep1);
}
{
// 2. Synchronously delete any data which might have been left orphaned in the range being moved, and wait for completion
//同步删除可能在被移动的范围内被孤立的任何数据,并等待完成
//将“min”和“max”之间的数据块作为数据迁移到其中的一个范围,以保护它不受清理孤立数据的单独命令的影响。但是,首先,它计划删除范围内的任何文档,因此必须在迁移任何新文档之前看到该过程已经完成。
const ChunkRange footprint(_min, _max);
auto notification = _notePending(opCtx, footprint);
// Wait for any other, overlapping queued deletions to drain
auto status = CollectionShardingRuntime::waitForClean(opCtx, _nss, _epoch, footprint);
timing.done(2);
MONGO_FAIL_POINT_PAUSE_WHILE_SET(migrateThreadHangAtStep2);
}
{
// 3. Initial bulk clone
//进入真正的从from shard拷贝数据的阶段
setState(CLONE);
/*在start函数中,会起一个单独的线程去操作迁移过程中的session信息的迁移。包括如下操作:
1. 从from shard获取包含会话信息的oplog。
2. 对于每个oplog条目,如果还没有类型“n”,则转换为类型“n”,同时保留可重试写入所需的所有信息。
3. 还可以为每个oplog条目更新sessionCatalog。
4. 一旦from shard返回一个空的oplog缓冲区,这意味着它应该进入ReadyToCommit状态并等待提交信号(通过调用finish())。
5. 调用finish()后,继续尝试从源碎片获取更多的oplog,直到它再次返回空结果。
6. 等待写入被提交到复制集的大多数。*/
_sessionMigration->start(opCtx->getServiceContext());
//下边的操作是从源端读取迁移chunk里的内容的操作,首先构造“_migrateClone”命令
const BSONObj migrateCloneRequest = createMigrateCloneRequest(_nss, *_sessionId);
_chunkMarkedPending = true; // no lock needed, only the migrate thread looks.
auto assertNotAborted = [&](OperationContext* opCtx) {
opCtx->checkForInterrupt();
uassert(50748, "Migration aborted while copying documents", getState() != ABORT);
};
//处理从from shard读取到的数据插入到本地的回调函数
auto insertBatchFn = [&](OperationContext* opCtx, BSONObj arr) {
int batchNumCloned = 0;
int batchClonedBytes = 0;
assertNotAborted(opCtx);
write_ops::Insert insertOp(_nss);
insertOp.getWriteCommandBase().setOrdered(true);
insertOp.setDocuments([&] {
std::vector<BSONObj> toInsert;
for (const auto& doc : arr) {
BSONObj docToClone = doc.Obj();
toInsert.push_back(docToClone);
batchNumCloned++;
batchClonedBytes += docToClone.objsize();
}
return toInsert;
}());
const WriteResult reply = performInserts(opCtx, insertOp, true);
for (unsigned long i = 0; i < reply.results.size(); ++i) {
uassertStatusOKWithContext(reply.results[i],
str::stream() << "Insert of "
<< redact(insertOp.getDocuments()[i])
<< " failed.");
}
{
stdx::lock_guard<stdx::mutex> statsLock(_mutex);
_numCloned += batchNumCloned;
_clonedBytes += batchClonedBytes;
}
if (_writeConcern.shouldWaitForOtherNodes()) {
repl::ReplicationCoordinator::StatusAndDuration replStatus =
repl::ReplicationCoordinator::get(opCtx)->awaitReplication(
opCtx,
repl::ReplClientInfo::forClient(opCtx->getClient()).getLastOp(),
_writeConcern);
if (replStatus.status.code() == ErrorCodes::WriteConcernFailed) {
warning() << "secondaryThrottle on, but doc insert timed out; "
"continuing";
} else {
uassertStatusOK(replStatus.status);
}
}
};
//对from shard执行“_migrateClone”命令,获取from shard数据
auto fetchBatchFn = [&](OperationContext* opCtx) {
auto res = uassertStatusOKWithContext(
