









本期内容
select语句在 TiDB Server层
所经历的过程
相信我们平时接触数据库,对于select语句那是再熟悉不过了。就比如像下面的这条语句:
这条语句就是一条普通的查询语句,那当我们放到数据库执行的时候,它又经历了怎样的过程的,接下来就让我们看一下,一条select语句在TiDB Server层都发生了什么。
什么是TiDB数据库
TiDB数据库由 PD + TiDB Server + TiKV 组成。
PD :主要负责集群整体拓扑结构的存储、分配全局 ID 和事务 ID、生成全局 TSO 时间戳、收集集群信息进行调度、提供 TiDB Dashboard 服务;
TiDB Server:主要负责客户端的连接(MySQL 协议)、SQL 语句析、编译、数据转化、SQL 语执行、在线 DDL 语句/GC;
TiKV:主要负责数据持久化、分布式事务支持、副本的强一致性和高可用性、MVCC、Coprocessor(协同处理器);
本期我们主要介绍的是Select 语句在TiDB Server层都有哪些操作,接下来先让我们看一下 TiDB Server 的架构:
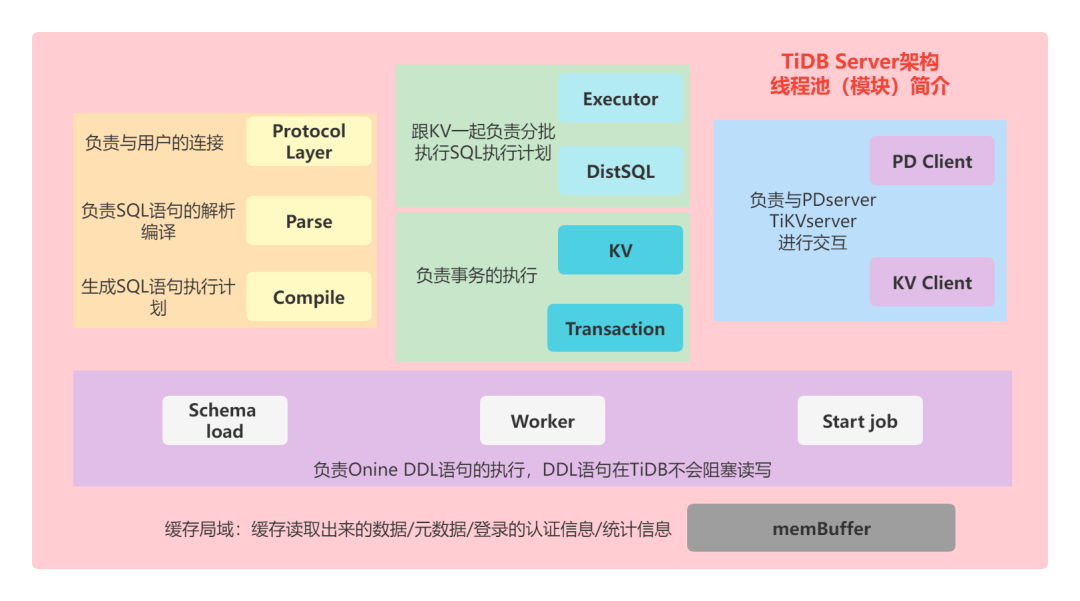
可以看到,我们的TiDB Server主要由各个模块组成,每一块的功能各不相同,结合图片与介绍,我们可以大致的对TiDB各个模块的功能有一个认知,接下来就根据select语句的执行流程,来看一看每一个模块的作用。
流程解析
# 1 Protocol Layer模块
如果我们在 Linux 操作系统上连接TiDB服务,因为是兼容mysql的,所以我们只需要执行mysql的连接命令,即可连接进入数据库当中,这样我们才可以执行sql语句,普遍方式如下:

连接的时候,会需要经过TCP的三次握手,如果我们的服务并没有启动的话,则会收到如下报错:

当建立完TCP的连接后,我们的数据库就会先对用户与密码进行判断,如果用户和密码不对。就会收到"Access denied for user"的报错,然后结束执行。