fromShard->runCommand(opCtx,
ReadPreferenceSetting(ReadPreference::PrimaryOnly),
"admin",
migrateCloneRequest,
Shard::RetryPolicy::kIdempotent),
"_migrateClone failed: ");
uassertStatusOKWithContext(Shard::CommandResponse::getEffectiveStatus(res),
"_migrateClone failed: ");
return res.response;
};
//构造一个生产者-消费者的逻辑,通过fetchBatchFn源源不断读取from shard上的数据,然后使用insertBatchFn插入到本地并更新oplog等。直到读取数据完毕。
cloneDocumentsFromDonor(opCtx, insertBatchFn, fetchBatchFn);
timing.done(3);
MONGO_FAIL_POINT_PAUSE_WHILE_SET(migrateThreadHangAtStep3);
}
//进入CATCHUP阶段,向from shard发送“_transferMods”命令,获取在上一步迁移数据过程中,发生的数据删除或更新或插入等写变化,同步过来,并等待修改同步到其他节点
// If running on a replicated system, we'll need to flush the docs we cloned to the secondaries
repl::OpTime lastOpApplied = repl::ReplClientInfo::forClient(opCtx->getClient()).getLastOp();
const BSONObj xferModsRequest = createTransferModsRequest(_nss, *_sessionId);
{
// 4. Do bulk of mods
setState(CATCHUP);
while (true) {
auto res = uassertStatusOKWithContext(
fromShard->runCommand(opCtx,
ReadPreferenceSetting(ReadPreference::PrimaryOnly),
"admin",
xferModsRequest,
Shard::RetryPolicy::kIdempotent),
"_transferMods failed: ");
uassertStatusOKWithContext(Shard::CommandResponse::getEffectiveStatus(res),
"_transferMods failed: ");
const auto& mods = res.response;
if (mods["size"].number() == 0) {
break;
}
//这个函数中,包括对要删除节点的处理,如果有迁移文档被删除,则直接调用删除接口在该shard中删除;如果是insert或update则调用upsert逻辑完成数据更新
_applyMigrateOp(opCtx, mods, &lastOpApplied);
//等待所有修改信息都同步到了secondary节点
}
timing.done(4);
MONGO_FAIL_POINT_PAUSE_WHILE_SET(migrateThreadHangAtStep4);
}
{
// Pause to wait for replication. This will prevent us from going into critical section
// until we're ready.
log() << "Waiting for replication to catch up before entering critical section";
auto awaitReplicationResult = repl::ReplicationCoordinator::get(opCtx)->awaitReplication(
opCtx, lastOpApplied, _writeConcern);
uassertStatusOKWithContext(awaitReplicationResult.status,
awaitReplicationResult.status.codeString());
log() << "Chunk data replicated successfully.";
}
{
// 5. Wait for commit
//进入STEADY状态。进入这个状态之后,from shard在上面介绍过,会一直向to shard发送"_recvChunkStatus"请求,获取to shard的迁移状态,一旦进入了steady阶段,from shard则进入下一步;
//则此时to shard会继续不断读取from shard相关数据在这阶段的或删除或更新或插入的信息,以及等待接收到来自from shard的下一步命令"_recvChunkCommit",to shard收到该命令后,会进行最后一次增量写信息获取和处理,进入COMMIT_START阶段,等待数据同步到大多数节点,迁移结束。
setState(STEADY);
bool transferAfterCommit = false;
//等待to shard接收到"_recvChunkCommit"后,进入COMMIT_START状态
while (getState() == STEADY || getState() == COMMIT_START) {
opCtx->checkForInterrupt();
// Make sure we do at least one transfer after recv'ing the commit message. If we
// aren't sure that at least one transfer happens *after* our state changes to
// COMMIT_START, there could be mods still on the FROM shard that got logged
// *after* our _transferMods but *before* the critical section.
if (getState() == COMMIT_START) {
transferAfterCommit = true;
}
auto res = uassertStatusOKWithContext(
fromShard->runCommand(opCtx,
ReadPreferenceSetting(ReadPreference::PrimaryOnly),
"admin",
xferModsRequest,
Shard::RetryPolicy::kIdempotent),
"_transferMods failed in STEADY STATE: ");
uassertStatusOKWithContext(Shard::CommandResponse::getEffectiveStatus(res),
"_transferMods failed in STEADY STATE: ");
auto mods = res.response;
if (mods["size"].number() > 0 && _applyMigrateOp(opCtx, mods, &lastOpApplied)) {
continue;
}
if (getState() == ABORT) {
log() << "Migration aborted while transferring mods";
return;
}
// We know we're finished when:
// 1) The from side has told us that it has locked writes (COMMIT_START)
// 2) We've checked at least one more time for un-transmitted mods
if (getState() == COMMIT_START && transferAfterCommit == true) {
if (_flushPendingWrites(opCtx, lastOpApplied)) {
break;
}
}
// Only sleep if we aren't committing
if (getState() == STEADY)
sleepmillis(10);
}
if (getState() == FAIL) {
_setStateFail("timed out waiting for commit");
return;
}
timing.done(5);
MONGO_FAIL_POINT_PAUSE_WHILE_SET(migrateThreadHangAtStep5);
}
_sessionMigration->join();
//迁移结束
setState(DONE);
timing.done(6);
MONGO_FAIL_POINT_PAUSE_WHILE_SET(migrateThreadHangAtStep6);
}复制
from shard执行“_migrateClone”命令时,就是讲符合迁移的文档数据插入到返回结果的"objects"中。
class InitialCloneCommand : public BasicCommand {
public:
InitialCloneCommand() : BasicCommand("_migrateClone") {}
bool run(OperationContext* opCtx,
const std::string&,
const BSONObj& cmdObj,
BSONObjBuilder& result) {
while (!arrBuilder || arrBuilder->arrSize() > arrSizeAtPrevIteration) {
AutoGetActiveCloner autoCloner(opCtx, migrationSessionId);
if (!arrBuilder) {
arrBuilder.emplace(autoCloner.getCloner()->getCloneBatchBufferAllocationSize());
}
arrSizeAtPrevIteration = arrBuilder->arrSize();
uassertStatusOK(autoCloner.getCloner()->nextCloneBatch(
opCtx, autoCloner.getColl(), arrBuilder.get_ptr()));
}
invariant(arrBuilder);
result.appendArray("objects", arrBuilder->arr());
}复制
from shard执行"_transferMods"命令的时候,将迁移过程中,from shard的有写操作的文档的或删除或更新或插入信息返回给to shard。
class TransferModsCommand : public BasicCommand {
public:
TransferModsCommand() : BasicCommand("_transferMods") {}
bool run(OperationContext* opCtx,
const std::string&,
const BSONObj& cmdObj,
BSONObjBuilder& result) {
const MigrationSessionId migrationSessionId(
uassertStatusOK(MigrationSessionId::extractFromBSON(cmdObj)));
AutoGetActiveCloner autoCloner(opCtx, migrationSessionId);
uassertStatusOK(autoCloner.getCloner()->nextModsBatch(opCtx, autoCloner.getDb(), &result));
return true;
}复制
from shard是通过两个list列表"deleted"和"reload"来保存迁移过程中,哪些文档有或删除或更新或插入的操作,nextModsBatch即从这两个列表中获得对应文档。
Status MigrationChunkClonerSourceLegacy::nextModsBatch(OperationContext* opCtx,
Database* db,
BSONObjBuilder* builder) {
dassert(opCtx->lockState()->isCollectionLockedForMode(_args.getNss().ns(), MODE_IS));
stdx::lock_guard<stdx::mutex> sl(_mutex);
// All clone data must have been drained before starting to fetch the incremental changes