如果账号密码没有问题,那我们就成功的进入到了数据库内。
在数据库内,我们的操作基于之前获取的用户权限来进行,如果在此时管理员修改了该用户的权限,因为我们已经记录了所需权限,所以不会有问题,而是在我们重新建立连接后,权限才会进行刷新。
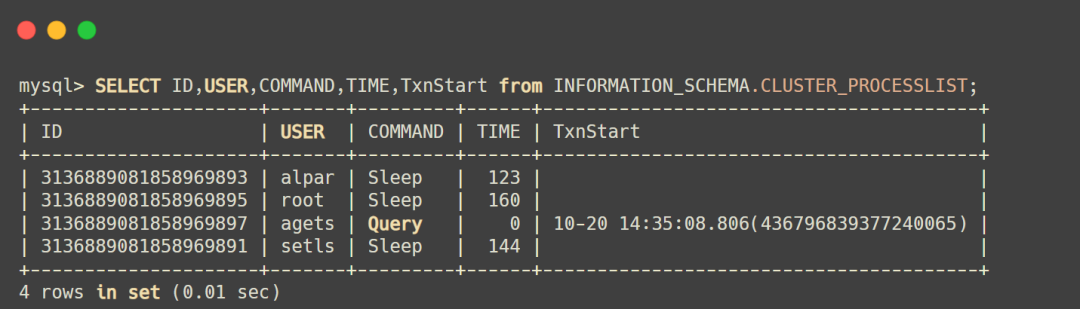
建立连接后,如果想要知道我们的数据库有多少个连接,由于TiDB是分布式数据库,所以我们可以通过自带的INFORMATION\_SCHEMA下面的cluster\_processlist查看到连接信息。
# 2 Parse模块
在正式执行 SQL 查询语句之前,TiDB会先对 SQL 语句进行解析编译,Parse主要负责解析 SQL 语句。
当我们连接数据库后执行一条select语句,该模块会首先接收到,并将其进行一个词法分析(lex)+ 语法分析(yacc)。
它们的操作会将我们的查询语句进行分析,判断是否符合TiDB的语法,如果我们输入的语句通过判断,并不符合TiDB的语法则会报错,如下图一样:

并且经过的时候会生成一个AST抽象语法数,类似如下这张图:
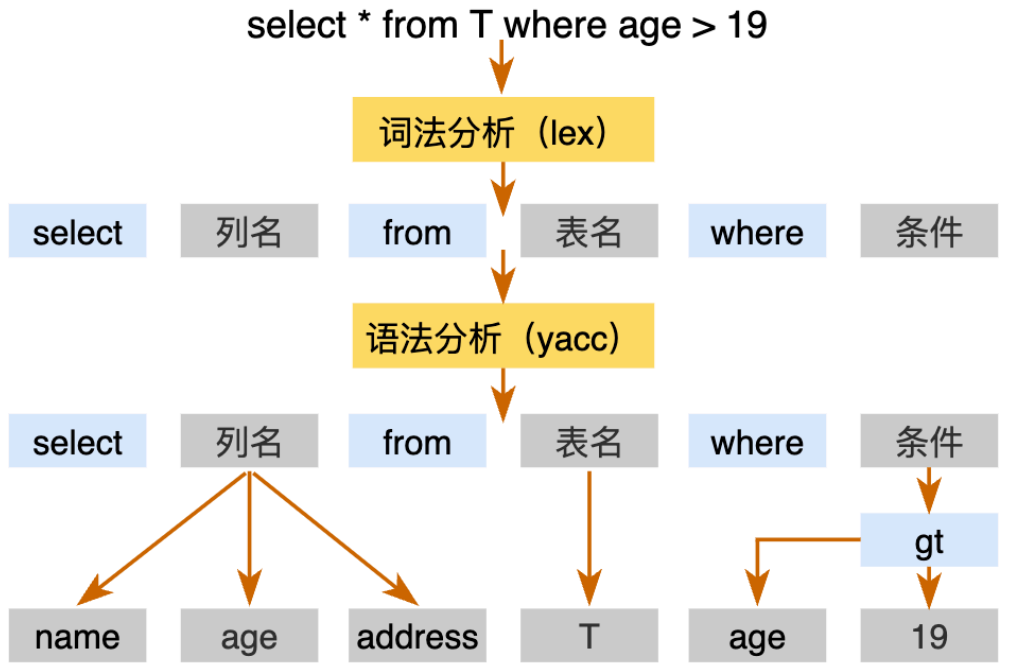
这里值得注意的是,语法分析只是判断是否符合TiDB的语法,并不会针对于表是否存在,库是否存在这些进行判断。这些判断是由compile模块来进行的。
# 3 Compile模块
我们的查询语句通过 Parse模块产生AST抽象语法树以后,就会到达Compile模块。
首先,该模块会对查询语句进行合法性验证,判断是否上述说的一些类似于库/表是否存在等,如下:

在合法性验证结束后,会对语句进行逻辑优化+物理优化。
逻辑优化的意思就是说,会根据SQL层面的操作进行相关的优化;物理优化就是针对于数据的分布、数据的大小来决定我们的执行方式。
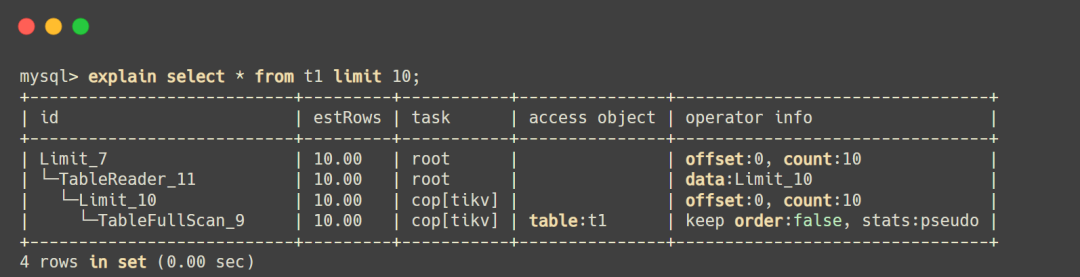
当我们的查询语句经历逻辑+物理优化后,就会生产执行计划,我们也可以通过explain sql语句进行查看,来判断是否走到了预期的效果,如下:
# 4 Executor模块
通过 Compile 模块后,就会来到 Executor 模块,该模块会对我们的 SQL 语句进行判断。
这个判断的意思就是说它会将我们的语句进行分辨,分辨是点查还是复杂SQL,这时候就会产生两种情况。
当 Executor 模块判断执行SQL是点查时,则会交给KV模块来进行,KV模块会通过TiKV Client 模块来跟 TiKV 建立连接,从 RocksDB-KV 当中获取数据;
当 Executor 模块判断执行SQL是复杂SQL时,则会交给 DistSQL 模块,DistSQL模块会将复杂SQL进行拆分,分解成多个单表查询操作,然后在通过TiKV Client模块跟TiKV建立连接从RocksDB-KV当中获取数据。
值得注意的是,TiDB的数据是转换为 Key-Value 形式来进行存储的,并且是在 TiDB Server 层来进行的。在 Executor 当中就会有一个将关系型数据转换为 Key-Value 的过程。
# 5 获取TSO
在我们执行语句的过程中TiDB Server会先去PD获取 start.ts 与 commit.ts ,这里呢会将获取分为6步来完成,如下:
1、TSO 请求者先向 TiDB Server 实例的 PD Client 模块发送请求TSO;
2、PD Client 将收到的 TSO 请求转发给 PD Leader节点;
3、PD 接收到了PD Client发送的TSO请求后,因为无法立刻分配 TSO。于是,会先为 PD Client 返回一个异步对象 tsFuture,证明自己已收到请求,这个 tsFuture 你先收下,待会儿你在通过这个 tsFuture 来领取属于你的TSO;
4、PD Client 会将 PD 分配的 tsFuture 转发给 TSO 请求者,TSO 请求者收到后,会将 tsFuture 存储起来;
5、PD 为 TSO 请求者分配 TSO(TSO 中会携带 tsFuture 信息),PD Client 会将PD分配的 TSO 转交给 TSO 请求者;
6、TSO 请求者接收到 PD Client 发送过来的 TSO 后,会将其中携带的 tsFuture 信息与自己收到的 tsFuture 相比对,确定是分配给自己的 TSO;
# 6 获取Region位置信息
TiDB是一个分布式的数据库,PD充当了一个类似于大脑的角色,我们的查询语句,需要知道数据存放在哪,就需要通过PD来获得路由信息,然后才将请求发送给TiKV。
为了防止过于频繁的请求PD造成性能问题,TiDB Server会通过缓存机制来解决此类问题,获取Region位置信息的流程如下:
1、TiDB Server 会先去访问本地的缓存,查看是否有相应的路由信息;
2、两种情况,一种是有路由信息,那 TiDB Server 就会根据新的路由信息将请求发送给TiKV,另一种情况就是当缓存中没有相关的路由信息时候,就会去PD进行获取,在通过返回的路由信息将请求发送给TiKV;
3、如果,请求发送到 follower 角色了,TiKV 会返回 not leader 的错误,并把谁是 leader 的信息返回给 TiDB Server,然后 TiDB Server 更新缓存信息。
# 7 返回数据
当我们从 TiKV 当中获取到所要查询数据后,会通过 Executo r模块,再通过 Protocol Laye r模块返回给用户。
当返回给用户后后,会有一个加入缓存的操作,因为其有上述说的缓存机制,至此一个 select 的查询语句的全部流程就结束了。
总结
以上就是 select语句在TiDB Server层所经历的过程,值得注意的是,我们的TiDB还有1个设定就是 TiKV 的 Coprocessor:
TiKV 的 Coprocessor 又名协同处理器,它会帮助TiDB将运算下推到TiKV当中进行,也就是说,当 TiKV 收到协同处理的请求后,会根据算子、数据进行过滤、聚合操作,这样TiDB在收到数据之后,在进行二次处理则会得出结果,大大的减轻了TiDB的压力。


以上就是关于select语句
在TiDB Server层所经历的过程
如果你对此内容感兴趣或有疑问
欢迎扫码入群一同探讨~
本期作者
付家明

更多精彩内容



了解云基地,就现在!
IT技术哪家强
神州数码最在行
行业新星,后起之秀
历史虽不长,但是实 力 强