invariant(_cloneLocs.empty());
long long docSizeAccumulator = 0;
//_xfer函数会将需要删除数据的"_id"信息返回即可;而更新或插入的文档则是把整个文档信息返回,在to shard上执行upsert,完整数据更新
_xfer(opCtx, db, &_deleted, builder, "deleted", &docSizeAccumulator, false);
_xfer(opCtx, db, &_reload, builder, "reload", &docSizeAccumulator, true);
builder->append("size", docSizeAccumulator);
return Status::OK();
}复制
而from shard是通过如下接口完成对这些文档修改的保存的。以update的数据作为例子。
当有数据更新到该shard的时候,首先判断该数据是否来自于其他shard的迁移数据,如果是,则不记录;如果不是,则进一步判断当前是否在当前迁移任务的chunk范围内,如果是,则保存到"reload"中。
void MigrationChunkClonerSourceLegacy::onUpdateOp(OperationContext* opCtx,
const BSONObj& updatedDoc,
const repl::OpTime& opTime,
const repl::OpTime& prePostImageOpTime) {
dassert(opCtx->lockState()->isCollectionLockedForMode(_args.getNss().ns(), MODE_IX));
BSONElement idElement = updatedDoc["_id"];
if (idElement.eoo()) {
warning() << "logUpdateOp got a document with no _id field, ignoring updatedDoc: "
<< redact(updatedDoc);
return;
}
if (!isInRange(updatedDoc, _args.getMinKey(), _args.getMaxKey(), _shardKeyPattern)) {
return;
}
if (opCtx->getTxnNumber()) {
opCtx->recoveryUnit()->registerChange(
new LogOpForShardingHandler(this, idElement.wrap(), 'u', opTime, prePostImageOpTime));
} else {
opCtx->recoveryUnit()->registerChange(
new LogOpForShardingHandler(this, idElement.wrap(), 'u', {}, {}));
}
}
class LogOpForShardingHandler final : public RecoveryUnit::Change {
void commit(boost::optional<Timestamp>) override {
switch (_op) {
case 'd': {
stdx::lock_guard<stdx::mutex> sl(_cloner->_mutex);
_cloner->_deleted.push_back(_idObj);
_cloner->_memoryUsed += _idObj.firstElement().size() + 5;
} break;
case 'i':
case 'u': {
stdx::lock_guard<stdx::mutex> sl(_cloner->_mutex);
_cloner->_reload.push_back(_idObj);
_cloner->_memoryUsed += _idObj.firstElement().size() + 5;
} break;
default:
MONGO_UNREACHABLE;
}
if (auto sessionSource = _cloner->_sessionCatalogSource.get()) {
if (!_prePostImageOpTime.isNull()) {
sessionSource->notifyNewWriteOpTime(_prePostImageOpTime);
}
if (!_opTime.isNull()) {
sessionSource->notifyNewWriteOpTime(_opTime);
}
}
}
}复制
收到"_recvChunkCommit"命令后,表明to shard可以进行最后的迁移结果提交了。
class RecvChunkCommitCommand : public BasicCommand {
public:
RecvChunkCommitCommand() : BasicCommand("_recvChunkCommit") {}
bool run(OperationContext* opCtx,
const std::string& dbname,
const BSONObj& cmdObj,
BSONObjBuilder& result) override {
auto const sessionId = uassertStatusOK(MigrationSessionId::extractFromBSON(cmdObj));
auto const mdm = MigrationDestinationManager::get(opCtx);
Status const status = mdm->startCommit(sessionId);
mdm->report(result, opCtx, false);
if (!status.isOK()) {
log() << status.reason();
uassertStatusOK(status);
}
return true;
}
}
Status MigrationDestinationManager::startCommit(const MigrationSessionId& sessionId) {
_sessionMigration->finish();
_state = COMMIT_START;
_stateChangedCV.notify_all();
}复制
至此,to shard的操作结束,可以接收来自用户对迁移的数据的读写请求了。
未完,待续
参考文档
MongoDB官方文档
孤儿文档是怎样产生的(MongoDB orphaned document)

